I figured it out (almost everything).
- When you create a model inside a separate process with
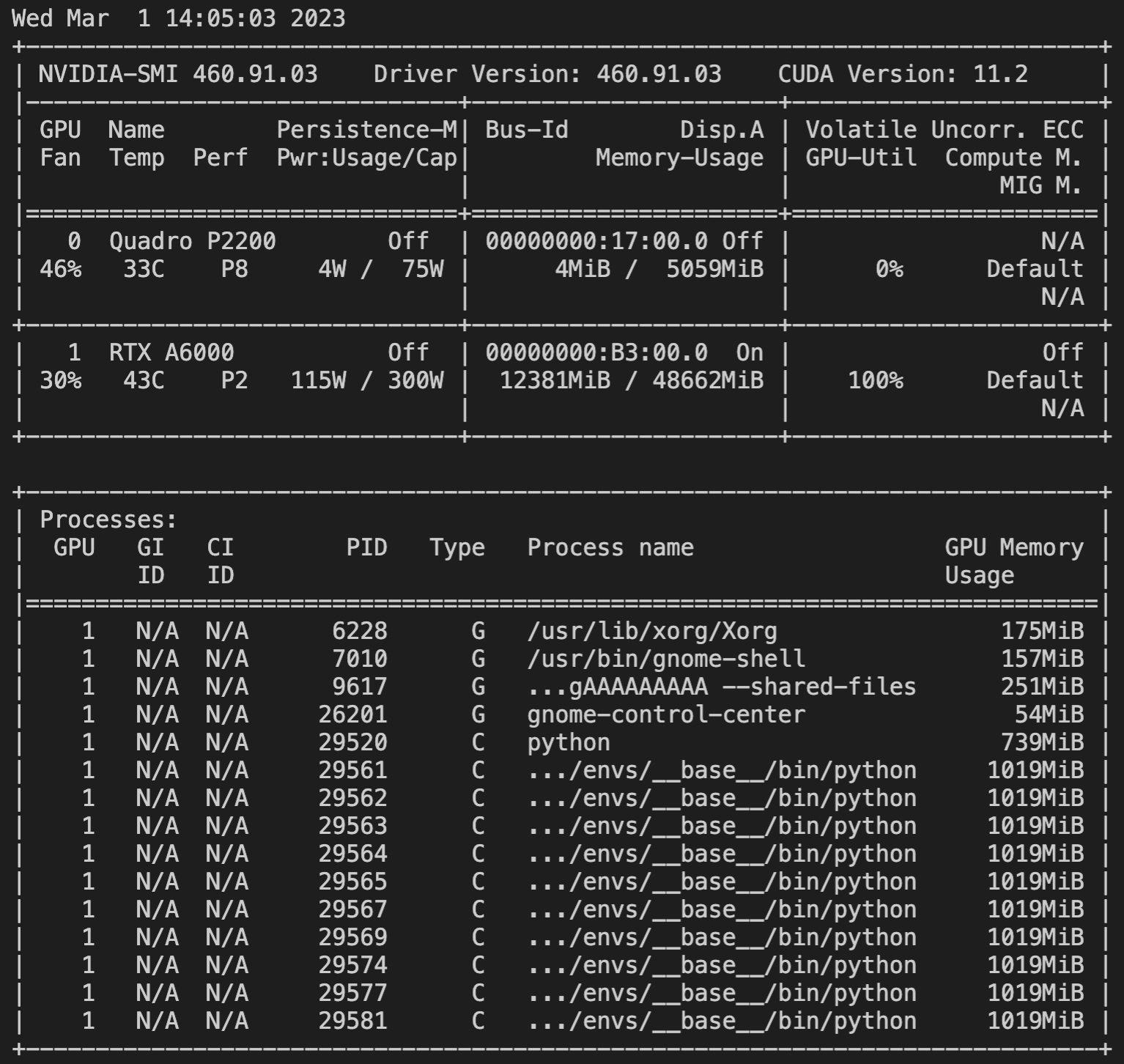
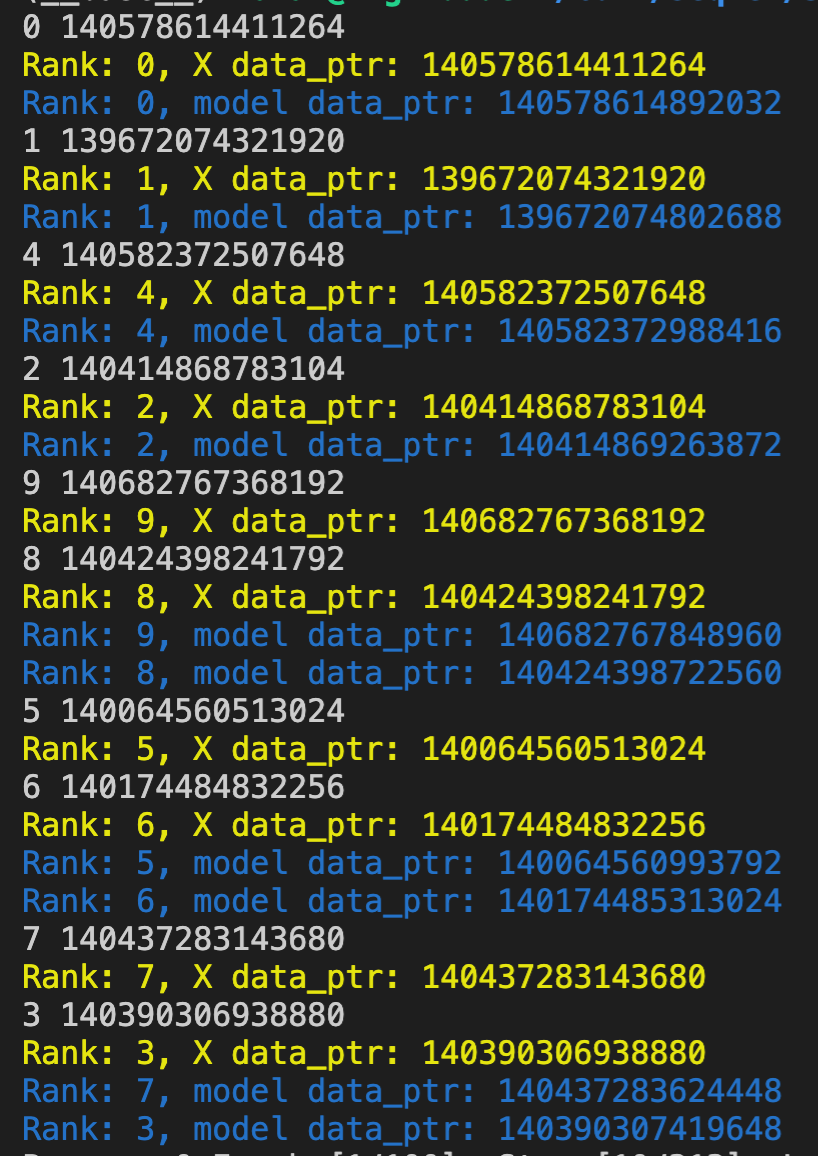
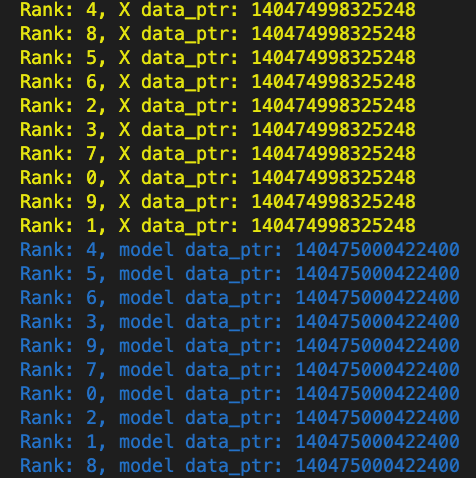
torch.multiprocessing, the parameters of the model would have the same pointers, because the pointers are apparently not global, but are relative to the process’s memory space. In the example below, I tampered with the weights from Process 0 and the weights were not changed in the other processes (I checked Process 8). As an additional check, I tried passing another shared tensor (shared_bias) to each process. In that case, if I tamper with this shared bias, the change will be reflected in all of the subprocesses (and that is intended). So everything checks out: you CAN share CUDA tensors (e.g. datasets) across processes, each of which running a different model. Moreover, it is possible to share some of the models’ parameters across the processes. My confusion was with the pointers of the model weight tensors: now I realize that the same pointers in different processes don’t mean the same underlying data.
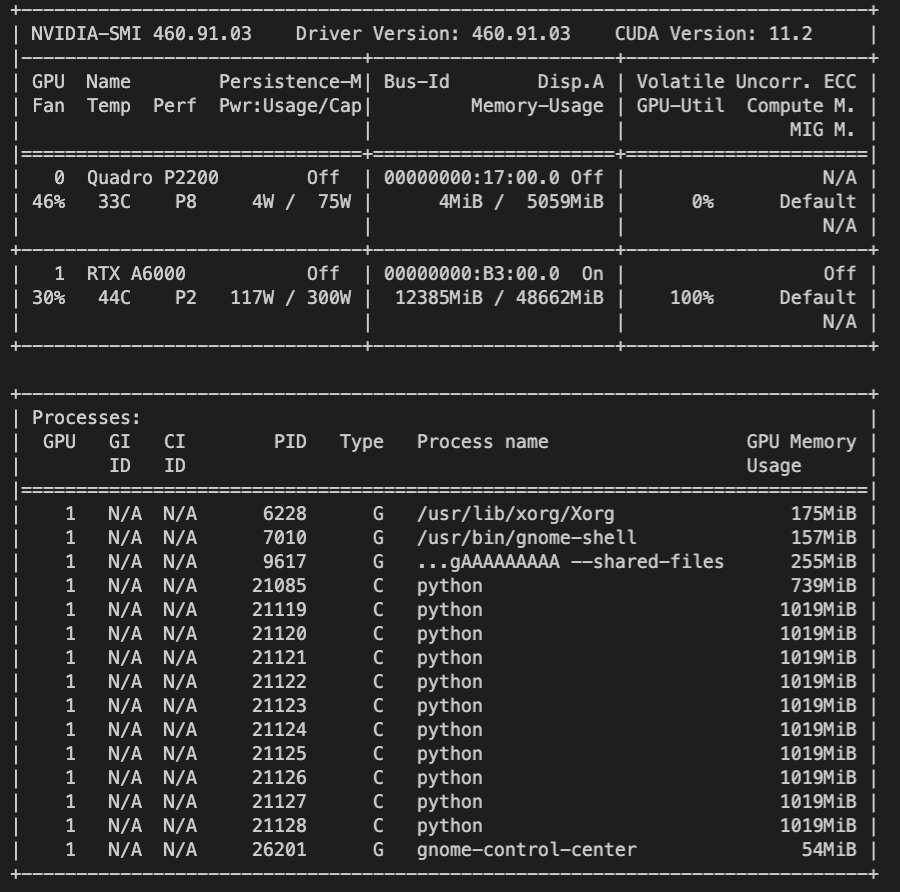
One remaining concern is that a small model inside each process allocates 1 GB of GPU memory. I thought that I would be able to train hundreds of small models on one GPU in parallel, but now that seems impossible (or is it? @ptrblck ).
Below is the complete code snippet to reproduce:
import torch, time, sys, os, copy
os.environ['CUDA_LAUNCH_BLOCKING'] = '1'
sys.path.append('../')
import torch
import torch.multiprocessing as mp
from torch.utils.data import DataLoader, TensorDataset
from termcolor import cprint
# Spawn a separate process for each copy of the model
# mp.set_start_method('spawn') # must be not fork, but spawn
queue = mp.Queue()
# Define your model
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc1 = torch.nn.Linear(10, 10)
self.relu = torch.nn.ReLU()
self.fc2 = torch.nn.Linear(10, 2)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# Define a function to train a single copy of the model
def train_model(rank, queue, DEVICE):
# Set the random seed for reproducibility
torch.manual_seed(rank)
X, y, bias = queue.get()
cprint(f'Rank: {rank}, X data_ptr: {X.data_ptr()}', color='yellow')
# Load your dataset
dataset = TensorDataset(
X,
y,
)
# Set the device to the current process's device
with torch.no_grad():
model = MyModel().to(DEVICE)
model.fc1.bias = torch.nn.Parameter(bias)
if rank == 0:
# changing weight in one model in a separate process doesn't affect the weights in the model in another process, because the weight tensors are not shared
model.fc1.weight[0][0] = -33.0
# but changing bias (which is a shared tensor) should affect biases in the other processes
model.fc1.bias *= 4
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='magenta')
if rank == 8:
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='red')
cprint(f'RANK: {rank} | BIAS: {model.fc1.bias}', color='red')
ptr = model.fc1.weight[0][0].storage().data_ptr()
cprint(f'Rank: {rank}, model data_ptr: {ptr}', color='blue')
# Create a DataLoader for your dataset
dataloader = DataLoader(dataset, batch_size=32, shuffle=False)
# Define the loss function and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# Train the model
for epoch in range(100):
for i, (inputs, labels) in enumerate(dataloader):
if rank == 0:
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='magenta')
cprint(f'RANK: {rank} | BIAS: {model.fc1.bias}', color='magenta')
if rank == 8:
cprint(f'RANK: {rank} | {list(model.parameters())[0][0,0]}', color='red')
cprint(f'RANK: {rank} | BIAS: {model.fc1.bias}', color='red')
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
# optimizer.step()
if (i + 1) % 10 == 0:
print(
f"Process {rank} Epoch [{epoch + 1}/{100}], Step [{i + 1}/{len(dataloader)}], Loss: {loss.item():.4f}"
)
cprint(f'{rank} finished!', color='yellow')
NUM_MODEL_COPIES = 10
DEVICE = 'cuda:0'
processes = []
for rank in range(NUM_MODEL_COPIES):
process = mp.Process(target=train_model, args=(rank, queue, DEVICE))
process.start()
processes.append(process)
time.sleep(2)
X = torch.rand(size=(10000, 10)).to(DEVICE)
y = torch.randint(2, size=(10000,)).to(DEVICE)
shared_bias = torch.ones(size=(10,), device=DEVICE)
for rank in range(NUM_MODEL_COPIES):
queue.put((X, y, shared_bias))
# Wait for all processes to finish
for process in processes:
process.join()