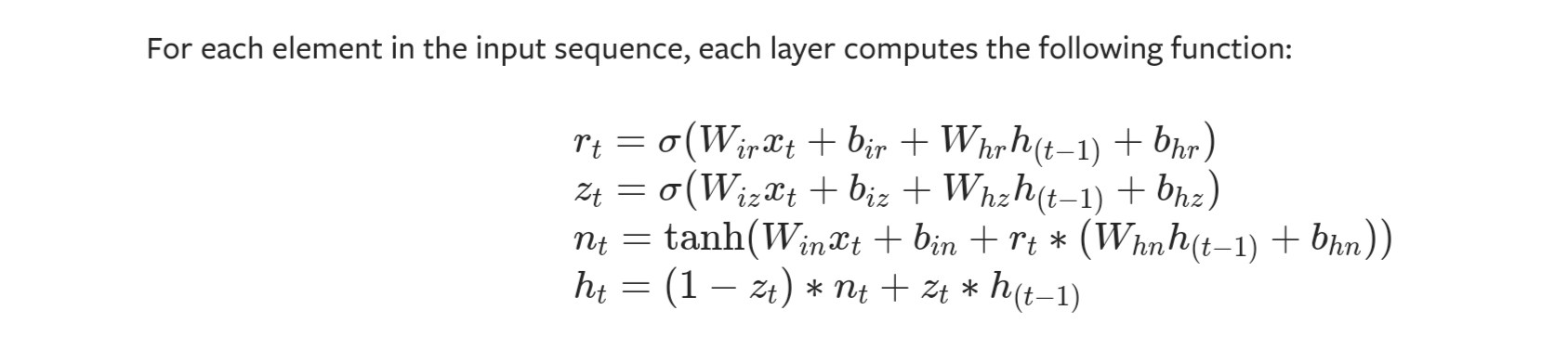You can think of the above as one building block, with additional GRU layers just repeating the same gated algorithm. So whether you want to give each a different label, or put them all under one label, is a matter of preference. The math works out the same.
I could see there being a benefit to splitting it up for very large models, as it’s much easier to assign each “layer” to different GPUs/TPUs during initialization and training. If you put them all in one nn.GRU unit, it’s going to take a lot more code and effort to assign each layer to separate GPUs.
Thanks.
If we use 2 GRU the H0 of the second GRU may be initialised with zeros (or different values) (instead of getting the last hidden state of the first GRU),
while using 1 GRU with multiple layers, the hidden state passed to the next layer, across all layers.
Is that something that can change the results dramatically ?
Right, it would change the result. You would need to keep track of 2 hidden states. One for each separate unit. Notice how the hidden state contains the number of layers in the dims:
If you set the hidden state to zeros for the second layer, it would no longer be the equivalent of using multiple layers in one GRU. It would be the same as if you used one GRU and set half of the hidden state to zeros.