I found a problem that when I trained with a big dataset(same pictures size. same pre-process, only difference is that there are more pictures), even I set the same batch size and run iterations of dataloader witouht model training, the dataloader of a small dataset can provide data much faster(about 20 batches per second) while the dataloader of a big dataset can only provide 1batches per second.
I ran some experiments about this issues and found that after I roboot the server, I run 10 epoch of iterations of dataloader of the small dataset, the first epoch is also slow(about 1 batch per second). The next 9 epoch is really fast(about 20 batches per second).
I assume there is some data cache when we use the dataloader. However this cache seems to be useless for the dataloader with a big dataset(130G,1.2million images) because after the first epoch, the speeed of the iterations of dataloader is still slow.
Why is it happen? How can I solve this problem? Please help me.
The iterations of the dataloader with a big dataset:
dataset: 130G 1.2million images
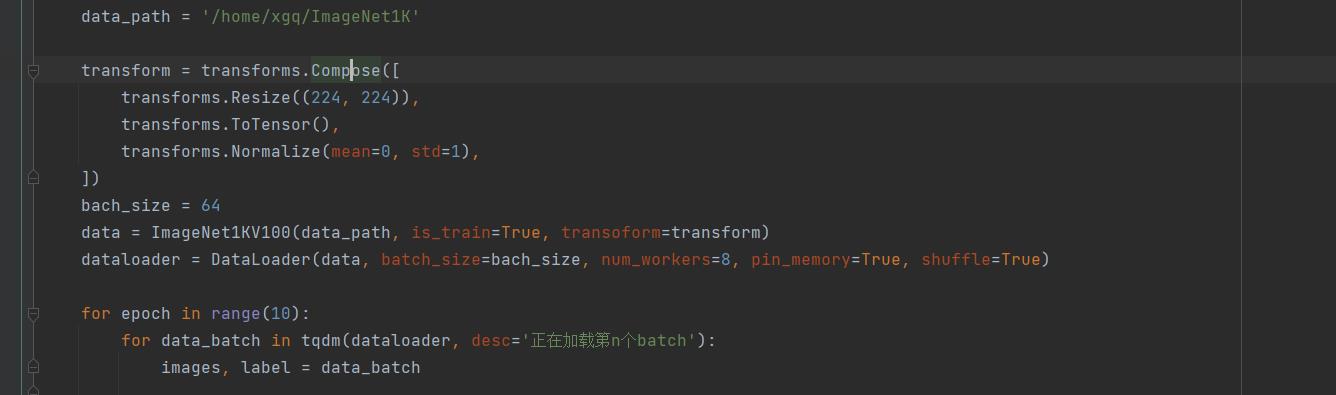
The iterations of the dataloader with a big dataset:
dataset: 13G 120,000 images
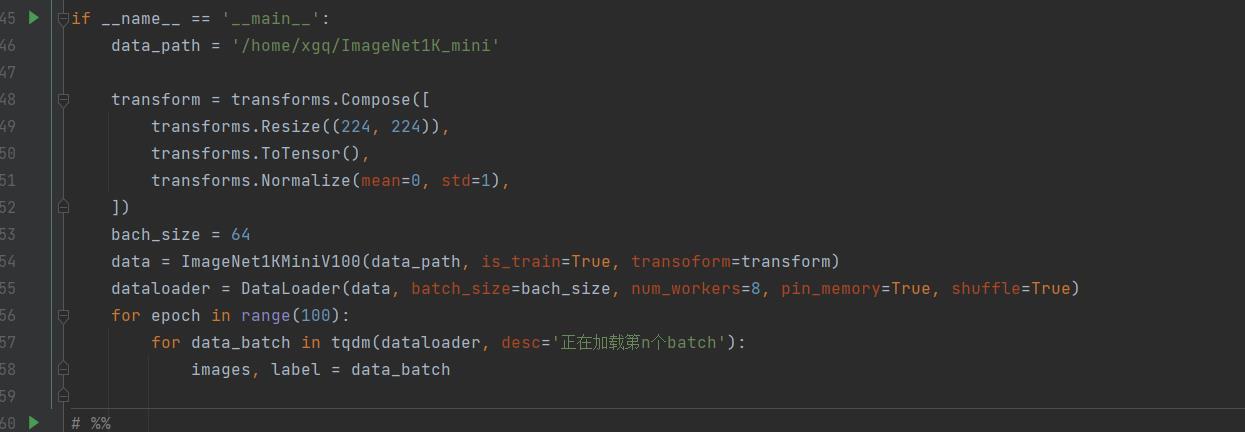
Two dataset are similar, so two custom dataset class are similar.