Hello, everyone!
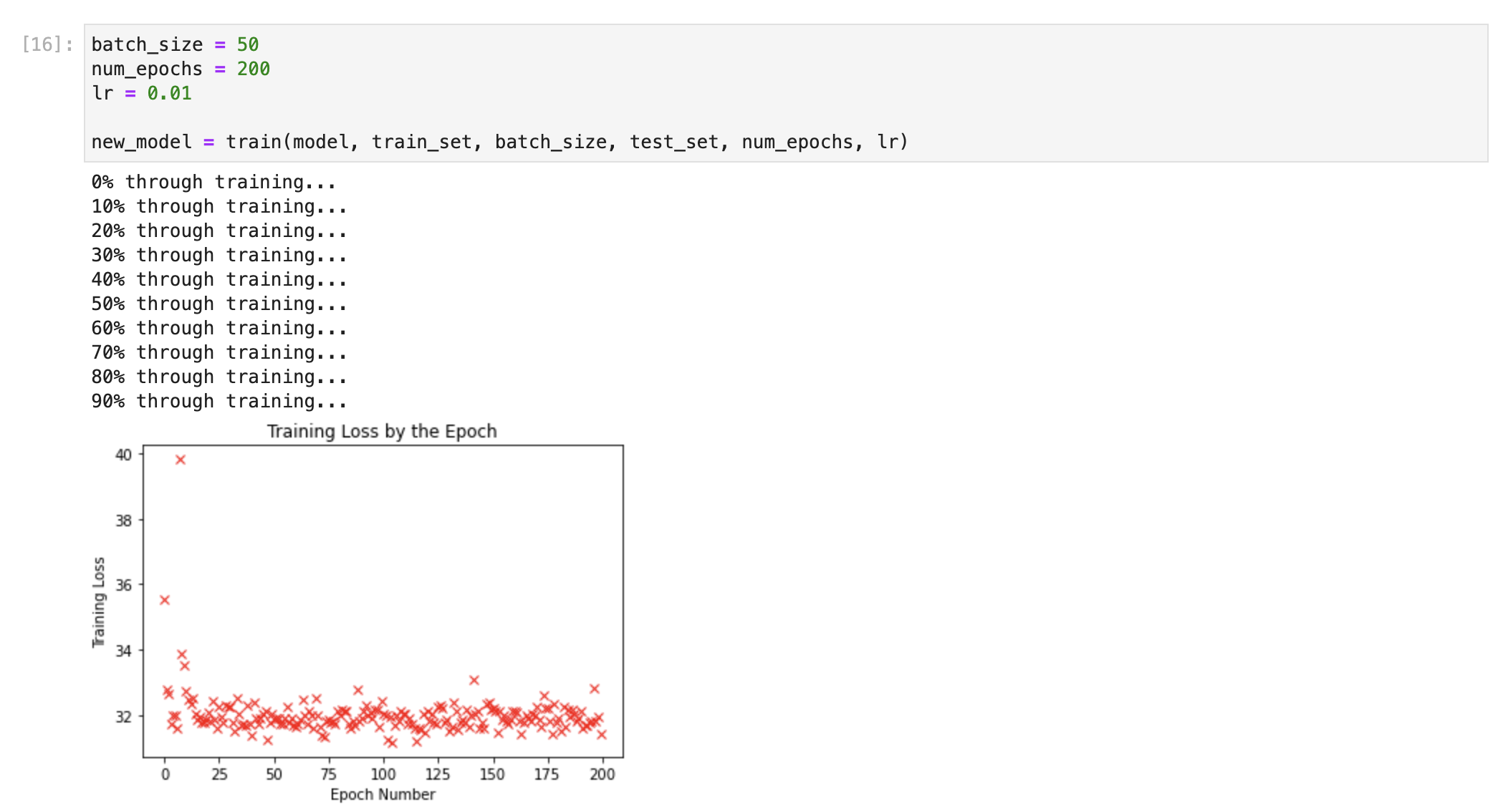
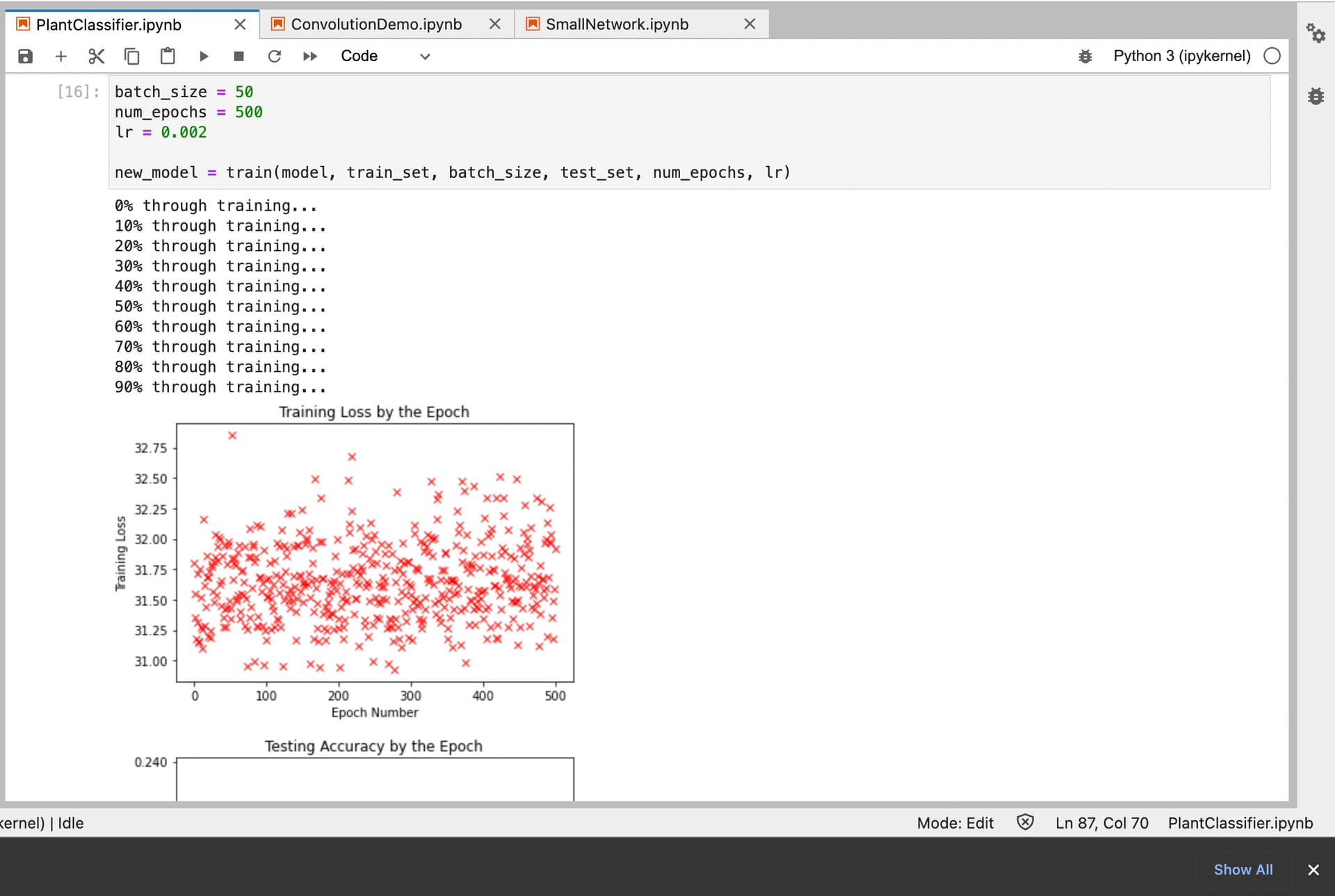
So I am currently working on creating a neural network which I hope to train to classify ten different types of plant pictures, which I took, cropped, and compressed myself. Everything in the code physically works, but I just cannot seem to get the network to reach any reasonable degree of accuracy. Any recommendations on my hyper parameters? Number of convolutions, layers, sizes, etc.? Should I use dropout? Batch normalization? How many epochs of training, and what learning rate? Adam optimization, or just regular gradient descent? Are my images simply too big and there’s no hope? Thanks! Attached is an example of one of my images - they are all colored, 1000x1000, and I have around 800 of them. I’d appreciate any tips people could give me! Attached is a screenshot of the results of the most recent training (which took my computer all day since I do not have a GPU ![]() ). It’s not pretty… any tips anyone has would be much appreciated!
). It’s not pretty… any tips anyone has would be much appreciated!
Here’s an example of one of my images:

Also, once again everything in my code does physically work. But you all may have some suggestions on my network hyper parameters, so I’ll just include my code for my CNN class below:
class CNN(nn.Module):
def __init__(self, layers=[100,50,10], convolutions=[(3,5,1,4),(1, 5, 1, 4),(1, 5, 1, None)]):
super(CNN, self).__init__()
# so that we can now call neural network modules
self.initialized = False
self.dims = layers
self.convs = []
for index, convolution in enumerate(convolutions):
if index > 0:
assert convolutions[index-1][2] == convolutions[index][0], f"Invalid input and output channel matching at convolutions {index-1} and {index}."
if convolution[3] != None:
conv_pair = (nn.Conv2d(in_channels=convolution[0], out_channels=convolution[2], kernel_size=convolution[1]), nn.MaxPool2d(convolution[3]))
else:
conv_pair = (nn.Conv2d(in_channels=convolution[0], out_channels=convolution[2], kernel_size=convolution[1]), None)
self.convs.append(conv_pair)
# all of the convolutions that go at the start of our network
self.linears = nn.ModuleList()
for this_dim, next_dim in zip(layers, layers[1:]):
self.linears.append(nn.Linear(this_dim, next_dim))
# all of the weights and biases
self.binary = layers[-1]==1
# binary or multiclass output?
def forward(self, x):
x = x.type(torch.FloatTensor)
# convert x to float
for conv in self.convs:
convolution = conv[0]
maxpool = conv[1]
x = convolution(x)
if maxpool != None:
x = maxpool(x)
# run all of the convolution on x
# now we need to reshape x into one vector
num_pixels = 1
for num in x.shape[1:]:
# I don't care about the NUMBER of images; only the number of pixels PER image
num_pixels *= num
x = x.view(-1, num_pixels)
# roll out into one vector
if not self.initialized:
# then we need to get PyTorch to count the dimensions
if self.dims[0] != x.shape[-1]:
# then we need to create a linear function to force the fit
new_linear = nn.Linear(x.shape[-1], self.dims[0])
self.linears.insert(0, new_linear)
self.initialized = True
# now we ARE initialized - the network has seen some images
for index, linear in enumerate(self.linears):
if index == len(self.linears) - 1:
# we ARE on the last layer
if self.binary:
x = sigmoid(linear(x))
# run the linear function and apply sigmoid for the binary output
else:
x = linear(x)
# otherwise for multi-class there is no activation on the output layer
else:
# we are NOT on the last layer
x = relu(linear(x))
# apply relu activation
return x
# return x
def show_progression(self, x):
# visually show the feedforward behavior of our network
assert len(x.shape)==4 and x.shape[0]==1, "show_progression method will only deal with one image at once - if you think you only have one, wrap it in an outer tensor."
assert self.initialized, "Network has not yet seen any images."
print('Original Image:')
plt.imshow(x[0].permute(1, 2, 0))
plt.show()
print(x.shape)
# show the image
x = x.type(torch.FloatTensor)
# convert x to float
for index, conv in enumerate(self.convs):
print('\n')
print(f'Convolution {index}:')
convolution = conv[0]
x = convolution(x)
# show the image
permuted = x.permute(1,0,2,3)
# turn it into the dimensions necessary in order to show the image via matplotlib.pyplot
for i in range(permuted.shape[0]):
# sort of think of this as how many 'colors'/output channels
plt.imshow(permuted.detach()[i].permute(1,2,0))
plt.show()
print(x.shape)
print('\n')
maxpool = conv[1]
if maxpool != None:
x = maxpool(x)
permuted = x.permute(1,0,2,3)
# turn it into the dimensions necessary in order to show the image via matplotlib.pyplot
print(f'Max Pool {index}:')
for i in range(permuted.shape[0]):
# sort of think of this as how many 'colors'/output channels
plt.imshow(permuted.detach()[i].permute(1,2,0))
plt.show()
print(x.shape)
print('\n')
# run all of the convolutions and maxpools on x
# now we need to reshape x into one vector
num_pixels = 1
for num in x.shape[1:]:
# I don't care about the NUMBER of images; only the number of pixels PER image
num_pixels *= num
x = x.view(x.shape[0], num_pixels)
# roll out into one vector (or a collection of vectors if multiple images)
print('Unrolled Vector:')
print(x.shape)
if not self.initialized:
# then we need to get PyTorch to count the dimensions
if self.dims[0] != x.shape[-1]:
# then we need to create a linear function to force the fit
new_linear = nn.Linear(x.shape[-1], self.dims[0])
self.linears.insert(0, new_linear)
self.initialized = True
# now we ARE initialized - the network has seen some images
for index, linear in enumerate(self.linears):
if index == len(self.linears) - 1:
# we ARE on the last layer
if self.binary:
x = sigmoid(linear(x))
# run the linear function and apply sigmoid for the binary output
else:
x = linear(x)
# otherwise for multi-class there is no activation on the output layer
else:
# we are NOT on the last layer
x = relu(linear(x))
# apply relu activation
print('\n')
print(f'Hidden Layer {index}:')
print(x.detach().tolist())
print(x.shape)
Thanks again everyone!