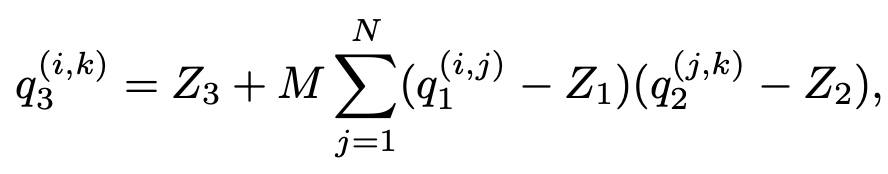Hi there,
I’m new to here.
During quantization, we’ll calculate scale and zero_point and follow the above formula while performing inference. In my project, I need to avoid that zero_point subtraction.
I know my issue is similar to symmetric quantization. But I don’t know how to implement it on Pytorch.
I’ve tried using Pytorch quantization API, and there seems to be no function that meets my requirement. I’ve tried using qscheme=torch.per_tensor_symmetric, and set dtype=qint8.
However, during inference, the model couldn’t work. Since the activations need to be quint8, while I’ve set it to qint8 to make zero_point=0.
Besides, I’ve also implemented QAT from scratch without using quantization API, and manully setting zero_poinrt=0, but the performance dropped a lot, and I don’t know where was wrong.
Could any one give me some suggestion? Thanks a lot! 
1 Like
dtype=qint8 for activation is currently not supported in the native backend (server and mobile cpu) of pytorch. Could you specify which bakcend/device (server cpu/mobile cpu/cuda etc.) are you targeting?
For the QAT question, are you setting zero_point to 0 after training? I don’t think we can do that
1 Like
Hi,
None of these backend are my targets. I need to implement the neural network on chip, so Multiply-Add operation only is preferred. Subtraction operation may be a burden for me.
For QAT, I think I’m just performing symmetric quantization, mapping floating point value to -128~127, where setting z=0 is okay.
When there’s ReLU, FakeQuantize floating point to 0~255.
When there’s no ReLU, FakeQuantize floating point to -128-127.
(FakeQuantize = quantize then dequantize)
My QAT work from scratch, self-define FakeQuantize, Q-convolution and so on, can do well on easy task like MNINST, but I couldn’t get it work as well as FP32 version of my object tracking task.
Therefore, I’m turning back to pytorch to see if there’s any API to set z=0.
just to clarify, the goal is to do QAT and set zero_point to 0? can you just set dtype to qint8 and qscheme to per_tensor_symmetric when you use FakeQuantize?
2 Likes