Hi there!
I am writing to ask if there is an efficient way to speed up the loading time of quantized model (using post training static int8 quantization).
As of now, when I broke down the loading process of full-precision(i.e, fp32) and int8 model, loading time on int8 model requires much longer time than that on fp32 (see below). I think this is due to quantized::conv2d_prepack() process, but I don’t know how to optimize or speed up.
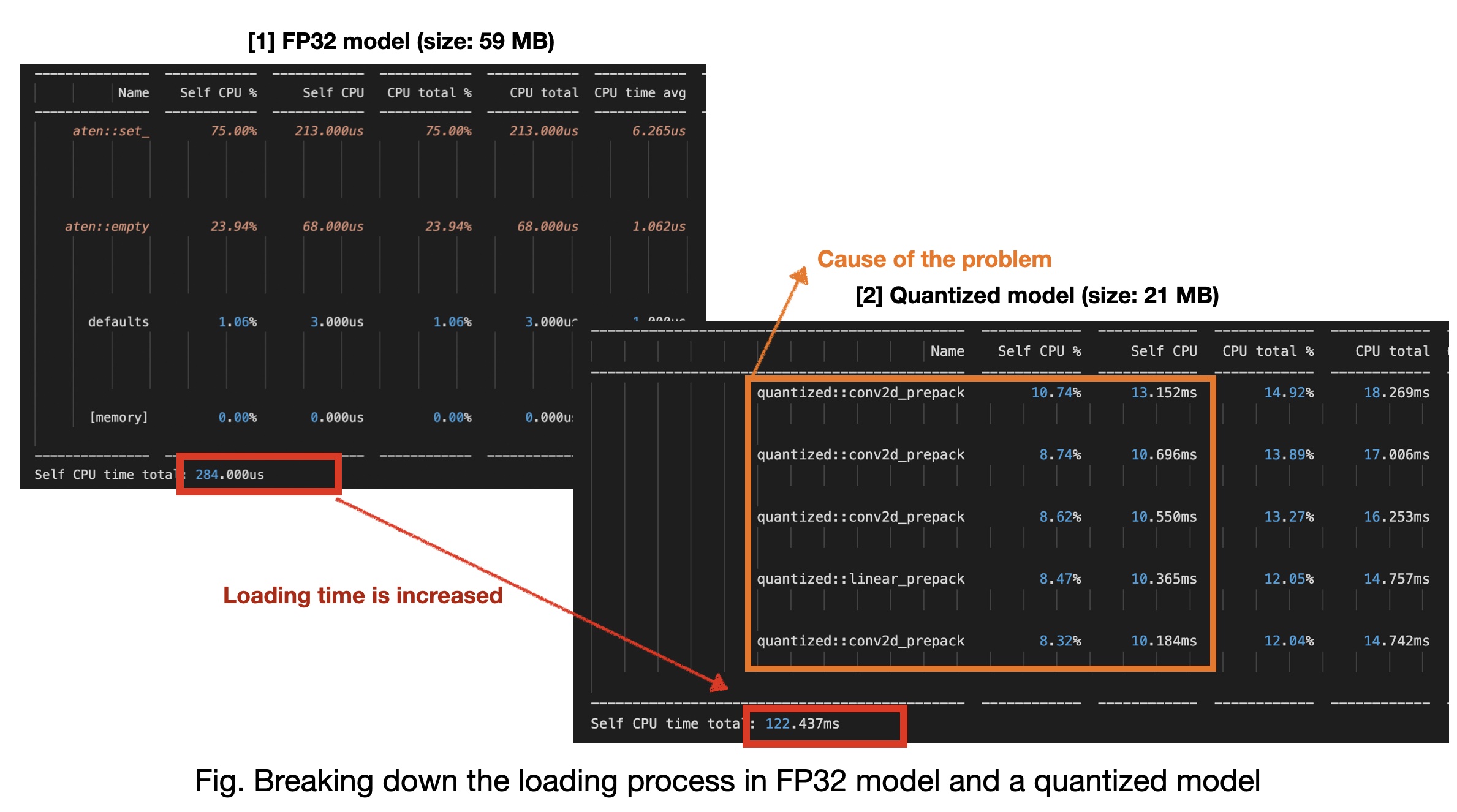
Thanks for reading my problem!
MK