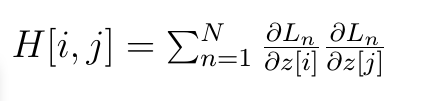Could you please let me know if there is anyway to calculate the Gauss-Hessian matrix ?
Gaussian Newton is a quasi-Newton method which is defined here. It does not calculate direct the Hessian but approximate the Hessian buy broastcast product of two gradients as following function.
Pytorch does calculate gradient, but it seems like a sum of gradients over all input vectors. Can I have a matrix of gradients wrt one variable that NOT SUM, so I can manipulate the gradients later ?
I’m assuming L is some vector that is some function of a vector z.
It sounds like you’re looking for the derivative matrix of L (something like this).
One thing you could do is compute the gradient of each element of L with respect to z. This will give you N gradients, that you could then concatenate to form the derivative matrix.
Thanks much for your answer.
The derivative matrix is what I need.
Yes I can do it manually using some for loops. But I also want to write it in pytorch and then put it running on GPU.
As I understand, foor loops is not good for performance, also unconvenient to put on GPU.
Could you please help to let me know does Pytorch has a better way to do that ?
Let’s say L is a transformation that takes a vector z as input. If your L can operate on multiple vectors at once, then you could do something like the following: (here, L squares all elements of the input):
z = torch.randn(3)
x = Variable(z.expand(3, 3), requires_grad=True)
out = (x ** 2).trace() # replace x ** 2 with L(x)
out.backward()
x.grad # gives the derivatives matrix
The idea is to have each row contribute to out independently. The first row would contribute the first element of L to out, the second row contributes the second element of L, etc.
Thanks much for your help. But if L is not a scalar as following:
z=Variable(torch.randn(1,1),requires_grad = True)
w = Variable(torch.randn(5,1),requires_grad = True)
x = Variable(torch.randn(5,1),requires_grad = False)
L = (xwz)**2
Can it return a vector of derivatives of each L's elements wrt z ?
Calling L.backward() returns error.
So I have to loop over each element of L to call backward. Is there a better way to do that ?
It works like a charm.
I did a numerical derivative by hand which returned same result.
Can’t say thank you enough. I tried to do the same in tensorflow for weeks but couldn’t. Just one day switched to pytorch and my problem solved.
Then how can I calculate the gradient matrix of L wrt to z ?
The result matrix should have the same size as L, which is (10,7) . But expand the z following shape of L would not fit the multiplication with w1 ?
import torch
from torch.autograd import Variable
from torch.nn.functional import sigmoid
x = Variable(torch.randn(10,3),requires_grad = False)
w1 = Variable(torch.randn(3,5),requires_grad = True)
w2 = Variable(torch.randn(5,7),requires_grad = True)
z=Variable(torch.randn(1,1),requires_grad = True)
L = (sigmoid(x.mm(w1*z))).mm(w2)
So the key idea here is that if you were to do this in a for loop, you’d be computing L 10 * 7 = 70 times.
Instead of doing this in a for loop, we’d want to batch the computation.
We can define a new Variable, zz, that will hold the derivative matrix. It will eventually be size (10, 7),
but for now we’ll make it a flat size 70 so that we can perform batch multiply operations with it.