I am working on a time series classification problem (5 classes) where the input contains 4 features with 90 samples for each feature.
class GRUModel(nn.Module):
def __init__(self, feature_size, hidden_size, output_size):
super(GRUModel, self).__init__()
self.gru = nn.GRU(feature_size, hidden_size, batch_first=True)
self.fc1 = nn.Linear(hidden_size, 64)
self.fc2 = nn.Linear(64, output_size)
def forward(self, x):
out, _ = self.gru(x)
out = out[:, -1, :]
out = self.fc1(out)
out = self.fc2(out)
return out
I’m looking on the weights of the first layer (the layer which first multiple the features):
l_feature_names = ['Feature_1', 'Feature_2', 'Feature_3', 'Feature_4', 'Feature_5', 'Feature_6', 'Feature_7', 'Feature_8']
first_layer_weights = np.abs(model.gru.weight_ih_l0.data.sum(axis=0))
plt.rc('font', size=16)
plt.figure(figsize=(30, 6))
plt.bar(l_feature_names, first_layer_weights)
plt.title('First layer')
plt.ylabel('Weights')
plt.show()

when looking at the graph I created above, is it correct that features with larger weights have a greater impact on the model, or is that not necessarily the case?"
Additionally, by examining the weights of the last layer:
l_class_names = ['class_1','class_2', 'class_3', 'class_4', 'class_5']
last_layer_weights = np.abs(model.fc2.weight.data.sum(axis=1))
plt.rc('font', size=16)
plt.figure(figsize=(30, 6))
plt.bar(l_class_names, last_layer_weights)
plt.title('First layer')
plt.ylabel('Weights')
plt.show()
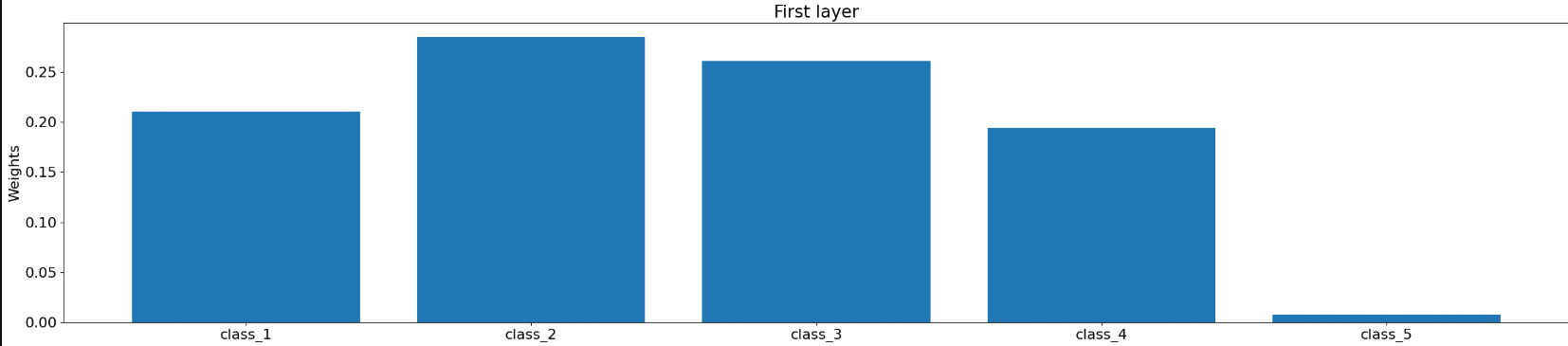
can we determine for which classes the model has more confidence in its classification?"