When i train my network, in 156th epochs the training is break. So i use --resume to continue training(load the last checkpoint).
But i see one phenomenon: the train loss will rise from 0.0870 to 0.1321, and it will take many epochs decrease to 0.08 again.
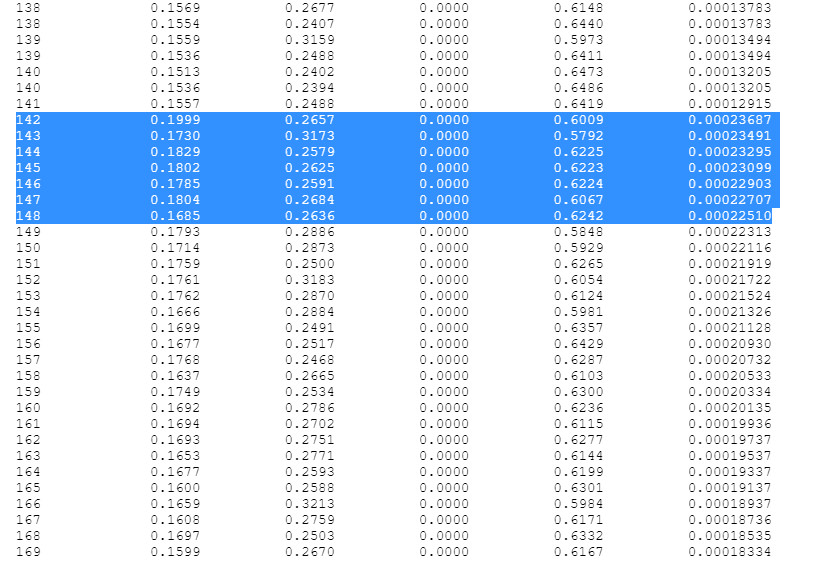
I also meet this problem in other training(after use --resume to load last checkpoint, the training loss will raise from 0.1557 to 0.1999. The val loss will raise from 0.2488 to 0.2657 and the iou will decrease from 0.6419 to 0.6009.):
It depends how you’ve implemented your “resume” logic. From your description I assume you are just loading the state_dict and start the training with a new optimizer.
Using an “adaptive” optimizer might worsen your accuracy, since the “old” optimizer had some internal states, momentum etc., while the new one will have a cold start.
You could try to save the optimizer’s state_dict as well.
However, why did the training break in the first place? Could you post the error and some information?
if args.resume:
if enc:
filenameCheckpoint = savedir + '/checkpoint_enc.pth.tar'
else:
filenameCheckpoint = savedir + '/checkpoint.pth.tar'
assert os.path.exists(filenameCheckpoint), "Error: resume option was used but checkpoint was not found in folder"
checkpoint = torch.load(filenameCheckpoint)
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['state_dict'])
optimizer.load_state_dict(checkpoint['optimizer'])
best_acc = checkpoint['best_acc']
print("=> Loaded checkpoint at epoch {})".format(checkpoint['epoch']))
In the code, maybe i have save the state_dict, so i also don’t know how to solve this problem.
About the training break, it is normal for me. Because i use a free machine from my school. It will break every 10 hours. I know it’s hurt, but i can’t do something for that.
I created a small dummy example and cannot recreate the issue.
I wanted to try of layers like Dropout and BatchNorm could possibly change something, but at least in the same terminal with a seed the model returns the same loss values.
Still, it could be an issue with the random number generator, although I cannot explain, why the loss spikes that much.
Could you try to compare the predictions after calling model.eval?