Background
I tried to quantize a simple model like ResNet18 (from torchvision), and didn’t like to fuse conv-bn-relu pattern, so I comment the fusing part in convert_fx.py, by which I can get a model like:
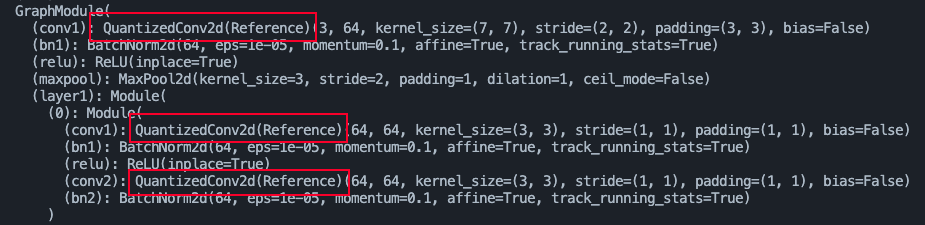
(As one can see, the
Conv2d modules have been replaced to the referenced ones)
and the graph is like:

(As one can see, the conv-bn-relu is not fused and there also has no observer between them)
Issue
Once I run convert function to convert this prepared_model to quantized one, the graph would be like:
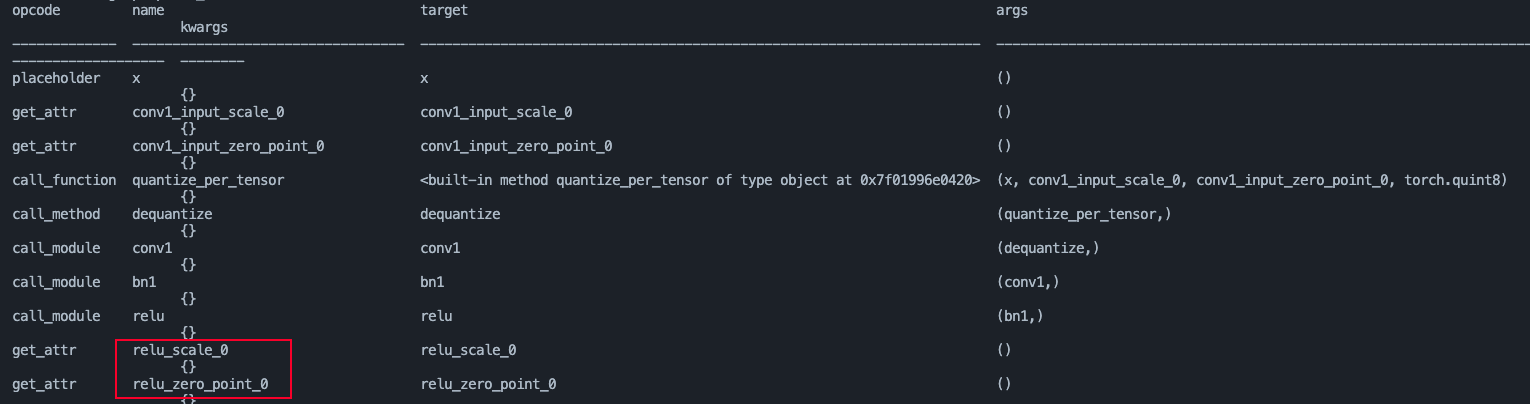
As expected, the reference convolution would be convert to QuantConv and there would be some nodes like conv1_scale_0 and conv1_zero_point_0, so when acting lower_to_fbgemm() these reference modules would not be convert to QuantConv, is something missing or some configs I set are wrong?