I tried to implement Autorec in Pytorch. The original model is written in mxnet. Here, I try to use the same idea in Pytorch.
If I mask the forward pass calculation such that I only calculate loss for non-zero ratings only during training I get these plots for testing error and rating distribution. I dont know why test error is increasing? but the rating distribution seems ok.
def forward(self, torch_input):
decoder = self.my_network(torch_input)
if self.training: # Mask the gradient during training
return decoder * torch.sign(torch_input)
else:
return decoder
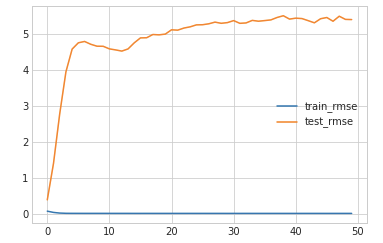
But if I do it during both training and testing. My test error looks better but my rating distribution plot is very off.
def forward(self, torch_input):
decoder = self.my_network(torch_input)
return decoder * torch.sign(torch_input)
Below please find the code: First, it creates the interaction matrix, and list of users, items and scores for Movie lens 100K data set. Then run the Autorec algorithm on it.
import zipfile
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import math
import urllib.request
import zipfile
import os
import sys
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import time
data_path = '/data/ml-100k/'
delimiter ='\t'
col_names=['user_id', 'item_id', 'rating', 'timestamp']
url = 'http://files.grouplens.org/datasets/movielens/ml-100k.zip'
# download-unzip and/or load the data
def read_data_ml100k(data_path, delimiter, col_names, url):
"""load movie lens data."""
if np.logical_not(os.path.isdir(data_path)):
zip_path, _ = urllib.request.urlretrieve(url)
with zipfile.ZipFile(zip_path, "r") as f:
print(pd.Series(f.namelist()))
f.extractall()
data = pd.read_csv(data_path + 'u.data', delimiter, names=col_names)
num_users, num_items = (data.user_id.nunique(), data.item_id.nunique())
sparsity = 1 - len(data) / (num_users * num_items)
print(f'number of users: {num_users}, number of items: {num_items}')
print(f'matrix sparsity: {sparsity:f}')
return data, num_users, num_items, sparsity
# Split into test-train
def split_data(data, num_users, num_items, split_mode='random', test_ratio=0.1):
"""Split the dataset in random mode or seq-aware mode."""
if split_mode == 'seq-aware':
train_items, test_items, train_list = {}, {}, []
for line in data.itertuples():
u, i, rating, time = line[1], line[6], line[6], line[6]
train_items.setdefault(u, []).append((u, i, rating, time))
if u not in test_items or test_items[u][-1] < time:
test_items[u] = (i, rating, time)
for u in range(1, num_users + 1):
train_list.extend(sorted(train_items[u], key=lambda k: k[6]))
test_data = [(key, *value) for key, value in test_items.items()]
train_data = [item for item in train_list if item not in test_data]
train_data = pd.DataFrame(train_data)
test_data = pd.DataFrame(test_data)
else:
mask = [
True if x == 1 else False
for x in np.random.uniform(0, 1, (len(data))) < 1 - test_ratio]
neg_mask = [not x for x in mask]
train_data, test_data = data[mask], data[neg_mask]
return train_data, test_data
# create interaction file
def load_data(data, num_users, num_items, feedback='explicit'):
"""Transform data into appropriate format."""
users, items, scores = [], [], []
inter = np.zeros((num_items, num_users)) if feedback == 'explicit' else {}
for line in data.itertuples():
user_index, item_index = int(line[1] - 1), int(line[6] - 1)
score = int(line[6]) if feedback == 'explicit' else 1
users.append(user_index)
items.append(item_index)
scores.append(score)
if feedback == 'implicit':
inter.setdefault(user_index, []).append(item_index)
else:
inter[item_index, user_index] = score
return users, items, scores, inter
#Error plot function
def plot_error(train_rmse, test_rmse, num_epochs):
plt.style.use('seaborn-whitegrid')
x = list(range(num_epochs))
fig = plt.figure()
ax = plt.axes()
plt.plot(x, train_rmse, label='train_rmse')
plt.plot(x, test_rmse, label='test_rmse')
leg = ax.legend()
plt.savefig("test_image.png")
# Call the above functions to create the datasets
data, num_users, num_items, sparsity = read_data_ml100k(data_path, delimiter, col_names, url)
train_data, test_data = split_data(data, num_users, num_items, split_mode='random', test_ratio=0.1)
train_users, train_items, train_scores, train_inter = load_data(train_data, num_users, num_items, feedback='explicit')
test_users, test_items, test_scores, test_inter = load_data(test_data, num_users, num_items, feedback='explicit')
# Hyper parameters
hidden_units = 100
p = 0.5 # dropout rate
num_epochs = 50
batch_size = 150
optimizer_method ='Adam'
lr = 1e-3
display_step =1
wd = 1e-4
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Create Dataloader
train_iter = DataLoader(train_inter, shuffle=True, batch_size=batch_size)
test_iter = DataLoader(test_inter, batch_size=batch_size)
# define the model
class AutoRec(nn.Module):
def __init__(self, num_items, num_users):
super(AutoRec, self).__init__()
self.my_network = torch.nn.Sequential(
nn.Linear(num_users, hidden_units),
nn.Sigmoid(),
nn.Dropout(p=p),
nn.Linear(hidden_units, num_users)
)
for m in self.modules():
if isinstance(m, nn.Linear):
#torch.nn.init.kaiming_uniform_(m.weight, mode = 'fan_in', nonlinearity = 'relu')
m.weight.detach().normal_(0,0.01)
if m.bias is not None:
m.bias.detach().zero_()
def forward(self, torch_input):
decoder = self.my_network(torch_input)
if self.training: # Mask the gradient during training
return decoder * torch.sign(torch_input)
else:
return decoder
model = AutoRec(num_items, num_users).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=wd)
#Run the model
train_rmse = []
test_rmse = []
for epoch in range(num_epochs):
train_loss = 0
num_train = 0
model.train()
for train_batch in train_iter:
train_batch = train_batch.type(torch.FloatTensor).to(device)
decoder = model(train_batch)
loss = criterion(decoder, train_batch)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
num_train += 1
train_rmse.append(train_loss / num_train)
model.eval()
test_loss = 0
num_test = 0
with torch.no_grad():
for test_batch in test_iter:
test_batch = test_batch.type(torch.FloatTensor).to(device)
decoder = model(test_batch)
loss = criterion(decoder, test_batch)
test_loss += loss.item()
num_test += 1
test_rmse.append(test_loss / num_test)
# Here we normalized the training error by the number of samples in each training and test bucket
gain=943*1682/len(train_scores)#len(test_scores)/len(train_scores)
plot_error([x*gain for x in train_rmse], test_rmse, num_epochs)
#plot the rating distribution
users, items, scores, inter = data_utils.load_data(data, num_users, num_items, feedback='explicit')
iterr = torch.FloatTensor(test_inter).to(device)
decoder = model(iterr)
pred = decoder.cpu().detach().numpy().tolist()
mask = np.ma.masked_equal(inter, 0)
score_df = pd.concat([pd.Series([i for sublist in np.ma.masked_array(pred, mask.mask).tolist() for i in sublist ], name='pred')
, pd.Series([i for sublist in np.ma.masked_array(inter, mask.mask).tolist() for i in sublist ], name='value')], axis=1)
plt.hist(score_df['pred'], bins=5, ec='black', alpha=0.8, label = 'Predicted')
plt.hist(score_df['value'], bins=5, ec='black', alpha=0.7, label = 'True')
plt.xlabel('Rating')
plt.ylabel('Count')
#plt.title('Distribution of Ratings in MovieLens 100K')
plt.legend()
plt.show()