Hello, I’m seeing an odd issue with using the pin_memory = true flag with the dataloader. I’m measuring the time taken to transfer data from the host RAM to GPU memory as follows:
transfer_time_start = time.time()
input = input.cuda(args.gpu, non_blocking=False)
target = target.cuda(args.gpu, non_blocking=False)
torch.cuda.synchronize()
transfer_time.update(time.time()-transfer_time_start)
with pin_memory = True in the dataloader, this gives me a transfer time of 0.03 sec, which for a batch size of 256, translates into 25622422434/0.03 = 5.1GB, which is a bit low for my CPU-GPU interconnect (x16, PCIe3) which should deliver ~12GB.
I then tried calling pin_memory() manually on the tensor returned by the enumerate call, as shown below:
for i, (input, target) in enumerate(train_loader):
input = input.pin_memory()
# measure data loading time
data_time.update(time.time() - end)
transfer_time_start = time.time()
input = input.cuda(args.gpu, non_blocking=False)
target = target.cuda(args.gpu, non_blocking=False)
torch.cuda.synchronize()
transfer_time.update(time.time()-transfer_time_start)
Now the transfer time dropped to 0.014, which translates to ~11GB, which is as expected. Anyone has any ideas why setting pin_memory = True in the data loader may not return a tensor already in pinned memory?
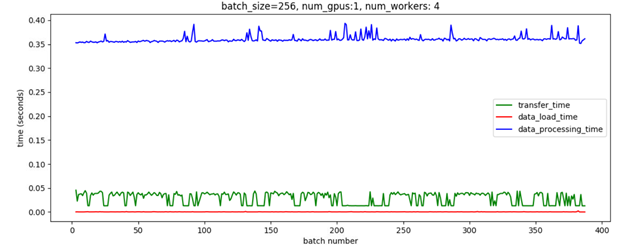
Also attached below are two plots showing the transfer time (green plot) from host memory to the GPU.
This plot shows the transfer time when I call pin_memory manually
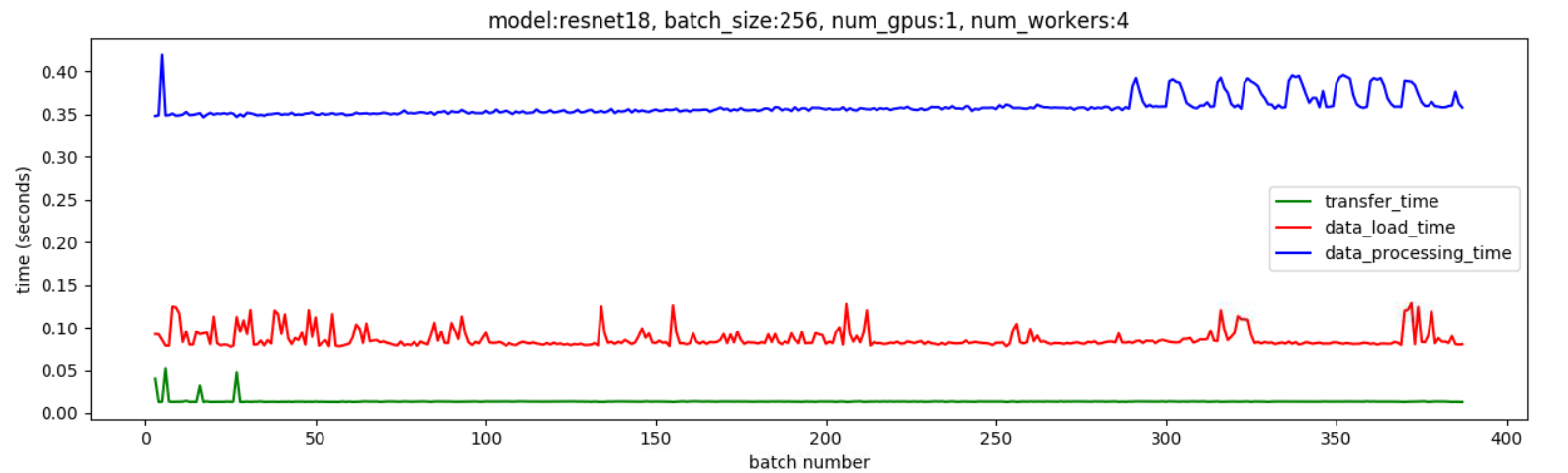
You can see that the transfer time stays consistently low.
Whereas this one shows the transfer time without calling pin_memory manually. Now the transfer time is highly variable and averages to around 0.03 sec