Hi,
I’m encountering a issue with the datasets.map function from the Hugging Face datasets library. When I try to apply a custom function to my dataset using map, the process seems to freeze, and I’m unsure why this is happening. This issue does not occur when I run the script an individually,
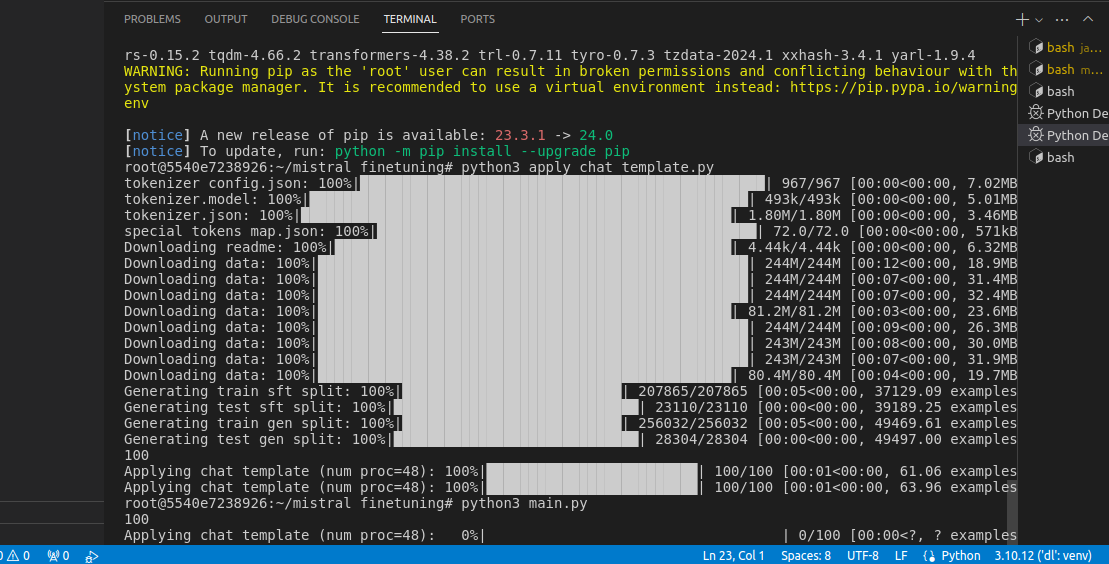
From the picture, if you notice the percentage remains at 0% even after couple of minutes. I am using ultra_chat dataset. Below are the scripts
# apply_chat_template.py
import re
import random
from multiprocessing import cpu_count
from load_tokenizer import tokenizer
from load_dataset import raw_datasets
import os
import torch
def apply_chat_template(example,tokenizer):
print('process example')
messages = example['messages']
if messages[0]['role'] != 'system':
messages.insert(0,{'role':'system','content':''})
example['text'] = tokenizer.apply_chat_template(messages,tokenize=False)
return example
print(raw_datasets['train'])
column_names = list(raw_datasets['train'].features)
raw_datasets = raw_datasets.map(apply_chat_template,
num_proc=os.cpu_count(),
fn_kwargs={'tokenizer':tokenizer},
remove_columns=column_names,
desc='Applying chat template'
)
train_dataset = raw_datasets['train']
test_dataset = raw_datasets['test']
print(train_dataset[0])
#load tokenizer.py
from transformers import AutoTokenizer
model_id = 'mistralai/Mistral-7B-v0.1'
tokenizer = AutoTokenizer.from_pretrained(model_id)
# set pad token id to eos token id if pad token id is not set
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.eos_token_id
if tokenizer.model_max_length > 100_000:
tokenizer.max_model_length = 2048
# set the chat template
DEFAULT_CHAT_TEMPLATE = "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>'}}\n{% endif %}\n{% endfor %}"
tokenizer.chat_template = DEFAULT_CHAT_TEMPLATE
'''
Below is the structure for chat template
{% for message in messages %}\n
{% if message['role'] == 'user' %}\n
{{ '<|user|>\n' + message['content'] + eos_token }}\n
{% elif message['role'] == 'system' %}\n
{{ '<|system|>\n' + message['content'] + eos_token }}\n
{% elif message['role'] == 'assistant' %}\n
{{ '<|assistant|>\n' + message['content'] + eos_token }}\n
{% endif %}\n
{% if loop.last and add_generation_prompt %}\n
{{ '<|assistant|>'}}\n
{% endif %}\n
{% endfor %}
'''
'''
#load_dataset.py
from datasets import load_dataset
from datasets import DatasetDict
# load the ultrachat dataset
ultra_dataset = load_dataset("HuggingFaceH4/ultrachat_200k")
indices = range(0,10)
dataset_dict = {
'train':ultra_dataset['train_sft'].select(indices=indices),
'test':ultra_dataset['test_sft'].select(indices=indices)
}
raw_datasets = DatasetDict(dataset_dict)
# load the first example
first_example = raw_datasets['train'][0]
# load the messages
messages = first_example['messages']
# messages is the list of dictionary
# The length of raw dataset
print(len(raw_datasets['train']))