Below is my end to end code for doing 2d object detection:
import os
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import matplotlib.pyplot as plt
# Define the dataset
class CircleDetectionDataset(Dataset):
def __init__(self, data_home):
self.data_home = data_home
self.image_files = sorted(os.listdir(os.path.join(data_home, 'images')))
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
image_name = self.image_files[idx]
image = np.load(os.path.join(self.data_home, 'images', image_name))
bbox = np.load(os.path.join(self.data_home, 'bbox_coordinates', image_name)).astype(np.float32) # Convert to float32
label = np.load(os.path.join(self.data_home, 'labels', image_name))
# Normalize image
image = image.astype(np.float32) / 255.0
# Normalize bounding boxes (assuming bbox format [y1, y2, x1, x2])
image_height, image_width = image.shape
bbox[:, 0] /= image_height # Normalize y1
bbox[:, 1] /= image_height # Normalize y2
bbox[:, 2] /= image_width # Normalize x1
bbox[:, 3] /= image_width # Normalize x2
# Convert to tensors
image = torch.from_numpy(image).unsqueeze(0) # Add channel dimension
bbox = torch.from_numpy(bbox).float()
label = torch.from_numpy(label).long()
# Combine bbox and label
targets = torch.cat((bbox, label.unsqueeze(-1).float()), dim=1)
return image, targets
# Define the SimpleObjectDetector model
# class SimpleObjectDetector(nn.Module):
# def __init__(self, num_classes=1, num_boxes=2):
# super(SimpleObjectDetector, self).__init__()
# self.num_classes = num_classes # Number of object classes to detect
# self.num_boxes = num_boxes # Number of bounding boxes to predict per image
# # Convolutional layers
# self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1) # Input: 1 channel (grayscale), Output: 32 channels
# self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1) # Input: 32 channels, Output: 64 channels
# self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1) # Input: 64 channels, Output: 128 channels
# self.conv4 = nn.Conv2d(128, 256, kernel_size=3, padding=1) # Input: 128 channels, Output: 256 channels
# self.pool = nn.MaxPool2d(2, 2) # Max pooling layer, reduces spatial dimensions by half
# # Fully connected layers
# self.fc1 = nn.Linear(256 * 2 * 2, 512) # First fully connected layer
# self.fc2 = nn.Linear(512, 256) # Second fully connected layer
# self.fc3 = nn.Linear(256, num_boxes * (4 + num_classes)) # Output layer
# # Activation and regularization
# self.relu = nn.ReLU() # ReLU activation function
# self.dropout = nn.Dropout(0.5) # Dropout layer for regularization
# def forward(self, x):
# # Forward pass through the network
# x = self.pool(self.relu(self.conv1(x))) # Conv1 + ReLU + MaxPool
# x = self.pool(self.relu(self.conv2(x))) # Conv2 + ReLU + MaxPool
# x = self.pool(self.relu(self.conv3(x))) # Conv3 + ReLU + MaxPool
# x = self.pool(self.relu(self.conv4(x))) # Conv4 + ReLU + MaxPool
# x = x.view(-1, 256 * 2 * 2) # Flatten the output for fully connected layers
# x = self.dropout(self.relu(self.fc1(x))) # FC1 + ReLU + Dropout
# x = self.dropout(self.relu(self.fc2(x))) # FC2 + ReLU + Dropout
# x = self.fc3(x) # Final fully connected layer
# # Reshape output to (batch_size, num_boxes, 4 + num_classes)
# # 4 represents the bounding box coordinates (x, y, width, height)
# # num_classes represents the class probabilities for each box
# return x.view(-1, self.num_boxes, 4 + self.num_classes)
class ImprovedObjectDetector(nn.Module):
def __init__(self, num_classes=1, num_boxes=2):
super(ImprovedObjectDetector, self).__init__()
self.num_classes = num_classes
self.num_boxes = num_boxes
# Feature Extraction (using ResNet-like blocks)
self.conv1 = nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(64, 64, 2)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.layer4 = self._make_layer(256, 512, 2, stride=2)
# Object Detection Head
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_boxes * (4 + num_classes))
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
layers = []
layers.append(ResidualBlock(in_channels, out_channels, stride))
for _ in range(1, blocks):
layers.append(ResidualBlock(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x.view(-1, self.num_boxes, 4 + self.num_classes)
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
# Loss function
class DetectionLoss(nn.Module):
def __init__(self, bbox_weight=1.0, class_weight=1.0, iou_weight=3.5):
super(DetectionLoss, self).__init__()
self.bbox_weight = bbox_weight
self.class_weight = class_weight
self.iou_weight = iou_weight
def forward(self, pred, target):
# Separate bbox and class predictions
pred_bbox = pred[:, :, :4]
pred_class = pred[:, :, 4]
# Separate target bbox and class
target_bbox = target[:, :, :4]
target_class = target[:, :, 4]
# Bounding box loss (using MSE loss)
bbox_loss = F.mse_loss(pred_bbox, target_bbox, reduction='sum')
# Classification loss (using BCE with logits)
class_loss = F.binary_cross_entropy_with_logits(pred_class, target_class, reduction='sum')
# IoU loss
# iou_loss = self.iou_loss(pred_bbox, target_bbox)
# Combine losses
# total_loss = self.bbox_weight * bbox_loss + self.class_weight * class_loss + self.iou_weight * iou_loss
total_loss = bbox_loss + class_loss
self.debug_info = {
'bbox_loss': bbox_loss.item(),
'class_loss': class_loss.item(),
# 'iou_loss': iou_loss.item()
}
return total_loss / pred.size(0) # Normalize by batch size
def iou_loss(self, pred_bbox, target_bbox):
# Calculate IoU
intersect_x1 = torch.max(pred_bbox[:, :, 2], target_bbox[:, :, 2])
intersect_y1 = torch.max(pred_bbox[:, :, 0], target_bbox[:, :, 0])
intersect_x2 = torch.min(pred_bbox[:, :, 3], target_bbox[:, :, 3])
intersect_y2 = torch.min(pred_bbox[:, :, 1], target_bbox[:, :, 1])
intersect_area = torch.clamp(intersect_x2 - intersect_x1, min=0) * torch.clamp(intersect_y2 - intersect_y1, min=0)
pred_area = (pred_bbox[:, :, 3] - pred_bbox[:, :, 2]) * (pred_bbox[:, :, 1] - pred_bbox[:, :, 0])
target_area = (target_bbox[:, :, 3] - target_bbox[:, :, 2]) * (target_bbox[:, :, 1] - target_bbox[:, :, 0])
union_area = pred_area + target_area - intersect_area
iou = intersect_area / (union_area + 1e-6) # Add small epsilon to avoid division by zero
# IoU loss
iou_loss = -torch.log(iou + 1e-6).sum() # Use log(IoU) as the loss
return iou_loss
def get_debug_info(self):
return self.debug_info
# Training function
def train(model, dataloader, criterion, optimizer, device):
model.train()
total_loss = 0
for images, targets in dataloader:
images, targets = images.to(device), targets.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(dataloader)
def calculate_iou(box1, box2):
x1 = np.maximum(box1[2], box2[2]) # x1 coordinate of the intersection
y1 = np.maximum(box1[0], box2[0]) # y1 coordinate of the intersection
x2 = np.minimum(box1[3], box2[3]) # x2 coordinate of the intersection
y2 = np.minimum(box1[1], box2[1]) # y2 coordinate of the intersection
# Compute the intersection area
intersection_area = np.maximum(0, x2 - x1) * np.maximum(0, y2 - y1)
# Compute the area of each box
box1_area = (box1[3] - box1[2]) * (box1[1] - box1[0])
box2_area = (box2[3] - box2[2]) * (box2[1] - box2[0])
# Compute the union area
union_area = box1_area + box2_area - intersection_area
# Compute IoU
return intersection_area / union_area if union_area > 0 else 0.0
# Evaluation function
def evaluate(model, dataloader, criterion, device):
model.eval()
total_loss = 0
total_iou = 0
num_samples = 0
with torch.no_grad():
for images, targets in dataloader:
images, targets = images.to(device), targets.to(device)
outputs = model(images)
loss = criterion(outputs, targets)
total_loss += loss.item()
# Calculate IoU for each sample in the batch
pred_boxes = outputs[:, :, :4].cpu().numpy()
true_boxes = targets[:, :, :4].cpu().numpy()
for pred, true in zip(pred_boxes, true_boxes):
iou = calculate_iou(pred[0], true[0]) # Assuming single box per image
total_iou += iou
num_samples += 1
avg_loss = total_loss / len(dataloader)
avg_iou = total_iou / num_samples
return avg_loss, avg_iou
def visualize_prediction(image, true_boxes, pred_boxes, image_height, image_width):
fig, ax = plt.subplots()
ax.imshow(image.squeeze(), cmap='gray')
colors = ['green', 'red']
# Denormalize bounding boxes to match original image dimensions
true_boxes_denorm = true_boxes.copy()
pred_boxes_denorm = pred_boxes.copy()
true_boxes_denorm[:, [0, 1]] *= image_height # Denormalize y1 and y2
true_boxes_denorm[:, [2, 3]] *= image_width # Denormalize x1 and x2
pred_boxes_denorm[:, [0, 1]] *= image_height # Denormalize y1 and y2
pred_boxes_denorm[:, [2, 3]] *= image_width # Denormalize x1 and x2
for i, (true_box, pred_box) in enumerate(zip(true_boxes_denorm, pred_boxes_denorm)):
# True bounding box
rect = plt.Rectangle((true_box[2], true_box[0]), true_box[3] - true_box[2], true_box[1] - true_box[0],
fill=False, edgecolor=colors[0], linewidth=2)
ax.add_patch(rect)
ax.text(true_box[2], true_box[0], f'True {i+1}', color=colors[0], fontweight='bold')
# Predicted bounding box
rect = plt.Rectangle((pred_box[2], pred_box[0]), pred_box[3] - pred_box[2], pred_box[1] - pred_box[0],
fill=False, edgecolor=colors[1], linewidth=2)
ax.add_patch(rect)
ax.text(pred_box[2], pred_box[0], f'Pred {i+1}', color=colors[1], fontweight='bold')
ax.set_title('Object Detection Result')
plt.show()
# Main execution
import matplotlib.pyplot as plt
if __name__ == "__main__":
# Set up data
data_home = '/home/localssk23/simple_object_detection/dataset/2d/'
dataset = CircleDetectionDataset(data_home)
train_size = int(0.8 * len(dataset))
test_size = len(dataset) - train_size
# Data augmentation
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(10),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
# Add more augmentations as needed
])
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
train_dataset.dataset.transform = transform # Apply augmentation only to training set\
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True,)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# Set up model, loss, and optimizer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# model = SimpleObjectDetector().to(device)
model = ImprovedObjectDetector().to(device)
criterion = DetectionLoss(bbox_weight=1.0, class_weight=1.0, iou_weight=2.0) # Increase weight for IoU loss
# optimizer = optim.Adam(model.parameters(), lr=0.0001)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # Use SGD with momentum
train_losses = []
test_losses = []
test_ious = []
# Training loop
num_epochs = 50 # Increase number of epochs
for epoch in range(num_epochs):
train_loss = train(model, train_loader, criterion, optimizer, device)
test_loss, test_iou = evaluate(model, test_loader, criterion, device)
debug_info = criterion.get_debug_info()
print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Test IoU: {test_iou:.4f}")
print("Debug Info:")
for key, value in debug_info.items():
print(f" {key}: {value:.4f}")
print()
# Append losses and IoU to the lists
train_losses.append(train_loss)
test_losses.append(test_loss)
test_ious.append(test_iou)
# Add learning rate scheduler
if (epoch + 1) % 10 == 0:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.9 # Reduce learning rate by 10% every 10 epochs
# Inference and visualization
model.eval()
test_image, test_targets = test_dataset[0]
with torch.no_grad():
prediction = model(test_image.unsqueeze(0).to(device))
print('Prediction Box: ', prediction)
print('True Box: ', test_targets)
pred_boxes = prediction[0, :, :4].cpu().numpy()
true_boxes = test_targets[:, :4].numpy()
visualize_prediction(test_image, true_boxes, pred_boxes, test_image.size(-2), test_image.size(-1))
# After the training loop, add this code to plot the loss curves:
plt.figure(figsize=(12, 4))
# Plot training and test loss
plt.subplot(1, 2, 1)
plt.plot(range(1, num_epochs + 1), train_losses, label='Train Loss')
plt.plot(range(1, num_epochs + 1), test_losses, label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and Test Loss')
plt.legend()
# Plot test IoU
plt.subplot(1, 2, 2)
plt.plot(range(1, num_epochs + 1), test_ious, label='Test IoU')
plt.xlabel('Epoch')
plt.ylabel('IoU')
plt.title('Test IoU')
plt.legend()
plt.tight_layout()
plt.show()
Here is an example prediction:
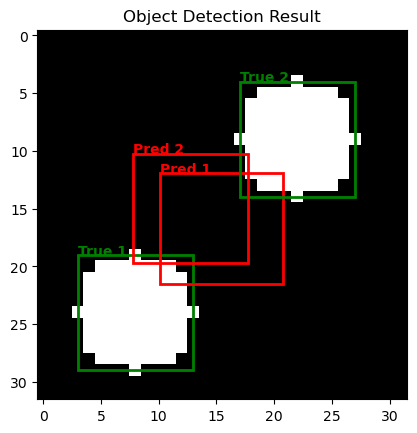
This is how my entire dataset is. Just 2000 images of that.
Just 1 class (and background)
Here are my curves:
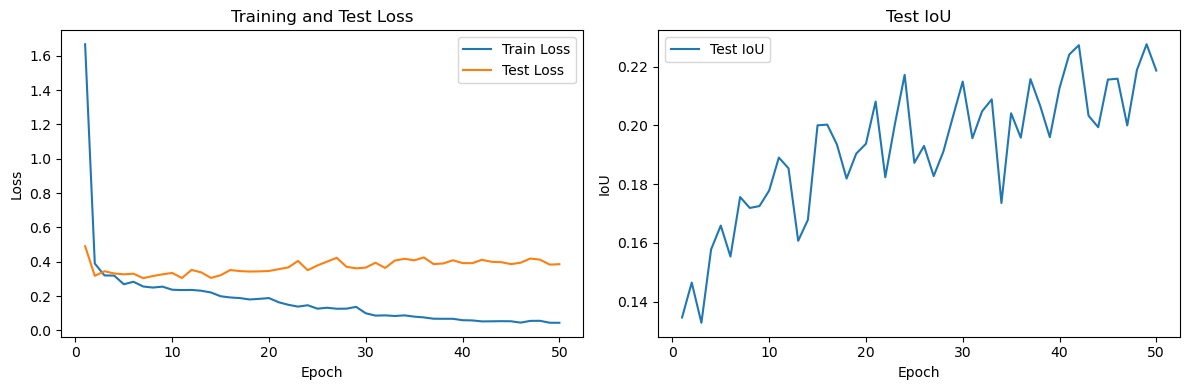
Could someone let me know what I can change (or did wrong) to get a good convergence/result/IoU value?
Happy to provide for information!
Thanks!