My data is both image and the compressed(.npz) files that contain 3d points and labels for each 3d points(contains a minimum of 646464 points and each file size varies from 10MB to 45MB). num_workers=4, batch_size=32, points_sampled for every batch is 2048.
Total number of parameters: 13414465
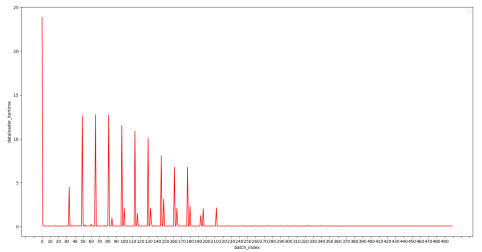
train batch 1 load time 21.43259024620056s
train batch 2 load time 0.031423091888427734s
train batch 3 load time 0.004406452178955078
train batch 4 load time 0.004347562789916992 train batch 5 load time 18.13344931602478
train batch 6 load time 0.004399538040161133
train batch 7 load time 0.03353142738342285
train batch 8 load time 0.004467010498046875 train batch 9 load time 16.202253103256226
train batch 10 load time 0.8377358913421631
I understand that input file is too large and I load it from a network location, this could cause the slowdown.
Questions are…
Each worker preloads a complete batch. If all start at the same time, they might finish close to each other and in your case 4 batches might be ready. Your actual model workload seems to be small in comparison to the data loading so that the training using these 4 batches finishes quickly. Meanwhile the workers already started to load the new batches, but cannot keep up with the model training so you have clearly a data loading bottleneck in your code.
Have a look at this post for a general explanation and some advice.
I think you would get the best performance using a “sane” number of workers, which depend on your overall system. E.g. 4 workers might work well for local workstations, but might not be enough for bigger servers.
The prefetch_factor doesn’t accelerate the data loading so if the workers are too slow and each worker can finish to load a single batch, the slowdown will happen after these 4 batches are consumed as described in the previous post.
thank you for your answer, In the data loader source code, prefetch_ factor acts on _reset function.I increased the prefetch_factor, resulting in more obvious periodicity. As you say, prefetch_factor cannot accelerate the data loading then what is it real role.
It’s role is to create a “buffer” by adding samples to a queue so that the training doesn’t stall assuming:
the data loading is fast enough and
the model training workload is large enough compared to the data loading.
It seems the previous example might still be unclear so try to imagine the timeline if your workload uses:
10 seconds to load a single batch
0.25s second to train the model (forward/backward/step) using a single batch.
In this case, the initial “warmup” time will take ~10s to allow each worker to load a single batch.
The queue will now be filled with 4 ready batches. The workers will immediately start loading the next batch (as the prefetching kicks in) which will take another ~10s.
The model finishes the training using all 4 batches in 1s (4x0.25s) and has to wait for the next data to be ready. Since that’s not the case, you will see a stall in the training regardless how high the prefetch_factor is set.
a good example helps i understand your what you mean.
but i am still confused that prefetch_factor’s action position.
the experiments’ factor: num_process =16, prefetch_factor =2
the first 32 batches took less time, i think prefetch_factor works,but after that the iteration is 16 = num_workers
so im confused that it just work in the initial.Or it works in the whole training, i understand in the wrong way.
Coming back at this in 2024 – we are facing a similar issue and I’m confused too because there should have been about prefetch_factor * num_workers batches fetched in advance before step 0 starts. However, I’m seeing slowness every #num_workers steps.
Should data loading be the bottleneck, shouldn’t we expect to see slowness every prefetch_factor * num_workers step but not every num_workers steps?
I can draft a more detailed post too. Thanks in advance.
Imagine the current iteration needs to wait for an input batch to be ready and you are thus seeing a wait time.
After the queue is filled with a data sample, the training iteration starts and the workers start loading the next batch.
The training iterations continue until the queue is empty again and waits. Let’s assume all workers have added their batch into the queue.
If the training iteration finishes before any of the workers was able to push a new batch into the queue, you will see a wait time every num_workers.
The prefetch_factor defines how many batches each worker is is allowed to prefetch, but does not mean we have to wait in each iteration for the queue to be filled again (this wouldn’t be useful since you would fall back to a prefetch_factor=1 use case).