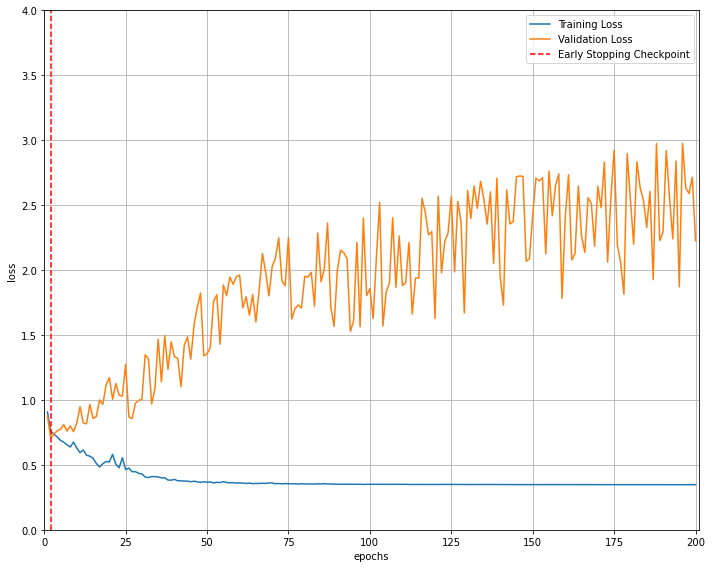
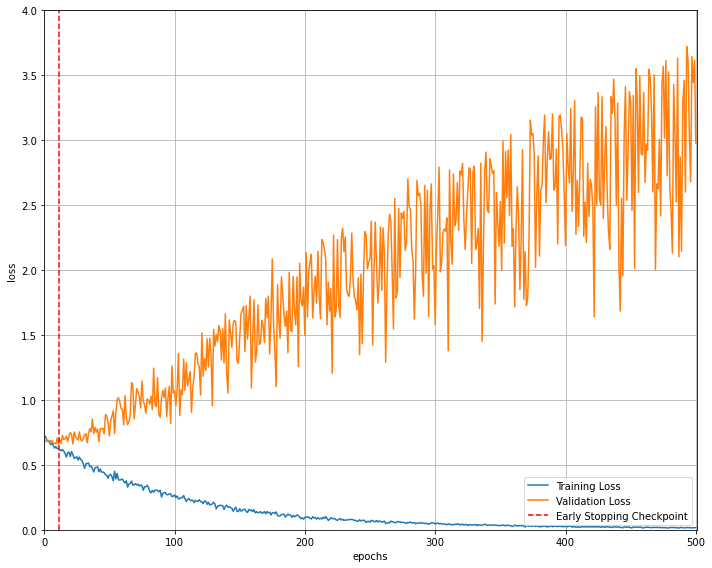
Hi! Thank you for your suggestions. I have used nn.BCEWithLogitsLoss as my loss function, training loss struck at 0.3 and when I use nn.CrossEntropyLoss it gives me the following graph (converging at zero).
- Can we not use both loss for binary classification?
- The validation accuracy is very poor (for fewer samples: 50) though the training loss is converging at zero. What would be the reason?
I have also attached the code for your suggestions to improve the validation accuracy.
learning_rate=0.0001
criterion =nn.CrossEntropyLoss() #nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, betas=[0.9,0.999], amsgrad=False)
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt', trace_func=print):
"""
Args:
patience (int): How long to wait after last time validation loss improved.
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
Default: 0
path (str): Path for the checkpoint to be saved to.
Default: 'checkpoint.pt'
trace_func (function): trace print function.
Default: print
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
self.trace_func = trace_func
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
self.trace_func(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.'''
if self.verbose:
self.trace_func(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
def train_model(model, batch_size, patience, n_epochs):
# to track the training loss as the model trains
train_losses = []
# to track the validation loss as the model trains
valid_losses = []
# to track the average training loss per epoch as the model trains
avg_train_losses = []
# to track the average validation loss per epoch as the model trains
avg_valid_losses = []
# initialize the early_stopping object
early_stopping = EarlyStopping(patience=patience, verbose=True)
for epoch in range(1, n_epochs + 1):
###################
# train the model #
###################
model.train() # prep model for training
for batch, (features,label) in enumerate(train_dataloader):
features = features.unsqueeze(1)
features = features.to(device)
#(32,1,12,301)
label = label.to(device)
# Clear the gradients
optimizer.zero_grad()
# Forward Pass
target = model(features)
# Find the Loss
loss = criterion(target, label)
# Calculate gradients
loss.backward()
# Update Weights
optimizer.step()
# Calculate Loss
train_losses.append(loss.item())
_, predicted = torch.max(target, 1)
actual = torch.argmax(label, dim=1) #torch.max(label, 1)
correct_t = (predicted == actual).sum().item()
accuracy_train = 100 * correct_t / target.shape[0]
######################
# validate the model #
######################
model.eval() # prep model for evaluation
for features,label in valid_dataloader:
features = features.unsqueeze(1)
features = features.to(device)
# forward pass: compute predicted outputs by passing inputs to the model
output = model(features)
label_v = label.to(device)
# Find the Loss
loss = criterion(output,label)
# Calculate Loss
valid_losses.append(loss.item())
_, predicted_v = torch.max(output, 1)
actual_v = torch.argmax(label_v, dim=1) #torch.max(label, 1)
correct_v = (predicted_v == actual_v).sum().item()
accuracy_valid = 100 * correct_v / target.shape[0]
# print training/validation statistics
# calculate average loss over an epoch
train_loss = np.average(train_losses)
valid_loss = np.average(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
epoch_len = len(str(n_epochs))
print_msg = (f'[{epoch:>{epoch_len}}/{n_epochs:>{epoch_len}}] ' +
f'train_loss: {train_loss:.5f} ' +
f'Accuracy_train :{accuracy_train :.5f}' +
f'valid_loss: {valid_loss:.5f}' +
f'Accuracy_valid :{accuracy_valid :.5f}')
print(print_msg)
# clear lists to track next epoch
train_losses = []
valid_losses = []
# early_stopping needs the validation loss to check if it has decresed,
# and if it has, it will make a checkpoint of the current model
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
# load the last checkpoint with the best model
model.load_state_dict(torch.load('checkpoint.pt'))
return model, avg_train_losses, avg_valid_losses
batch_size = 5
n_epochs = 500
patience = 100
model, train_loss, valid_loss = train_model(model, batch_size, patience, n_epochs)
Thank you very much.