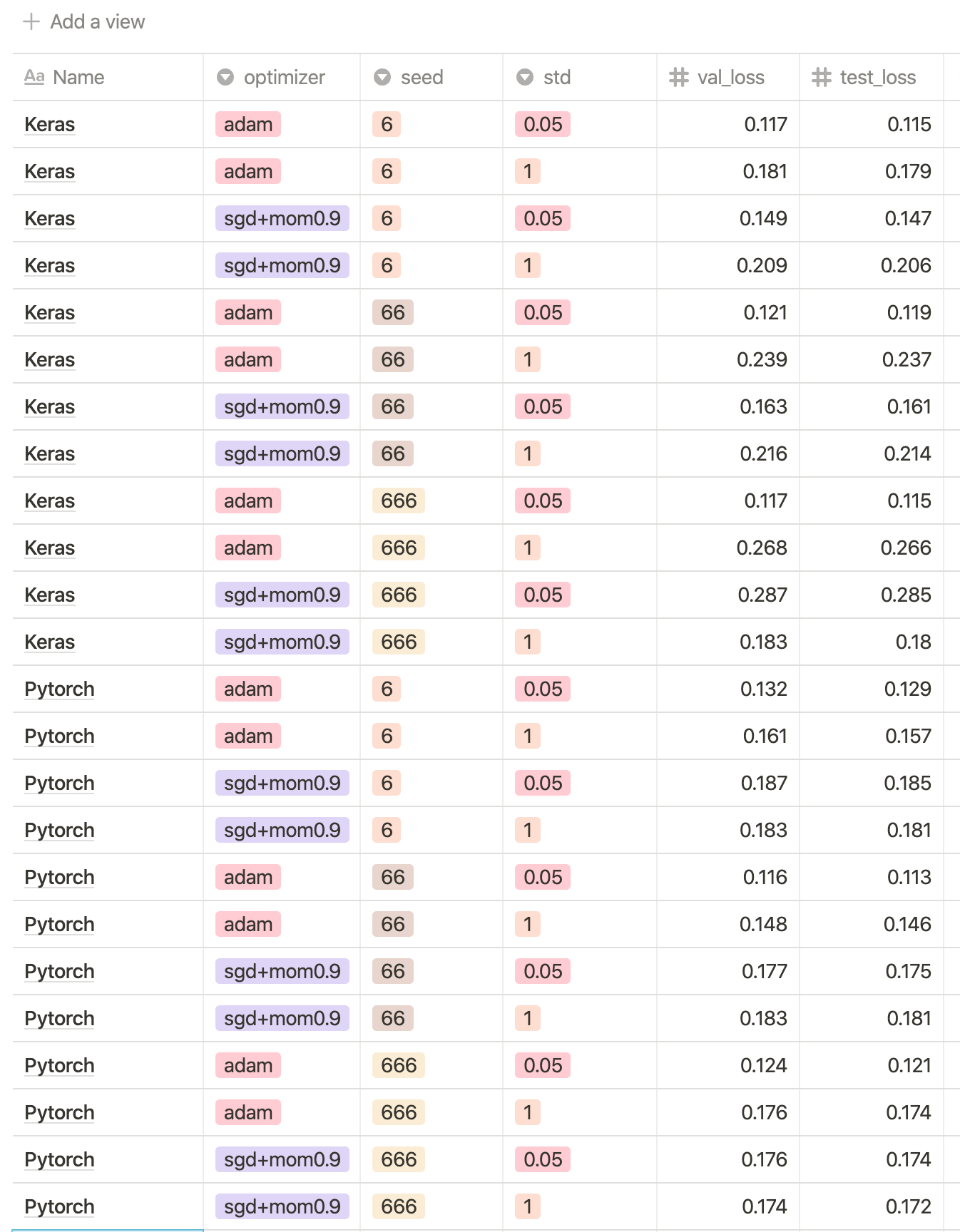
Problem
I generated a small dataset, use simple MLP to fit this function in pytorch and keras to compare speed and performance. I define two networks with same setting(cpu, l2_reg, dropout, layers, weights initialization…)
The result is: keras has faster data traverse speed, less cpu usage and better generalization results.
Updated!
I set num_workers=4 of dataloader, each epoch time takes 1.44s, dataloader for loop takes 0.8s, the train time is comparable with keras. I also set torch.set_num_threads(8), the cpu usage is normal. But under the same setting, Keras still gets better results. There must be something wrong…
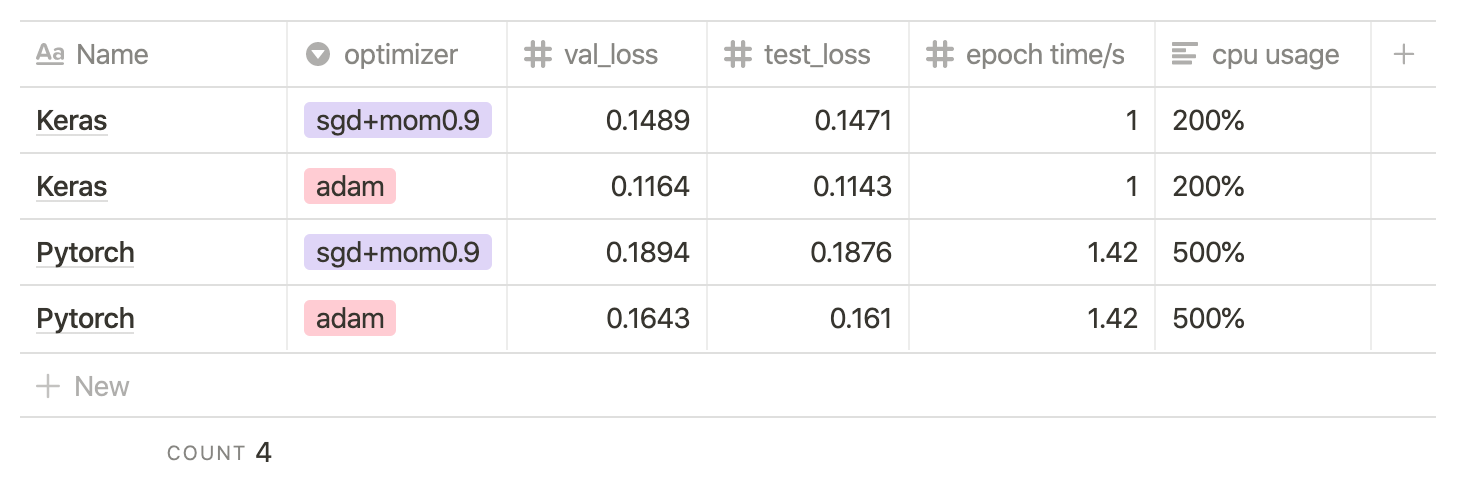
There must be something wrong.
I really enjoy the flexibility of pytorch, can anybody help me where the problem is? thanks!
Train Code
pytorch
#####################generate data
#f(x) = x[:39:2]**3 * x[1:40:2]**2 + x[:40:4] + noise
import numpy as np
seed = 6
np.random.seed(seed)
train_x = np.random.random((300000, 80))
train_y = np.sum(train_x[:, :39:2]**3, axis=1) * np.sum(train_x[:, 1:40:2]**2, axis=1) + np.sum(train_x[:, :40:4], axis=1) #+ np.random.random(train_x.shape[0])
train_y = (train_y - np.mean(train_y)) / np.std(train_y)
train_y = train_y.reshape((-1, 1))
val_x = np.random.random((10000, 80))
val_y = np.sum(val_x[:, :39:2]**3, axis=1) * np.sum(val_x[:, 1:40:2]**2, axis=1) + np.sum(val_x[:, :40:4], axis=1) #+ np.random.random(val_x.shape[0])
val_y = (val_y - np.mean(val_y)) / np.std(val_y)
val_y = val_y.reshape((-1, 1))
test_x = np.random.random((10000, 80))
test_y = np.sum(test_x[:, :39:2]**3, axis=1) * np.sum(test_x[:, 1:40:2]**2, axis=1) + np.sum(test_x[:, :40:4], axis=1) #+ np.random.random(test_x.shape[0])
test_y = (test_y - np.mean(test_y)) / np.std(test_y)
test_y = test_y.reshape((-1, 1))
#####################pytorch code
import time
import re
import os
import logging
import torch
torch.set_num_threads(8)
import torch.nn as nn
import pickle
from collections import OrderedDict
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader, Sampler
import torch.nn.functional as F
LOG_FORMAT = '%(levelname)s %(asctime)s.%(msecs)03d %(filename)s[%(lineno)d]: %(message)s'
DATE_FORMAT = '%Y-%m-%d %H:%M:%S'
logging.basicConfig(level = logging.INFO,
format=LOG_FORMAT,
datefmt=DATE_FORMAT)
logging.getLogger().setLevel('INFO')
logging.info(f"train_x[:5, :5]:\n{train_x[:5, :5]}")
class ModelDataset(Dataset):
"""docstring for ModelDataset"""
def __init__(self, x, y, x_dtype=torch.float, y_dtype=torch.float):
super(ModelDataset, self).__init__()
self.x = torch.tensor(x, dtype=x_dtype)
self.y = torch.tensor(y, dtype=y_dtype)
def __len__(self):
return self.x.shape[0]
def __getitem__(self, i):
return self.x[i], self.y[i]
class MLP(nn.Module):
'''MLP
input_dimention: 28
结构 28*20*10*3
'''
def __init__(self, input_dim=26, dropout=0.5, hidden_layers=[128, 64]):
super(MLP, self).__init__()
self.dropout = dropout
self.hidden_layers = hidden_layers
self.model = nn.Sequential()
layers = [input_dim] + hidden_layers
for i in range(len(layers)-1):
self.model.add_module(
'fc%d' % (i+1), nn.Linear(layers[i], layers[i+1]))
self.model.add_module('bn%d' % (i+1), nn.BatchNorm1d(layers[i+1]))
self.model.add_module('dropout%d' % (i+1), nn.Dropout(dropout))
self.model.add_module('relu%d' % (i+1), nn.ReLU())
self.model.add_module('fc_out', nn.Linear(layers[-1], 1))
for name, param in self.model.named_parameters():
#bn层默认初始化
if "bn" in name or "relu" in name:
continue
if "weight" in name: # weight matrix
nn.init.xavier_uniform_(param.data)
else: # bias
nn.init.zeros_(param.data)
# last layer: random normal
for name, param in self.model.fc_out.named_parameters():
#bn层默认初始化
if "bn" in name or "relu" in name:
continue
if "weight" in name: # weight matrix
nn.init.normal_(param.data)
else: # bias
nn.init.zeros_(param.data)
def forward(self, input_data):
'''input_data: (x: batch_size*input_dim, '''
output = self.model(input_data)
return output
#params
save_dir = "/root/work"
init_lr = 0.005
l2_regularizer = 1e-5
loss = 'mse'
device = torch.device('cpu')
# device = torch.device("cuda:0")
np.random.seed(6)
torch.manual_seed(6)
torch.backends.cudnn.deterministic=True
torch.backends.cudnn.benchmark=True
model = MLP(train_x.shape[1], 0.5, [40, 20, 20])
model.to(device)
criterion = nn.MSELoss()
train_dataset = ModelDataset(train_x, train_y)
val_dataset = ModelDataset(val_x, val_y)
if loss == 'mse':
criterion = nn.MSELoss()
# dataloader
train_loader = DataLoader(dataset=train_dataset, batch_size=512*4, shuffle=True, num_workers=4)
val_loader = DataLoader(dataset=val_dataset, batch_size=512*4, shuffle=False, num_workers=4)
#optimizer: only regularize weight matrix like keras
reg_params = []
no_reg_params = []
for name, param in model.named_parameters():
match = re.match(r".*weight", name)
if match is None or "bn" in name:
no_reg_params.append(param)
else:
logging.info(f"regularizing: {name}")
reg_params.append(param)
params = [
{'params': reg_params, 'weight_decay': l2_regularizer, 'name': 'reg_params'},
{'params': no_reg_params, 'weight_decay': 0, 'name': 'no_reg_params'}
]
optimizer = torch.optim.Adam(params, lr=init_lr)
# optimizer = torch.optim.SGD(params, lr=init_lr, momentum=0.9)
optim_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min', factor=0.2, patience=6, cooldown=20)
##################################train code
max_epochs = 100
min_loss = np.inf # for checkpoint
for epoch in range(1, 1+max_epochs):
epoch_start_time = time.time()
for data, target in train_loader:
pass
for_loop_time = time.time() - epoch_start_time
#train
model.train()
for data, target in train_loader:
# pass
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
logging.info(f"Epoch: {epoch} Training: loss: {loss.item():.4f}, LR: {optimizer.param_groups[0]['lr']:.5f}")
#eval
model.eval()
with torch.no_grad():
val_loss_sum = 0
val_count = 0
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = criterion(output, target)
val_loss_sum += loss.item() * data.shape[0]
val_count += data.shape[0]
val_loss = val_loss_sum / val_count
epoch_end_time = time.time()
epoch_time = epoch_end_time - epoch_start_time
logging.info(f"\t\tEpoch: {epoch} Validation: loss: {val_loss:.4f} using {epoch_time:.4f}s, loader loop {for_loop_time:.4f}s, training {epoch_time - for_loop_time:.4f}s")
optim_scheduler.step(val_loss)
#checkpoint
if val_loss < min_loss:
torch.save(model.state_dict(), os.path.join(save_dir, f'best_model.pth'))
min_loss = val_loss
diff = np.ravel(model(torch.tensor(val_x, dtype=torch.float)).cpu().detach().numpy()) - np.ravel(val_y)
logging.info(f"val loss: {np.mean(diff**2)}")
diff = np.ravel(model(torch.tensor(test_x, dtype=torch.float)).cpu().detach().numpy()) - np.ravel(test_y)
logging.info(f"test loss: {np.mean(diff**2)}")
keras
#####################generate data
#f(x) = x[:39:2]**3 * x[1:40:2]**2 + x[:40:4] + noise
import numpy as np
seed = 6
np.random.seed(seed)
train_x = np.random.random((300000, 80))
train_y = np.sum(train_x[:, :39:2]**3, axis=1) * np.sum(train_x[:, 1:40:2]**2, axis=1) + np.sum(train_x[:, :40:4], axis=1) #+ np.random.random(train_x.shape[0])
train_y = (train_y - np.mean(train_y)) / np.std(train_y)
train_y = train_y.reshape((-1, 1))
val_x = np.random.random((10000, 80))
val_y = np.sum(val_x[:, :39:2]**3, axis=1) * np.sum(val_x[:, 1:40:2]**2, axis=1) + np.sum(val_x[:, :40:4], axis=1) #+ np.random.random(val_x.shape[0])
val_y = (val_y - np.mean(val_y)) / np.std(val_y)
val_y = val_y.reshape((-1, 1))
test_x = np.random.random((10000, 80))
test_y = np.sum(test_x[:, :39:2]**3, axis=1) * np.sum(test_x[:, 1:40:2]**2, axis=1) + np.sum(test_x[:, :40:4], axis=1) #+ np.random.random(test_x.shape[0])
test_y = (test_y - np.mean(test_y)) / np.std(test_y)
test_y = test_y.reshape((-1, 1))
#####################keras code
import os
import random
# from tensorflow.keras.callbacks import *
from tensorflow.keras import backend as K
import tensorflow as tf
from keras.models import Model
from keras import layers
from keras.models import Sequential
from keras.layers import Input, Dense, Dropout, Activation, noise, normalization
from keras.models import load_model
from keras import regularizers
from keras.optimizers import Adam, SGD
from keras.layers.normalization import BatchNormalization
from keras.callbacks import EarlyStopping
from keras.callbacks import ReduceLROnPlateau
from keras.callbacks import ModelCheckpoint
import logging
LOG_FORMAT = '%(levelname)s %(asctime)s.%(msecs)03d %(filename)s[%(lineno)d]: %(message)s'
DATE_FORMAT = '%Y-%m-%d %H:%M:%S'
logging.basicConfig(level = logging.INFO,
format=LOG_FORMAT,
datefmt=DATE_FORMAT)
logging.getLogger().setLevel('INFO')
logging.info(f"train_x[:5, :5]:\n{train_x[:5, :5]}")
seed_value = 6
os.environ['PYTHONHASHSEED']='0'
# os.environ["CUDA_VISIBLE_DEVICES"] = "1"
random.seed(seed_value)
np.random.seed(seed_value)
tf.random.set_seed(seed_value)
save_dir = "/root/work"
os.makedirs(save_dir, exist_ok=True)
inited_lr = 0.005
l1_regularizer = 0
l2_regularizer = 1e-5
hidden_layers = [40, 20, 20]
dropout = 0.5
model_k = Sequential()
model_k.add(Dense(hidden_layers[0], input_dim=train_x.shape[1], kernel_regularizer=regularizers.l2(l2_regularizer)))
model_k.add(BatchNormalization())
model_k.add(Dropout(dropout))
model_k.add(Activation('relu'))
for i in range(1,len(hidden_layers)):
model_k.add(Dense(hidden_layers[i], input_dim=hidden_layers[i - 1], kernel_regularizer=regularizers.l2(l2_regularizer)))
model_k.add(BatchNormalization())
model_k.add(Dropout(dropout))
model_k.add(Activation('relu'))
output_layer = Dense(1, input_dim=hidden_layers[-1], kernel_initializer='random_normal', kernel_regularizer=regularizers.l2(l2_regularizer))
model_k.add(output_layer)
model_k.compile(loss='mean_squared_error', optimizer=Adam(lr=inited_lr, beta_1=0.9, beta_2=0.999, decay = 0.0, epsilon=1e-08))
# model_k.compile(loss='mean_squared_error', optimizer=SGD(lr=inited_lr, momentum=0.9))
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=6, mode='auto', cooldown=20, verbose=1)
checkpoint = ModelCheckpoint(filepath=os.path.join(save_dir, 'best_model_k.h5'), monitor='val_loss',verbose=0, save_best_only=True, period=1)
#reduce_lr
hist = model_k.fit(train_x, train_y, epochs = 100, shuffle = True, batch_size = 512 * 4, validation_data=(val_x, val_y), callbacks=[reduce_lr, checkpoint])
diff = np.ravel(model_k.predict(val_x)) - np.ravel(val_y)
logging.info(f"val loss: {np.mean(diff**2)}")
diff = np.ravel(model_k.predict(test_x)) - np.ravel(test_y)
logging.info(f"test loss: {np.mean(diff**2)}")
Train Platform
##########pytorch
# (torch) ➜ dev git:(master) ✗ python3.8 -m pip show torch
# Name: torch
# Version: 1.7.0a0+df252c0
# Summary: Tensors and Dynamic neural networks in Python with strong GPU acceleration
# Home-page: https://pytorch.org/
# Author: PyTorch Team
# Author-email: packages@pytorch.org
# License: BSD-3
# Location: /root/miniconda3/envs/torch/lib/python3.8/site-packages
# Requires: future, numpy
# Required-by:
###########keras
#➜ quantum git:(dev) pip show keras
# Name: Keras
# Version: 2.4.3
# Summary: Deep Learning for humans
# Home-page: https://github.com/keras-team/keras
# Author: Francois Chollet
# Author-email: francois.chollet@gmail.com
# License: MIT
# Location: /usr/local/lib/python3.7/dist-packages
# Requires: pyyaml, scipy, numpy, h5py
# Required-by:
###########linux server
# (torch) ➜ work lscpu
# Architecture: x86_64
# CPU op-mode(s): 32-bit, 64-bit
# Byte Order: Little Endian
# CPU(s): 72
# On-line CPU(s) list: 0-71
# Thread(s) per core: 2
# Core(s) per socket: 18
# Socket(s): 2
# NUMA node(s): 2
# Vendor ID: GenuineIntel
# CPU family: 6
# Model: 79
# Model name: Intel(R) Xeon(R) CPU E5-2695 v4 @ 2.10GHz
# Stepping: 1
# CPU MHz: 1244.824
# CPU max MHz: 3300.0000
# CPU min MHz: 1200.0000
# BogoMIPS: 4199.96
# Virtualization: VT-x
# L1d cache: 32K
# L1i cache: 32K
# L2 cache: 256K
# L3 cache: 46080K