import torch
import torchvision
from torch.utils.data import DataLoader
from torch.utils.data.dataset import Dataset
from torchvision.models import ResNet50_Weights
from torchvision.models.detection.rpn import AnchorGenerator
class FakeDataset(Dataset):
def __init__(self, num_keypoints, num_classes):
num_images = 800
num_instances_per_image = 3
width, height = 1536, 1536
self.images = torch.rand(num_images, 1, width, height)
self.labels = torch.randint(
0,
num_classes,
(
num_images,
num_instances_per_image,
),
)
bboxes_min = torch.rand(num_images, num_instances_per_image, 2) * width // 2
bboxes_max = bboxes_min + torch.randint(
1, width // 2, size=(num_images, num_instances_per_image, 2)
)
self.bboxes = torch.cat([bboxes_min, bboxes_max], dim=2)
self.keypoints = (
torch.rand(num_images, num_instances_per_image, num_keypoints, 2)
* width
// 2
)
self.keypoints = torch.cat(
[self.keypoints, torch.ones_like(self.keypoints)], dim=3
)
def __getitem__(self, index):
data_dict = {}
data_dict["labels"] = self.labels[index]
data_dict["boxes"] = self.bboxes[index]
data_dict["keypoints"] = self.keypoints[index]
return self.images[index], data_dict
def __len__(self):
return len(self.images)
def timer(func):
def wrapper(*args, **kwargs):
import time
start = time.time()
result = func(*args, **kwargs)
end = time.time()
print(f"Time taken to run {func.__name__}: {end - start} seconds")
return result
return wrapper
class Trainer:
def __init__(self, model, train_loader, val_loader, config):
self.model = model.to(config["device"])
self.train_loader = train_loader
self.val_loader = val_loader
self.optimizer = config["optimizer"]
self.device = config["device"]
self.num_epochs = config["num_epochs"]
self.eval_iter = 10
@timer
def train_one_epoch(self, train=True):
self.model.train()
loader = self.train_loader if train else self.val_loader
total_loss = 0
with torch.set_grad_enabled(train):
for images, targets in loader:
images = [image.to(self.device) for image in images]
targets = [
{k: v.to(self.device) for k, v in t.items()} for t in targets
]
loss_dict = self.model(images, targets)
losses = sum(loss for loss in loss_dict.values())
total_loss += losses.item()
if train:
self.optimizer.zero_grad()
losses.backward()
self.optimizer.step()
return total_loss
def train(self):
for epoch in range(1, self.num_epochs + 1):
train_loss = self.train_one_epoch(train=True)
print("Epoch: {}, Train Loss: {}".format(epoch, train_loss))
if epoch > 1 and epoch % self.eval_iter == 0:
val_loss = self.train_one_epoch(train=False)
if __name__ == "__main__":
anchor_generator = AnchorGenerator(
sizes=(32, 64, 128, 256, 512),
aspect_ratios=(0.25, 0.5, 0.75, 1.0, 2.0, 3.0, 4.0),
)
model = torchvision.models.detection.keypointrcnn_resnet50_fpn(
weights=None,
weights_backbone=ResNet50_Weights.DEFAULT,
num_keypoints=10,
# Background is the first class, object is the second class
num_classes=10,
rpn_anchor_generator=anchor_generator,
fixed_size=(512, 512),
)
dataset = FakeDataset(num_keypoints=10, num_classes=10)
data_loader = DataLoader(
dataset,
batch_size=8,
shuffle=True,
num_workers=2,
collate_fn=lambda x: tuple(zip(*x)),
)
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.001, momentum=0.9, weight_decay=0.0005)
config = {
"optimizer": optimizer,
"device": torch.device("cuda" if torch.cuda.is_available() else "cpu"),
"num_epochs": 30,
}
train_loader = data_loader
val_loader = data_loader
trainer = Trainer(model, train_loader, val_loader, config)
trainer.train()
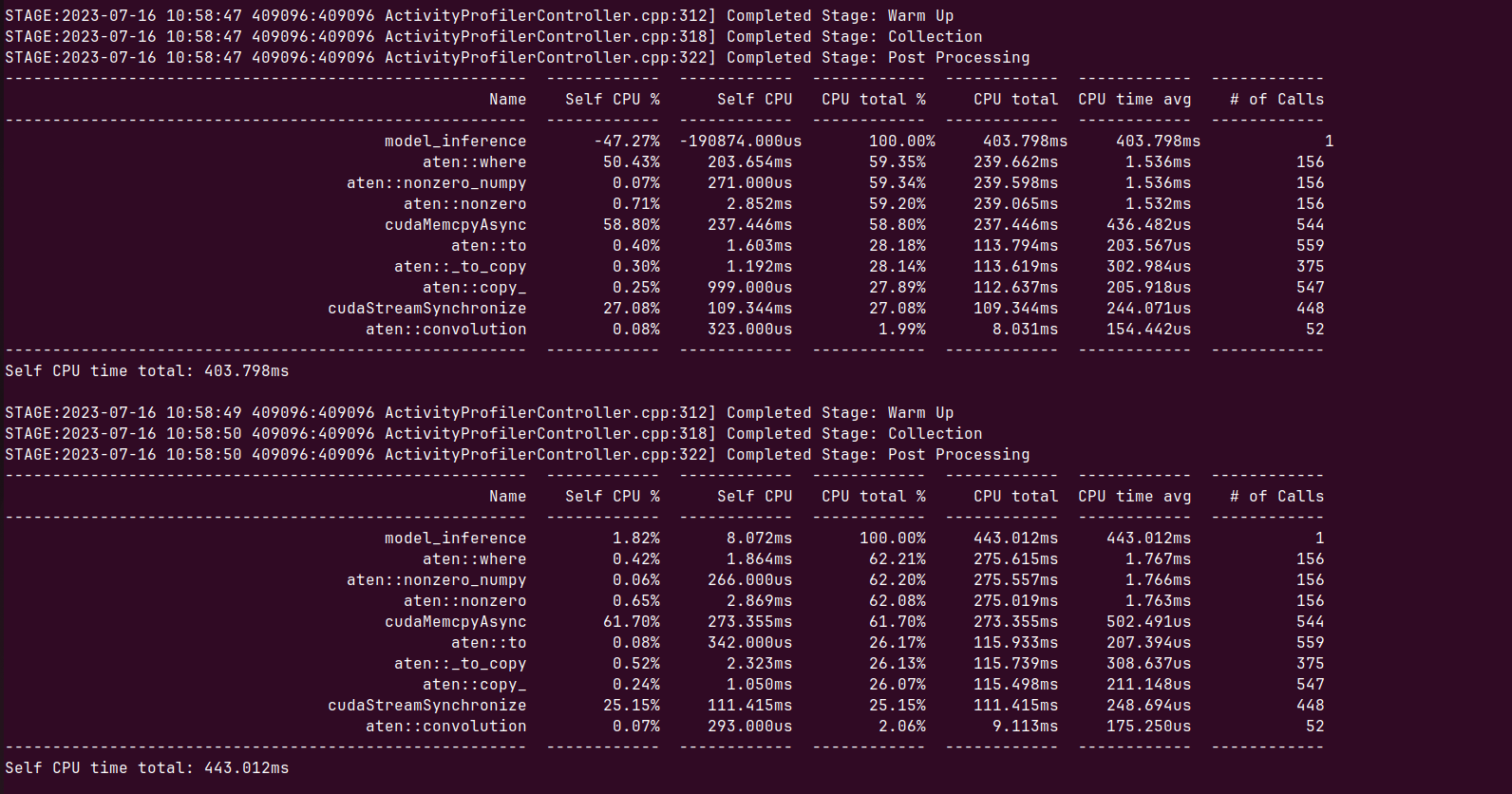
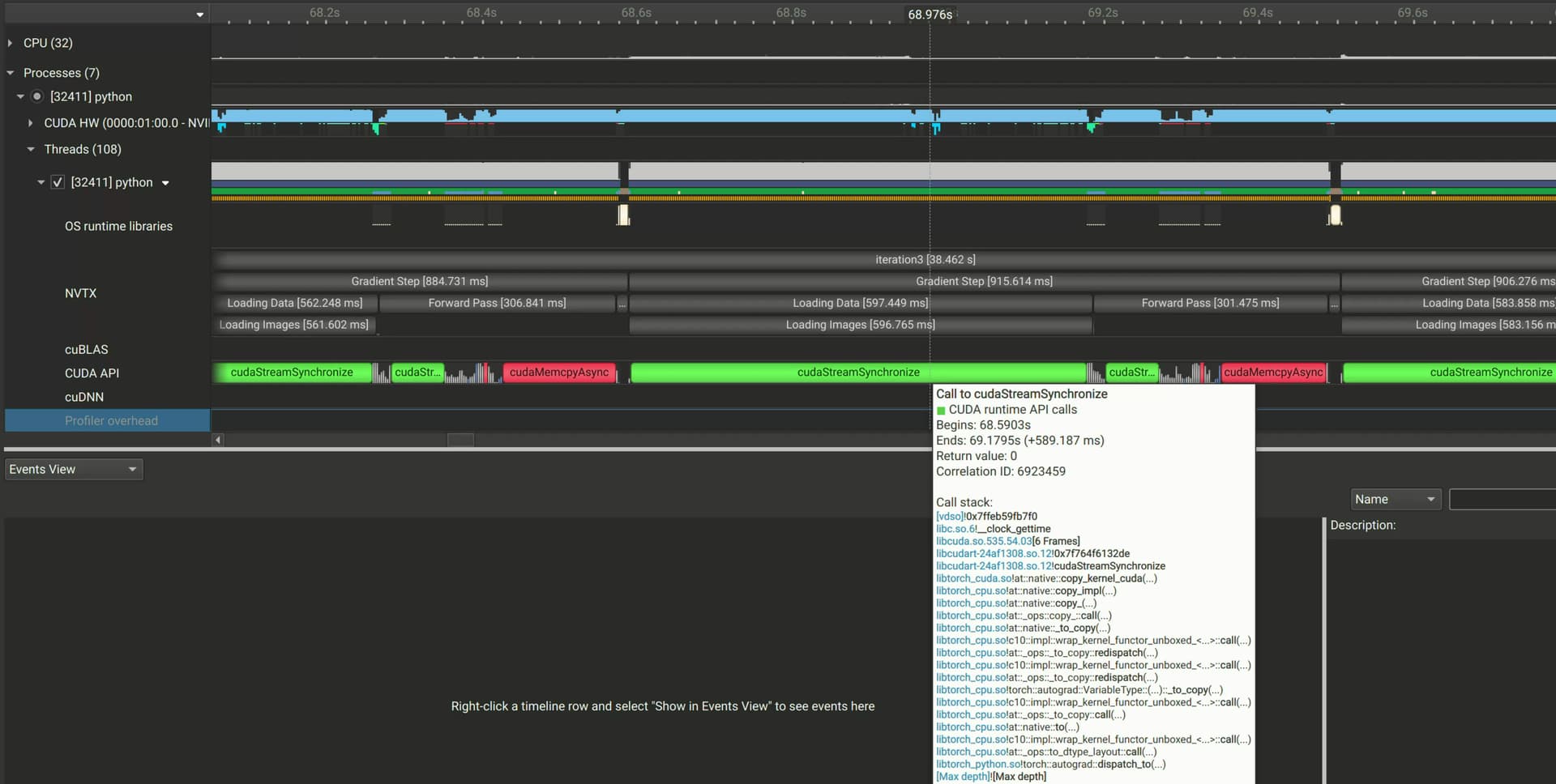
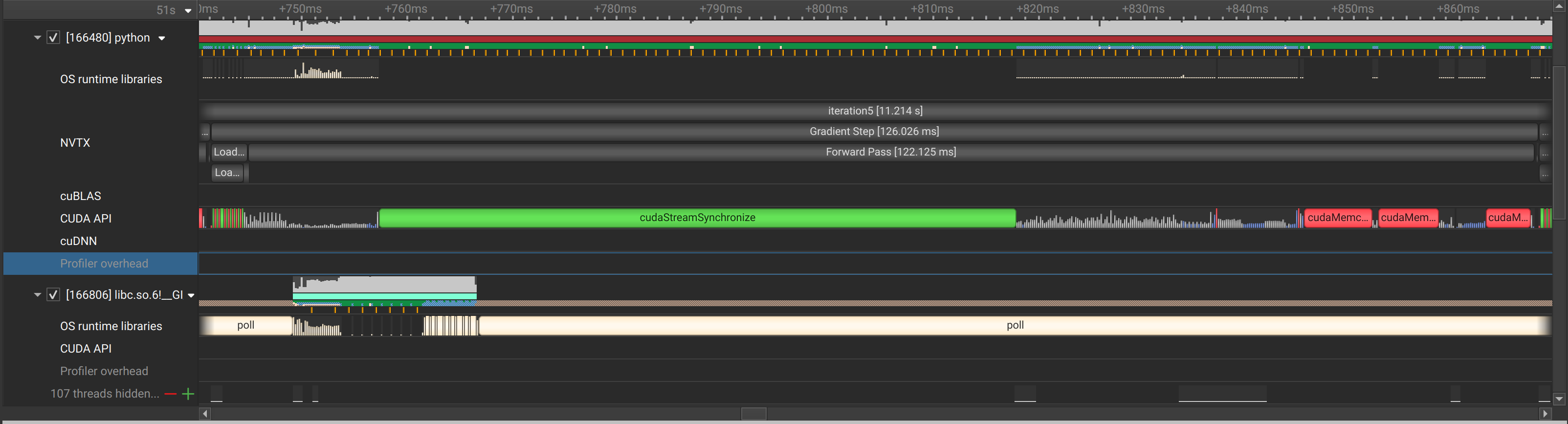
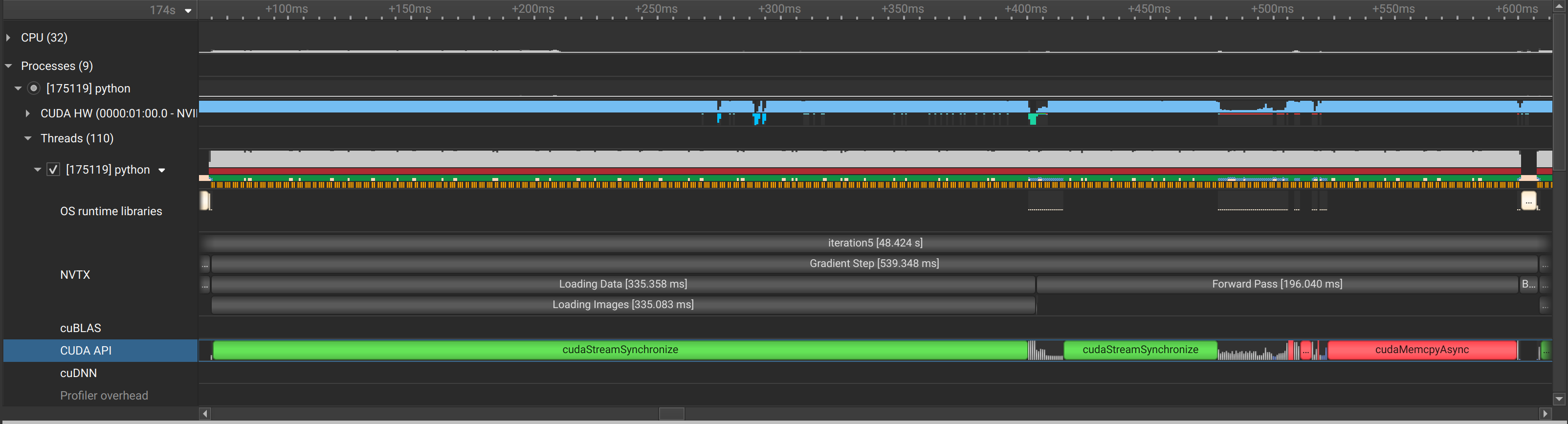
Added a random dataset too. After every epoch, the training time increases 4 seconds. Should be able to run the script as is