I found that some people use the Kullback leibler divergence loss for training their model when the output layer consists of a one-hot-vector using pytorch.
I actually tried it myself, and it works well. However I do not understand why that works. As given in the documentation, the loss over the output layer L (of length n) to my understanding is:
loss = \sum_{_i}^{n} y_i log(y_i/x_i)
with i = 0…n, y being the label and x being the estimated prob of the model. But that assumes that y_i is always > 0. Otherwise the loss would be undefined due to log(0). Therefore I do not understand how I get good results using the KLdiv loss.
Can someone explain whats going on inside the KLdiv function of pytorch? is the label smoothed such that no zeros occur anymore?
I am thankful for any advice.
Cheers,
Dennis
edit: i don’t know why the latex formatting is not working, maybe someone can fix it
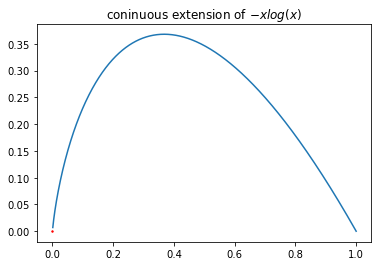
Less brief definitions of the Kullback-Leibler divergence spell out the that the term is to be considered to be 0 when log y_i is 0.
This is by continuous extension:
The PyTorch implementation uses torch.where to achieve this.
You cannot get away with x_i being zero when y_i is not, then the KL div is infinite. This is the requirement that y_i must be absolutely continuous w.r.t. x_i.
Best regards
Thomas
P.S.: One might reflect on the intended use of the formula in the PyTorch documentation: We assume that other ressources (Wikipedia, Textbooks, …) are more useful for learning about KL Divergence. The main goal is for someone who knows the formula to see which term is used how. This is particularly important for things like CrossEntropyLoss or NLLLoss, where the mathematical definition and the actual processing of the inputs to get the outputs are not quite in sync.