I asked here but got no answer. Maybe it’s a topic which is many years ago, and my question is a little bit inconsistent with the original one. So I’m sorry but ask again here.
My question is,
it is said that when regularization L2, it should only for weight parameters , but not bias parameters .(if regularization L2 is for all parameters, it’s very easy for the model to become overfitting, is it right?![]() )
)
But the L2 regularization included in most optimizers in PyTorch, is for all of the parameters in the model (weight and bias).
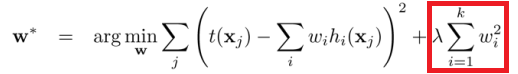
I mean the parameters in the red box should be weight parameters only. (If what I heard of is right.)
And the way to deal with it is code here:
weight_p, bias_p = [],[]
for name, p in model.named_parameters():
if 'bias' in name:
bias_p += [p]
else:
weight_p += [p]
optim.SGD(
[
{'params': weight_p, 'weight_decay':1e -5},
{'params': bias_p, 'weight_decay':0}
],
lr=1e-2, momentum=0.9
)
is it right?![]()
![]()