I am working on a lane line detection tasks. I use a strategy similar to the ones used in many papers on Lane Detection | Papers With Code.
Similar to object detection all lanes are also given by anchors. Lanes are assumed to be more or less vertical lines, starting from the bottom. In contrast to standard object detection tasks the lanes are NOT parameteized by 4 box coordinates and a class score but by the following outputs:
- class score, CrossEntropyLoss
- lane end in percentage of the vertical space of the image, SmoothL1Loss
- horizontal offsets from anchor coordinates at equally spaced positions along the vertical axis of the image (e.g. 40 offsets along an image height of 360 pixels, normalized to lie betwenn 0-1 for each element, SmoothL1Loss per element.
Now, I also want to predict the starting point of each anchor, for lanes which are not starting from the image border. For this I added another output:
- line start index in percentage of the vertical space of the image, SmoothL1Loss
The F1 score for the loss without the lane start is given in dark blue, with the lane start loss in light blue:
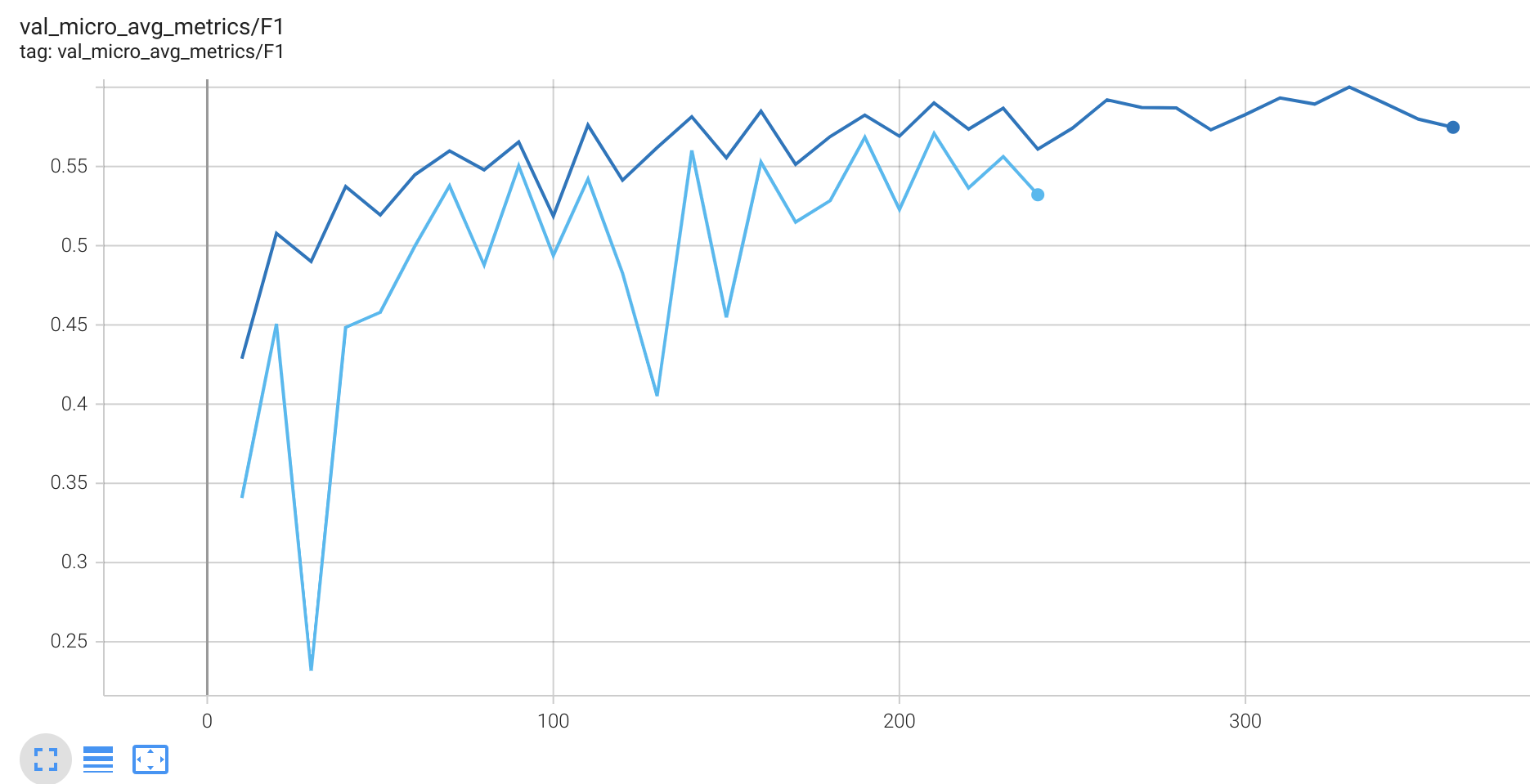
I cant get my head around the root cause for the drastically higher variance in the F1-score. What strategy could I use to mitigate this? Is there anything in pytorch that could help here. Maybe regularization?
Here is the total loss of all terms added and weighted:
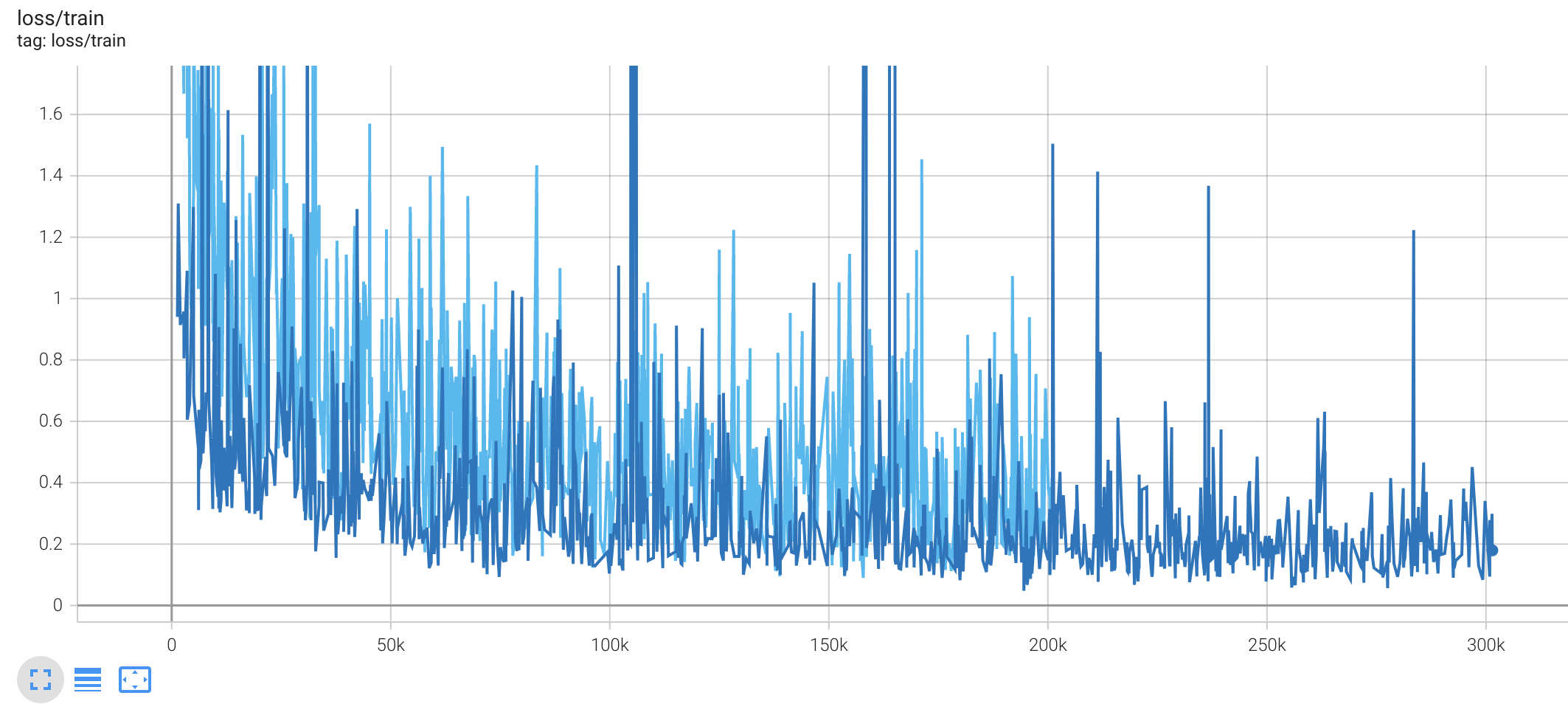
In the loss I see that in the new configurations there are more frequent but smaller jumps in the overall loss value. I assume that these jumps are due to some badly labeled data in interaction with augmentation. Does someone has some more insights/intuition for this?