I am training an LSTM to give counts of the number of items in buckets. There are 252 buckets. However, I am running into an issue with very large MSELoss that does not decrease in training (meaning essentially my network is not training). I’ve tried all types of batch sizes (4, 16, 32, 64) and learning rates (100, 10, 1, 0.1, 0.01, 0.001, 0.0001) as well as decaying the learning rate. In fact, with decaying the learning rate by 0.1, the network actually ends up giving worse loss.
The network does overfit on a very small dataset of 4 samples (giving training loss < 0.01) but on larger data sets, the loss seems to plateau around a very large loss. Code, training, and validation graphs are below. I’m relatively new to PyTorch (and deep learning in general) so I would tend to think something is wrong with my model. I’d appreciate any advice, thanks!
import torch
import statistics
from torch import nn
from helper import *
import os
import sys
import numpy as np
import pandas as pd
from torch.utils.data import Dataset, DataLoader
maxbucketlen = 252
# Number of features, equal to number of buckets
INPUT_SIZE = maxbucketlen
# Number of previous time steps taken into account
SEQ_LENGTH = 2
# Number of stacked rnn layers
NUM_LAYERS = 1
# We have a set of 144 training inputs divided into batches
BATCH_SIZE = 4
# Output Size
OUTPUT_SIZE = maxbucketlen
# Number of hidden units
HIDDEN_DIM = 256
is_cuda = torch.cuda.is_available()
# If we have a GPU available, we'll set our device to GPU. We'll use this device variable later in our code.
if is_cuda:
device = torch.device("cuda")
print("GPU is available")
else:
device = torch.device("cpu")
print("GPU not available, CPU used")
class BucketDataset(Dataset):
def __init__(self, csv_file, input_length, seq_length):
self.buckets_frame = pd.read_csv(csv_file, delim_whitespace = True)
self.seq_length = seq_length
self.input_length = input_length
def __len__(self):
return len(self.buckets_frame)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
train = self.buckets_frame.iloc[idx, :self.seq_length * self.input_length]
train = np.array([train])
target = self.buckets_frame.iloc[idx, (self.seq_length - 1) *
self.input_length:]
target = np.array([target])
# Below can be used to reshape data to sequence data
train = train.astype('float').reshape(-1, self.input_length)
target = target.astype('float').reshape(-1, self.input_length)
sample = {'train': train, 'target': target}
return sample
train_dataset = BucketDataset(file_name,
INPUT_SIZE, SEQ_LENGTH)
train_loader = DataLoader(train_dataset, batch_size = BATCH_SIZE, shuffle = True,
num_workers = 80)
class Model(nn.Module):
def __init__(self, input_size, output_size, hidden_dim, n_layers):
super(Model, self).__init__()
# Defining some parameters
self.hidden_dim = hidden_dim
self.n_layers = n_layers
#Defining the layers
# LSTM Layers
self.rnn = nn.LSTM(input_size, hidden_dim, n_layers, batch_first=True)
# Fully connected layer
self.fc = nn.Linear(hidden_dim, output_size)
def forward(self, x):
# Initializing hidden state for first input using method defined below
hidden = self.init_hidden()
# Passing in the input and hidden state into the model and obtaining outputs
out, hidden = self.rnn(x, hidden)
# Reshaping the outputs such that it can be fit into the fully connected layer
out = out.contiguous().view(-1, self.hidden_dim)
out = self.fc(out)
return out, hidden
def init_hidden(self):
# This method generates the first hidden state of zeros which we'll use in the forward pass
# We'll send the tensor holding the hidden state to the device we specified earlier as well
# Initial States
self.hidden_state = torch.randn(self.n_layers, BATCH_SIZE, self.hidden_dim, device=device)
self.cell_state = torch.randn(self.n_layers, BATCH_SIZE, self.hidden_dim, device = device)
hidden = (self.hidden_state, self.cell_state)
return hidden
# Instantiate the model with hyperparameters
model = Model(input_size=INPUT_SIZE, output_size=INPUT_SIZE, hidden_dim=HIDDEN_DIM, n_layers=NUM_LAYERS)
# We'll also set the model to the device that we defined earlier (default is CPU)
model.to(device, non_blocking=True)
# Define hyperparameters
n_epochs = 1000
lr=0.001
# Define Loss, Optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
print("Training Started")
test_dataset = BucketDataset(validation_file,
INPUT_SIZE, SEQ_LENGTH)
test_loader = DataLoader(test_dataset, batch_size = BATCH_SIZE, shuffle = False,
num_workers = 24)
def predict(model, counts):
out, hidden = model(counts)
return out, hidden
# Training Run
for epoch in range(1, n_epochs + 1):
for j, data in enumerate(train_loader):
for param in model.parameters():
param.grad = None
output, hidden = model(data['train'].cuda().float())
loss = criterion(output.flatten(), data['target'].cuda().float().flatten())
loss.backward() # Does backpropagation and calculates gradients
optimizer.step() # Updates the weights accordingly
# Perform validation
for k, data_test in enumerate(test_loader):
with torch.no_grad():
counts, h = predict(model, data_test["train"].cuda().float())
val_loss = criterion(counts.flatten(), data_test['target'].cuda().float().flatten())
if epoch % 5 == 0:
print('Epoch: {}/{}.............'.format(epoch, n_epochs), end=' ')
print("Training Loss: {:.4f}".format(loss.item()))
print("Validation Loss: {:.4f}".format(val_loss.item()))
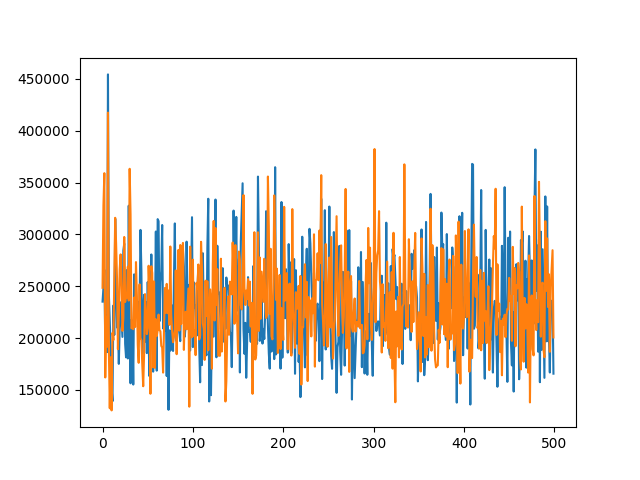
Training and Validation Loss graphs:
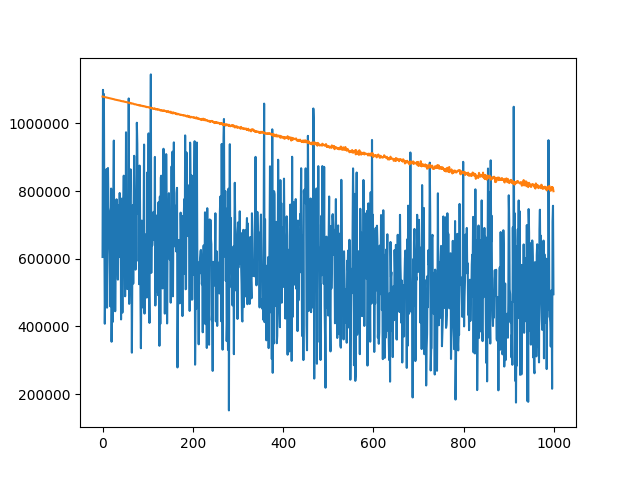
The orange line is the validation loss and the blue line is the training loss. The loss function is MSELoss and the optimizer is Adam.