Hi there,
I’m building a 3D U-Net for medical image segmentation and am seeing an OOM error for large input sizes when hitting one layer of the model in particular. The layer is a Conv3D acting on a large input tensor (1, 64, 370, 370, 250) - this input tensor is a concatenation of the residual feature maps (32 channels) and the upsampled feature maps (32 channels).
I have isolated the layer in question and created a script that reproduces the error. I’m running the script on an NVIDIA A100 GPU with 80GB memory. Note that the script starts a thread to measure GPU usage alongside the layer operation.
Versions:
cuda: 11.7
python: 3.8.6
torch: 1.13.1
Script:
from datetime import datetime
import numpy as np
import os
import pandas as pd
from pynvml.smi import nvidia_smi
from threading import Thread
from time import sleep
import torch
from torch import nn
def record_gpu_usage(
name: str,
time: float,
interval: float) -> None:
# Create results table.
nvsmi = nvidia_smi.getInstance()
n_gpus = len(nvsmi.DeviceQuery('gpu_name')['gpu'])
cols = {
'time': str
}
for i in range(n_gpus):
device_name = f'cuda:{i}'
cols[f'{device_name}-usage'] = float
df = pd.DataFrame(columns=cols.keys())
# Add usage.
n_intervals = int(np.ceil(time / interval))
start_time = datetime.now()
for i in range(n_intervals):
# Record GPU usage.
data = {
'time': (datetime.now() - start_time).total_seconds()
}
usages_mb = [g['fb_memory_usage']['used'] for g in nvsmi.DeviceQuery('memory.used')['gpu']]
for j, usage_mb in enumerate(usages_mb):
device_name = f'cuda:{j}'
data[f'{device_name}-usage'] = usage_mb
df = pd.concat((df, pd.DataFrame([data])), axis=0)
# Wait for time interval to pass.
time_passed = (datetime.now() - start_time).total_seconds()
if time_passed > time:
break
time_to_wait = ((i + 1) * interval) - time_passed
if time_to_wait > 0:
sleep(time_to_wait)
elif time_to_wait < 0:
# Makes time problem worse if we log.
# logging.warning(f"GPU usage recording took longer than allocated interval '{interval}' (seconds).")
pass
# Save results.
filepath = f'{name}.csv'
df.to_csv(filepath, index=False)
n_channels = 64
name = f'testing-{n_channels}'
input_shape = (1, n_channels, 370, 370, 250)
device = torch.device('cuda:0')
input = torch.rand(input_shape)
# Kick off GPU memory recording.
thread = Thread(target=record_gpu_usage, args=(name, 10, 1e-3))
thread.start()
input = input.half().to(device)
input_GB = input.numel() * input.element_size() / 1e9
print('input GB: ', input_GB)
input.requires_grad = False
layer = nn.Conv3d(in_channels=n_channels, out_channels=32, kernel_size=3, stride=1, padding=1).half().to(device)
for i, param in enumerate(layer.parameters()):
param_GB = param.numel() * param.element_size() / 1e9
print(f'param_{i} GB: {param_GB}')
param.requires_grad = False
output = layer(input)
torch.cuda.empty_cache()
Plotting script:
from matplotlib import pyplot as plt
import pandas as pd
def plot_gpu_usage(name: str) -> None:
filepath = f'{name}.csv'
df = pd.read_csv(filepath)
x = df['time']
n_gpus = len(df.columns) - 1
for i in range(n_gpus):
device_name = f'cuda:{i}'
key = f'{device_name}-usage'
y = df[key]
plt.plot(x, y, label=key)
plt.title(name)
plt.xlabel('time [seconds]')
plt.ylabel('GPU usage [MB]')
plt.show()
Error:
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 110.16 GiB (GPU 0; 79.21 GiB total capacity; 6.12 GiB already allocated; 72.55 GiB free; 6.12 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
The amount that PyTorch is trying to allocate (110.16GB) seems very large. I varied the number of input channels (n_channels) from 32 to 64. At n_channels=62, the convolution operation consumes a maximum of ~ 14GB. When n_channels>=63 the memory consumption spikes by nearly 10x. Figures show memory usage over time for n_channels=32,40,48,56,62.
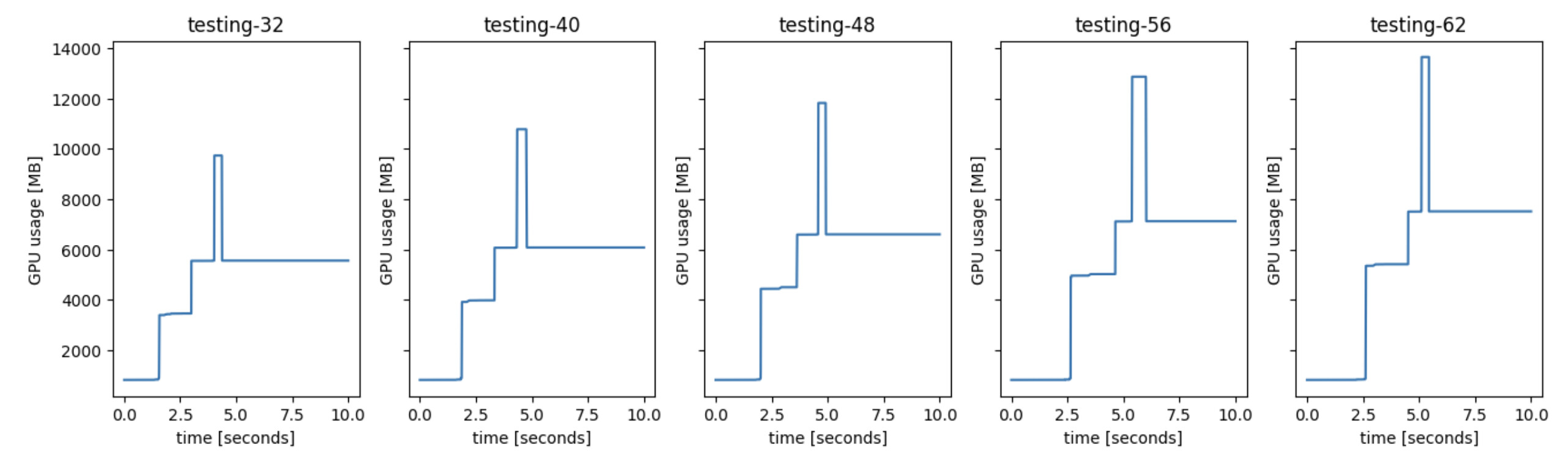
Any ideas why the memory usage increases by such a large margin for a small increase in n_channels? I’ve tried running with PYTORCH_NO_CUDA_MEMORY_CACHING=1 and this didn’t affect the amount of memory requested.
Thanks!
Brett