Сan i make a convolution of the layer like in the picture?
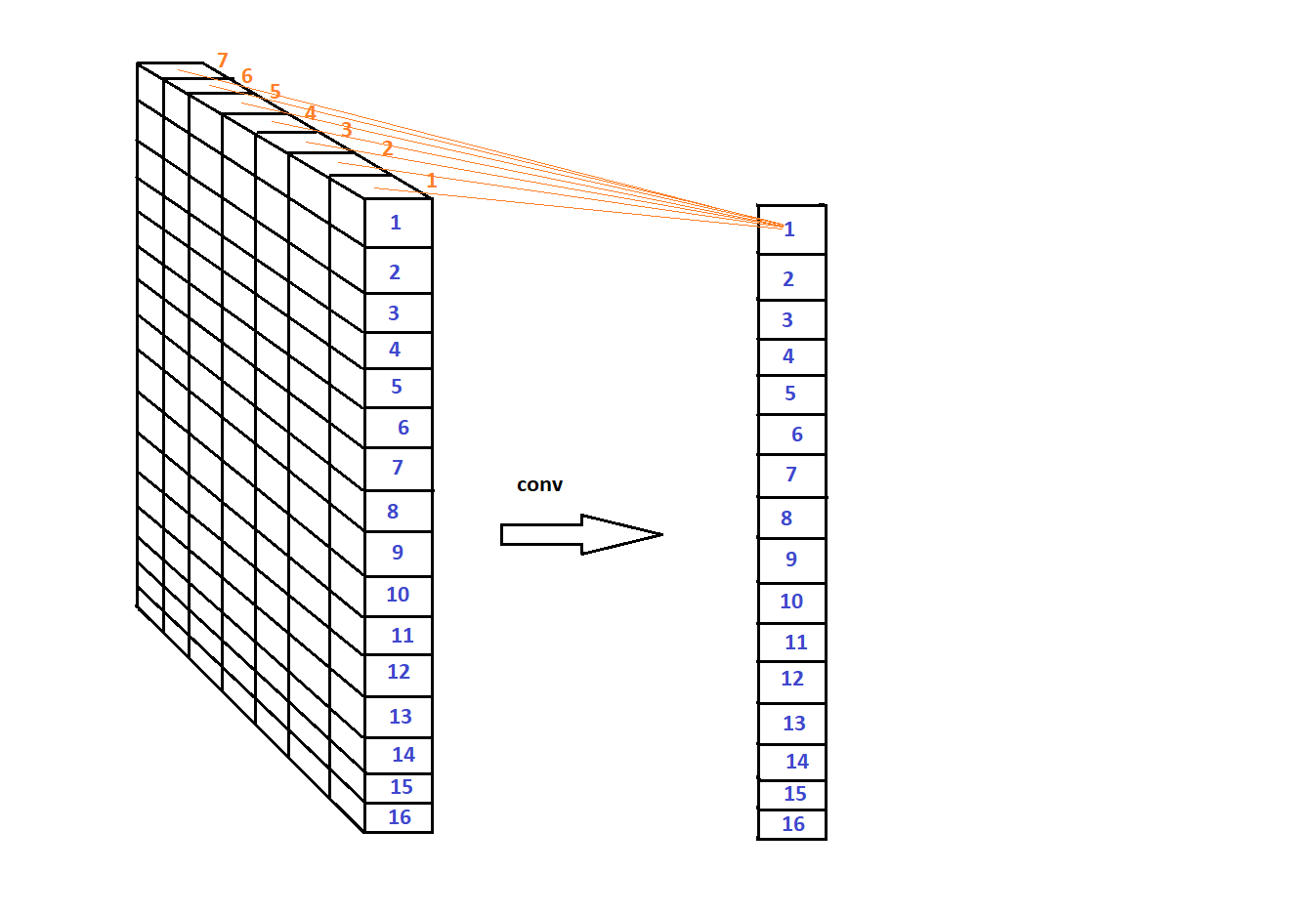
You could use a linear layer or a conv layer with a specific kernel size:
x = torch.randn(1, 16, 7)
lin = nn.Linear(7, 1, bias=False)
output = lin(x)
conv = nn.Conv2d(1, 1, kernel_size=(1, 7), stride=(1, 1), bias=False)
with torch.no_grad():
conv.weight.copy_(lin.weight.unsqueeze(1).unsqueeze(2))
x_conv = x.unsqueeze(1)
output_conv = conv(x_conv)
print(torch.allclose(output, output_conv.squeeze(1)))
I do not understand why we do it:
with torch.no_grad():
conv.weight.copy_(lin.weight.unsqueeze(1).unsqueeze(2))
x_conv = x.unsqueeze(1)
output_conv = conv(x_conv)
this way will not work?:
conv = nn.Conv2d(1, 1, kernel_size=(1, 7), stride=(1, 1), bias=False)
output = conv(x)
I understood, conv2d takes 4 parameters
It will work. I just used this code snippet to set the weights according to the linear layer’s, so that we can make sure both results are equal.
Of course you don’t have to set the weights manually.
if you do this (print(output_conv(x)):
RuntimeError: Expected 4-dimensional input for 4-dimensional weight 1 1 1, but got 3-dimensional input of size [1, 16, 7] instead
output_conv is the result of the convolution so I assume you are using conv instead.
As shown in my code, you would have to unsqueeze x in dim1.
How can I use a transformer instead of conv?
I have a sequence of 16 inputs. Kadzhi entrance has a length of 7.
To use trabsformer I have to specify src and tgt. I can’t understand how src and tgt should look. I can assume that src = 7, but what is tgt?