I code a function which implements some operations including torch.mm, torch.index_select and torch.cc. However, there comes out an AssertionError, leaf variable was used in an inplace operation.
In the source code of Variable.py(line 199), I found the assertion, assert self.__version == 0. But it’s not clear to say what is going wrong here. Could anyone help me on this?
Loosely, tensors you create directly are leaf variables. Tensors that are the result of a differentiable operation are not leaf variables
For example:
w = torch.tensor([1.0, 2.0, 3.0]) # leaf variable
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) # also leaf variable
y = x + 1 # not a leaf variable
(The PyTorch documentation for is_leaf contains a more precise definition.)
An in-place operation is something which modifies the data of a variable. For example:
x += 1 # in-place
y = x + 1 # not in place
PyTorch doesn’t allow in-place operations on leaf variables that have requires_grad=True (such as parameters of your model) because the developers could not decide how such an operation should behave. If you want the operation to be differentiable, you can work around the limitation by cloning the leaf variable (or use a non-inplace version of the operator).
That depends on the situation.
For example to initialize or update parameters, assigning to .data is the way to go. Usually, you cannot backprop when changing Variables’ .data in the middle of a forward pass…
I’d summerise my experience as “don’t do it unless you have reason to believe its the rigght thing”.
Yes, I remember now, messing with backprop and autograd was why I was running into problems with in-place assignment before. Using .data as I am currently for initialising word embeddings seems ok then.
Trying to read the code for optim (I want to implement something a bit differently) and your previous example/explanation of what is a leaf Variable doesn’t seem to be valid anymore.
In particular,
you wrote
y = x + 1 # not a leaf variable
Well, here’s output from my termial for the code which you have mentioned:
>>> x = torch.autograd.Variable(torch.Tensor([1, 2, 3, 4]))
>>> x.is_leaf
True
>>> y = x + 1
>>> y.is_leaf
True
>>> y
Variable containing:
2
3
4
5
[torch.FloatTensor of size (4,)]
So, can someone please explain what is a leaf Variable, and what is not a leaf variable? Clearly a non-leaf-variable cannot be optimized, but what is it?
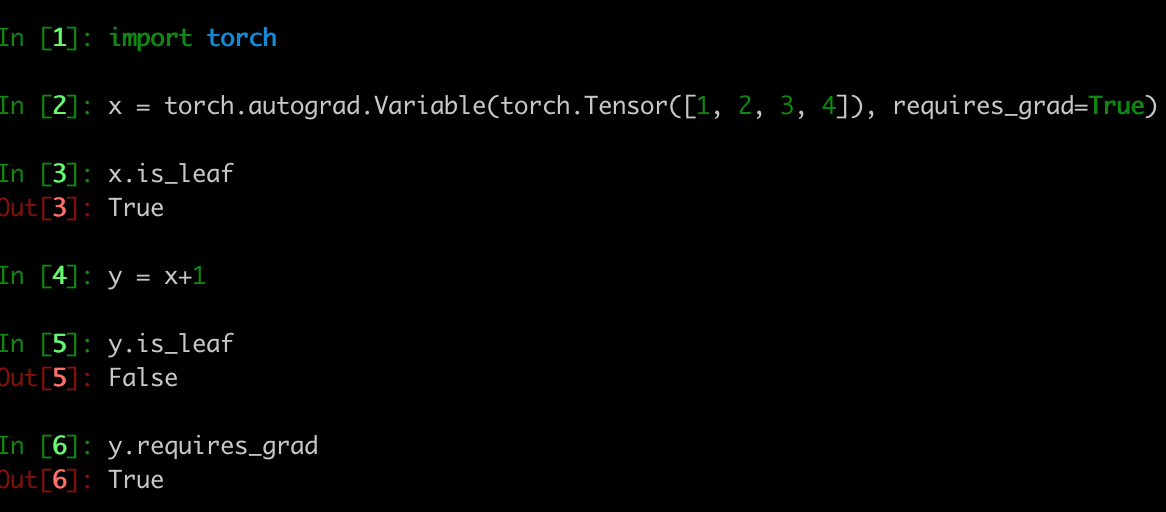
Came across a similar issue. Reason is requires grad.
x = torch.autograd.Variable(torch.Tensor([1, 2, 3, 4]), requires_grad=True)
x.is_leaf
#True
y = x + 1
y.is_leaf
#False
y = torch.autograd.Variable(torch.zeros([batch_size, c, h, w]), requires_grad=True)
Then I want to assign value to indexed parts of y like below,(y_local is a Variable computed based on other variables and I want to assign the value of y_local to part of the y and ensure that the gradients from y can flow to the y_local.)
leaf variable, in essence, is a variable, or a tensor with requires_grad=True. So, if a tensor with requires_grad=False, it does not belong to the variable, let alone leaf variable.
Is the reason this is not “usually correct” because we could have just initialized it directly with the data that we wanted in the first place instead of doing a in-place op?
@pinocchio, I’m updating my reply and correcting the example. The not “usually correct” wasn’t a good explanation. The actual reason is that the PyTorch developers could not come to a consensus on reasonable semantics for such an operation.
I think you are wrong, y is indeed not a leaf. Maybe you had a weird version of Pytorch?
def inplace_playground():
import torch
x = torch.tensor([1,2,3.], requires_grad=True)
y = x + 1
print(f'x.is_leaf = {x.is_leaf}')
print(f'y.is_leaf = {y.is_leaf}')
x += 1
output:
x.is_leaf = True
y.is_leaf = False
@colesbury I think you were correct. Not sure what you corrected but I tried the leaf thing and it seems your right that y is not a leaf (as expected).