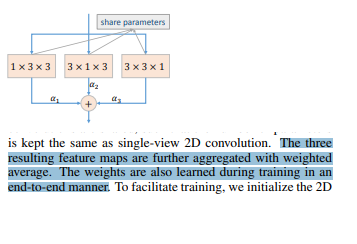
print(w) after self.avg_pool gives me like this:
tensor([0.1944, 0.0687, 0.7370], device=‘cuda:0’, grad_fn=)
tensor([0.1981, 0.1346, 0.6673], device=‘cuda:0’, grad_fn=)
tensor([0.2181, 0.4030, 0.3789], device=‘cuda:0’, grad_fn=)
tensor([0.6972, 0.2325, 0.0704], device=‘cuda:0’, grad_fn=)
tensor([0.0573, 0.0222, 0.9205], device=‘cuda:0’, grad_fn=)
tensor([0.0967, 0.6594, 0.2438], device=‘cuda:0’, grad_fn=)
tensor([0.0540, 0.3833, 0.5628], device=‘cuda:0’, grad_fn=)
tensor([0.1071, 0.8304, 0.0625], device=‘cuda:0’, grad_fn=)
tensor([0.1369, 0.1455, 0.7176], device=‘cuda:0’, grad_fn=)
tensor([0.1141, 0.6166, 0.2694], device=‘cuda:0’, grad_fn=)
tensor([0.5121, 0.3077, 0.1802], device=‘cuda:0’, grad_fn=)
tensor([0.6380, 0.2686, 0.0934], device=‘cuda:0’, grad_fn=)
tensor([0.3382, 0.1036, 0.5582], device=‘cuda:0’, grad_fn=)
tensor([0.1021, 0.3302, 0.5676], device=‘cuda:0’, grad_fn=)
tensor([0.0386, 0.6035, 0.3578], device=‘cuda:0’, grad_fn=)
tensor([0.1217, 0.5602, 0.3181], device=‘cuda:0’, grad_fn=)
Epoch: [0][0/43008], lr: 0.00500 Time 3.649 (3.649) Data 0.115 (0.115) Loss 5.1573 (5.1573) Prec@1 0.000 (0.000) Prec@5 0.000 (0.000)
tensor([0.1944, 0.0687, 0.7370], device=‘cuda:0’, grad_fn=)
tensor([0.1981, 0.1346, 0.6673], device=‘cuda:0’, grad_fn=)
tensor([0.2181, 0.4030, 0.3789], device=‘cuda:0’, grad_fn=)
tensor([0.6972, 0.2325, 0.0704], device=‘cuda:0’, grad_fn=)
tensor([0.0573, 0.0222, 0.9205], device=‘cuda:0’, grad_fn=)
tensor([0.0967, 0.6594, 0.2438], device=‘cuda:0’, grad_fn=)
tensor([0.0540, 0.3833, 0.5628], device=‘cuda:0’, grad_fn=)
tensor([0.1071, 0.8304, 0.0625], device=‘cuda:0’, grad_fn=)
tensor([0.1369, 0.1455, 0.7176], device=‘cuda:0’, grad_fn=)
tensor([0.1141, 0.6166, 0.2694], device=‘cuda:0’, grad_fn=)
tensor([0.5121, 0.3077, 0.1802], device=‘cuda:0’, grad_fn=)
tensor([0.6380, 0.2686, 0.0934], device=‘cuda:0’, grad_fn=)
tensor([0.3382, 0.1036, 0.5582], device=‘cuda:0’, grad_fn=)
tensor([0.1021, 0.3302, 0.5676], device=‘cuda:0’, grad_fn=)
tensor([0.0386, 0.6035, 0.3578], device=‘cuda:0’, grad_fn=)
tensor([0.1217, 0.5602, 0.3181], device=‘cuda:0’, grad_fn=)
tensor([0.1944, 0.0687, 0.7370], device=‘cuda:0’, grad_fn=)
tensor([0.1981, 0.1346, 0.6673], device=‘cuda:0’, grad_fn=)
tensor([0.2181, 0.4030, 0.3789], device=‘cuda:0’, grad_fn=)
tensor([0.6972, 0.2325, 0.0704], device=‘cuda:0’, grad_fn=)
tensor([0.0573, 0.0222, 0.9205], device=‘cuda:0’, grad_fn=)
tensor([0.0967, 0.6594, 0.2438], device=‘cuda:0’, grad_fn=)
tensor([0.0540, 0.3833, 0.5628], device=‘cuda:0’, grad_fn=)
tensor([0.1071, 0.8304, 0.0625], device=‘cuda:0’, grad_fn=)
tensor([0.1369, 0.1455, 0.7176], device=‘cuda:0’, grad_fn=)
tensor([0.1141, 0.6166, 0.2694], device=‘cuda:0’, grad_fn=)
tensor([0.5121, 0.3077, 0.1802], device=‘cuda:0’, grad_fn=)
tensor([0.6380, 0.2686, 0.0934], device=‘cuda:0’, grad_fn=)
tensor([0.3382, 0.1036, 0.5582], device=‘cuda:0’, grad_fn=)
tensor([0.1021, 0.3302, 0.5676], device=‘cuda:0’, grad_fn=)
tensor([0.0386, 0.6035, 0.3578], device=‘cuda:0’, grad_fn=)
tensor([0.1217, 0.5602, 0.3181], device=‘cuda:0’, grad_fn=)
tensor([0.1944, 0.0687, 0.7370], device=‘cuda:0’, grad_fn=)
tensor([0.1981, 0.1346, 0.6673], device=‘cuda:0’, grad_fn=)
tensor([0.2181, 0.4030, 0.3789], device=‘cuda:0’, grad_fn=)
tensor([0.6972, 0.2325, 0.0704], device=‘cuda:0’, grad_fn=)
tensor([0.0573, 0.0222, 0.9205], device=‘cuda:0’, grad_fn=)
tensor([0.0967, 0.6594, 0.2438], device=‘cuda:0’, grad_fn=)
tensor([0.0540, 0.3833, 0.5628], device=‘cuda:0’, grad_fn=)
tensor([0.1071, 0.8304, 0.0625], device=‘cuda:0’, grad_fn=)
tensor([0.1369, 0.1455, 0.7176], device=‘cuda:0’, grad_fn=)
tensor([0.1141, 0.6166, 0.2694], device=‘cuda:0’, grad_fn=)
tensor([0.5121, 0.3077, 0.1802], device=‘cuda:0’, grad_fn=)
tensor([0.6380, 0.2686, 0.0934], device=‘cuda:0’, grad_fn=)
tensor([0.3382, 0.1036, 0.5582], device=‘cuda:0’, grad_fn=)
tensor([0.1021, 0.3302, 0.5676], device=‘cuda:0’, grad_fn=)
tensor([0.0386, 0.6035, 0.3578], device=‘cuda:0’, grad_fn=)
tensor([0.1217, 0.5602, 0.3181], device=‘cuda:0’, grad_fn=)
tensor([0.1944, 0.0687, 0.7370], device=‘cuda:0’, grad_fn=)
tensor([0.1981, 0.1346, 0.6673], device=‘cuda:0’, grad_fn=)
tensor([0.2181, 0.4030, 0.3789], device=‘cuda:0’, grad_fn=)
tensor([0.6972, 0.2325, 0.0704], device=‘cuda:0’, grad_fn=)
tensor([0.0573, 0.0222, 0.9205], device=‘cuda:0’, grad_fn=)
tensor([0.0967, 0.6594, 0.2438], device=‘cuda:0’, grad_fn=)
tensor([0.0540, 0.3833, 0.5628], device=‘cuda:0’, grad_fn=)
tensor([0.1071, 0.8304, 0.0625], device=‘cuda:0’, grad_fn=)
tensor([0.1369, 0.1455, 0.7176], device=‘cuda:0’, grad_fn=)
tensor([0.1141, 0.6166, 0.2694], device=‘cuda:0’, grad_fn=)
tensor([0.5121, 0.3077, 0.1802], device=‘cuda:0’, grad_fn=)
tensor([0.6380, 0.2686, 0.0934], device=‘cuda:0’, grad_fn=)
tensor([0.3382, 0.1036, 0.5582], device=‘cuda:0’, grad_fn=)
tensor([0.1021, 0.3302, 0.5676], device=‘cuda:0’, grad_fn=)
tensor([0.0386, 0.6035, 0.3578], device=‘cuda:0’, grad_fn=)
tensor([0.1217, 0.5602, 0.3181], device=‘cuda:0’, grad_fn=)
tensor([0.1944, 0.0687, 0.7370], device=‘cuda:0’, grad_fn=)
tensor([0.1981, 0.1346, 0.6673], device=‘cuda:0’, grad_fn=)
tensor([0.2181, 0.4030, 0.3789], device=‘cuda:0’, grad_fn=)
tensor([0.6972, 0.2325, 0.0704], device=‘cuda:0’, grad_fn=)
tensor([0.0573, 0.0222, 0.9205], device=‘cuda:0’, grad_fn=)
tensor([0.0967, 0.6594, 0.2438], device=‘cuda:0’, grad_fn=)
tensor([0.0540, 0.3833, 0.5628], device=‘cuda:0’, grad_fn=)
tensor([0.1071, 0.8304, 0.0625], device=‘cuda:0’, grad_fn=)
tensor([0.1369, 0.1455, 0.7176], device=‘cuda:0’, grad_fn=)
tensor([0.1141, 0.6166, 0.2694], device=‘cuda:0’, grad_fn=)
tensor([0.5121, 0.3077, 0.1802], device=‘cuda:0’, grad_fn=)
tensor([0.6380, 0.2686, 0.0934], device=‘cuda:0’, grad_fn=)
tensor([0.3382, 0.1036, 0.5582], device=‘cuda:0’, grad_fn=)
tensor([0.1021, 0.3302, 0.5676], device=‘cuda:0’, grad_fn=)
tensor([0.0386, 0.6035, 0.3578], device=‘cuda:0’, grad_fn=)
tensor([0.1217, 0.5602, 0.3181], device=‘cuda:0’, grad_fn=)
…