Hi, I want to define custom layer with a learnable parameter T.
The function behaves like below:
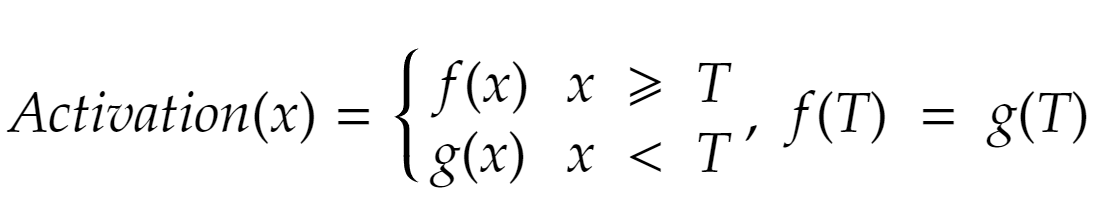
here, x is the layer’s input, and T is a learnable parameter.
I am thinking of defining my own autograd function something like below
class _NewActivation(torch.autograd.Function):
@staticmethod
def forward(ctx, x, T):
ctx.save_for_backward(x,T)
# ret = f(x) for x>=T, g(x) for x <T
# return ret
@staticmethod
def backward(ctx, grad_output):
x, T = ctx.saved_tensors
# compute_grad will compute grad_output * d_Activation/d_input
return compute_grad(x, T, grad_output)
And then add above function into my model by wrapping inside torch.nn.Module somthing like below.
class NewActivation(torch.nn.Module):
def __init__(self):
super().__init__()
self.T=Parameter(torch.Tensor([[0]]))
self.activation = _NewActivation.apply
def forward(self, x):
return activation(x)
My question is, I don’t know how to make the T learnable. I think I shoud add another torch.autograd.Function to compute gradient of d_Activation/d_T, but I have no idea.
