Hi,
I’m trying to implement a bidirectional character level LSTM model.
The inputs consist of one hot encoded sequences and each element of that sequence has a corresponding target class. I’m using CrossEntropyLoss and Adam() as optimizer. In order to be able to use CrossEntropyLoss I’m reshaping the output tensor and removing padded elements using a mask to have the shape of (all_sequence_elements,number_of_output_features). I’m also removing padded elements (0’s) from the target tensor so it ends up being a 1D vector consisting of values corresponding to each input element.
I tried to run the model on a very small dataset but the learning is pretty slow even for lr=0.01 for 1 batch and the loss is very high for multiple batches and fluctuates a lot.
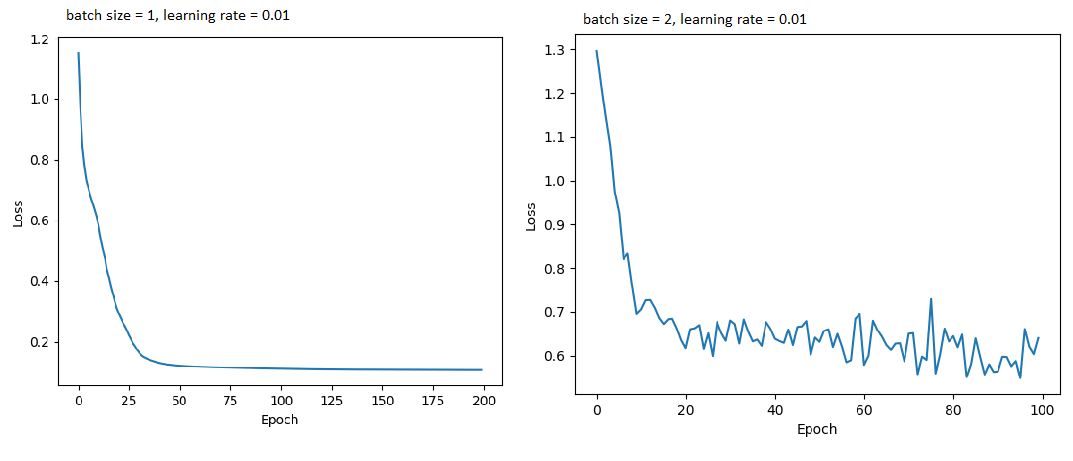
Code:
optimizer.zero_grad()
output, (hn, cn) = rnn(input_tensor, (h0, c0)) #output(max_sequence_len,batch_size,out_features*2)
mask = (target_tensor != 0)
target = target_tensor[mask] #target(targets_from_all_sequences_combined)
output = (output[:, :, :hidden_size] + output[:, :, hidden_size:]) # sum of both directions
output = output.view(-1, n_output_letters)
output = output[mask.view(-1)]
loss = criterion(output, target)
loss.backward()
optimizer.step()
I made sure that there’s no mistakes in my input and target tensors.
Please let me know if I’m doing something wrong.
Thanks.