It seems like regularisation in combination with learning rate might be the key factor here but it seems like it requires a lot of playing around in order to find the right values.
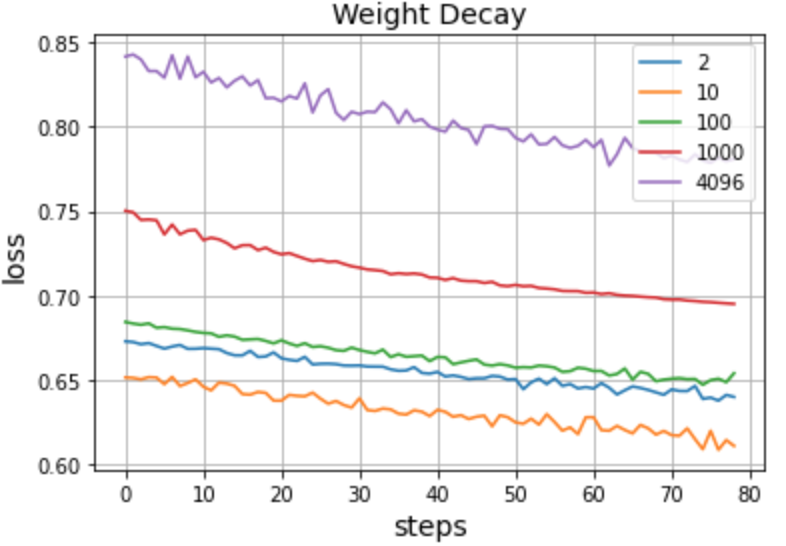
Would be curious to see what happens with more steps (maybe you can keep looping over the same data for a few more epochs) since it’s possible this is just nicely converging to those stagnation limits from before ![]()
Btw, conceptually I do think dropout layers must set some nonzero floor on the training loss from the large feature input version. However, as I mentioned, I experimented with removing them and the chart looked the same.
You’re right about this!
There’s definitely something going on here which I still haven’t grasped yet. Compared to logistic regression even though the large feature space seems to be converging yet it reaches a stagnation point at loss 0.70.
Even if it learned the constant prediction f(x) = 0.125 (which is the average output over the inputs) it would do a lot better than 0.70, so something fishy is definitely going on.