I’m trying to fit an MLP on tabular sparse data but from monitoring the loss it seems that there’s no learning happening

Any ideas what might be going wrong?
Could you share more of your code, ideally a minimal reproducible snippet that has this issue? There could be a lot of different reasons why this is happening and without seeing some code it’s hard to diagnose it.
Sure thing,
the code for loading data is taken from this thread.
What I can’t provide is the actual dataset.
Here’s an example:
class SparseDataset(tud.Dataset):
"""
Custom Dataset class for scipy sparse matrix
"""
def __init__(self, data:Union[np.ndarray, sps.coo_matrix, sps.csr_matrix],
targets:Union[np.ndarray, sps.coo_matrix, sps.csr_matrix],
transform:bool = None):
# Transform data coo_matrix to csr_matrix for indexing
if type(data) == sps.coo_matrix:
self.data = data.tocsr()
else:
self.data = data
# Transform targets coo_matrix to csr_matrix for indexing
if type(targets) == sps.coo_matrix:
self.targets = targets.tocsr()
else:
self.targets = targets
self.transform = transform # Can be removed
def __getitem__(self, index:int):
return self.data[index], self.targets[index]
def __len__(self):
return self.data.shape[0]
def sparse_coo_to_tensor(coo:sps.coo_matrix):
"""
Transform scipy coo matrix to pytorch sparse tensor
"""
values = coo.data
indices = np.vstack((coo.row, coo.col))
shape = coo.shape
i = torch.LongTensor(indices)
v = torch.FloatTensor(values)
s = torch.Size(shape)
return torch.sparse.FloatTensor(i, v, s)
def sparse_batch_collate(batch:list):
"""
Collate function which to transform scipy coo matrix to pytorch sparse tensor
"""
data_batch, targets_batch = zip(*batch)
if type(data_batch[0]) == sps.csr_matrix:
data_batch = sps.vstack(data_batch).tocoo()
data_batch = sparse_coo_to_tensor(data_batch)
else:
data_batch = torch.FloatTensor(data_batch)
if type(targets_batch[0]) == sps.csr_matrix:
targets_batch = sps.vstack(targets_batch).tocoo()
targets_batch = sparse_coo_to_tensor(targets_batch)
else:
targets_batch = torch.FloatTensor(targets_batch)
return data_batch, targets_batch
class MLP(nn.Module):
def __init__(self, in_dim, num_classes=2):
super(LogisticRegression, self).__init__()
self.in_dim = in_dim
self.num_classes = num_classes
self.l1 = nn.Linear(in_dim, 2048)
self.d1 = nn.Dropout(p=0.5)
self.l2 = nn.Linear(2048, 1024)
self.l3 = nn.Linear(1024, 512)
self.m1 = nn.MaxPool1d(kernel_size=2, stride=2)
self.l4 = nn.Linear(256, 128)
self.l5 = nn.Linear(128, 64)
self.m2 = nn.MaxPool1d(kernel_size=2, stride=2)
self.l6 = nn.Linear(32, 16)
self.l7 = nn.Linear(16, 8)
self.l8 = nn.Linear(8, num_classes)
def forward(self, x):
x = self.l1(x)
x = self.d1(x)
x = self.l2(x).relu_()
x = self.l3(x)
x = self.m1(x.unsqueeze(dim=1))
x = self.l4(x.squeeze())
x = self.l5(x)
x = self.m2(x.unsqueeze(dim=1))
x = self.l6(x.squeeze())
x = self.l7(x).relu_()
x = self.l8(x)
return x
def criterion(model, x, y):
y_hat = model(x)
prob = torch.sigmoid(y_hat)[:, 1]
return nn.BCELoss(reduction='mean')(prob, y), y_hat
X = sps.random(80000, 4096, density=0.25)
y = np.arange(80000)
dset = SparseDataset(X, y)
loader = tud.DataLoader(dset, batch_size=512, collate_fn=sparse_batch_collate)
Training proceed as usual......
Where is sps defined?
sorry that’s just from scipy import sparse as sps and tud stands for torch.utils.data
Could you share a stripped down / minimal version of your training loop too, please?
for i, (x, y) in enumerate(loader):
if x.is_sparse:
x = x.to_dense()
x = x.cuda(non_blocking=True)
y = y.cuda(non_blocking=True)
loss, output = criterion(model, x, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Where do you define LogisticRegression?
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_19676\3241591868.py in <module>
----> 1 model = MLP(in_dim=409)
2 for i, (x, y) in enumerate(loader):
3 if x.is_sparse:
4 x = x.to_dense()
5
~\AppData\Local\Temp\ipykernel_19676\2325333031.py in __init__(self, in_dim, num_classes)
75 class MLP(nn.Module):
76 def __init__(self, in_dim, num_classes=2):
---> 77 super(LogisticRegression, self).__init__()
78
79 self.in_dim = in_dim
NameError: name 'LogisticRegression' is not defined
Btw in code I’ve seen, the class inside the super() call is typically the parent class (in your case MLP) not some other one. Not sure if that makes any difference though.
Simply change line77 from super(LogisticRegression, self).__init__() to super(MLP, self).__init__().
That’s reminiscent of the old notation.
Getting this error now:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_21892\1132068329.py in <module>
7 y = y.cuda(non_blocking=True)
8
----> 9 loss, output = criterion(model, x, y)
10
11 optimizer.zero_grad()
~\AppData\Local\Temp\ipykernel_21892\238189117.py in criterion(model, x, y)
109 y_hat = model(x)
110 prob = torch.sigmoid(y_hat)[:, 1]
--> 111 return nn.BCELoss(reduction='mean')(prob, y), y_hat
112
113 class SparseDataset(Dataset):
c:\users\andre\appdata\local\continuum\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
887 result = self._slow_forward(*input, **kwargs)
888 else:
--> 889 result = self.forward(*input, **kwargs)
890 for hook in itertools.chain(
891 _global_forward_hooks.values(),
c:\users\andre\appdata\local\continuum\anaconda3\lib\site-packages\torch\nn\modules\loss.py in forward(self, input, target)
611 def forward(self, input: Tensor, target: Tensor) -> Tensor:
612 assert self.weight is None or isinstance(self.weight, Tensor)
--> 613 return F.binary_cross_entropy(input, target, weight=self.weight, reduction=self.reduction)
614
615
c:\users\andre\appdata\local\continuum\anaconda3\lib\site-packages\torch\nn\functional.py in binary_cross_entropy(input, target, weight, size_average, reduce, reduction)
2753 raise ValueError(
2754 "Using a target size ({}) that is different to the input size ({}) is deprecated. "
-> 2755 "Please ensure they have the same size.".format(target.size(), input.size())
2756 )
2757
ValueError: Using a target size (torch.Size([16, 409])) that is different to the input size (torch.Size([16])) is deprecated. Please ensure they have the same size.
What’s your torch version? I have 1.8.1+cu111.
I don’t think there’s any relation to torch version, simply check the sizes of arguments to BCELoss in line 111.
If for instance prob.shape = (16, 1) and y.shape = (16,) then BCELoss will complain simply flatten the prob argument in the loss function.
In other words both prob and y arguments in BCELoss should have same shapes.
Right, but using your code the sizes come out to (512, 4096) and (512), per the message above. This suggests it’s not simply a question of flattening, so I’m asking you to look into why there’s that size mismatch.
(note in my original post it was (16, 409) because I’d used a different batch size and matrix size, but the error remains with your original variables)
No error on my side, same code with same modifications as suggested.
Her’s the output using batch size 512:
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -25450.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -76650.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -127850.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -179050.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -230250.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -281450.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -332650.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -383850.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -435050.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -486250.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -537450.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -588650.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -639850.0
shapes, x torch.Size([512]), y torch.Size([512])
Loss : -691050.0
The shapes are for the arguments in BCELoss.
Here’s with batch size 16:
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -650.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -2250.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -3850.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -5450.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -7050.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -8650.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -10250.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -11850.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -13450.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -15050.0
shapes, x = torch.Size([16]), y = torch.Size([16])
Loss : -16650.0
And here’s my torch version py3.7_cuda11.3_cudnn8.2.0_0 pytorch 1.11.0
I think there’s sth on your side causing that error. Most probably older version of BCELoss?
Are you sure you are calling the criterion as in the example loss, output = criterion(model, x, y) and the criterion should return back two arguments?
Hi, are you sure you don’t have any local changes to your code that aren’t reflected in the code you shared above?
I ran the code in a colab that you can access too and had the same issue as in my local environment. Note that I decreased batch size from 80k to 8k just to test this.
That’s great thanks for the colab notebook. Now I can see where the error is.
There’s plenty of redundancy in the colab notebook but that’s fine the error is due to the fact that you’ve changed the size of the targets vector.
If you look at my initial code the targets are defined as a vector of similar length to the actual input.
y = np.arange(80000)
but in your code you have changed it to
y = (X > 0.5).astype(int)
the shape of y is y.shape = [8000, 4096].
Since the shape of y matches the shape of x then BCELoss won’t complain.
But, in the criterion the input x passes through the model which returns y_hat of shape y_hat.shape = [batch_size, 2] and from sigmoid we end up with prob which is of shape prob.shape = [batch_size].
In other words you’re trying to pass into BCELoss the vector x of shape x.shape = [batch_size] and the matrix y of shape [batch_size, 4096]. Change y into a vector of shape y.shape = [batch_size] and everything will work again.
You’re absolutely right. I’ll fix that and try to train.
Hi, sorry for the delayed reply.
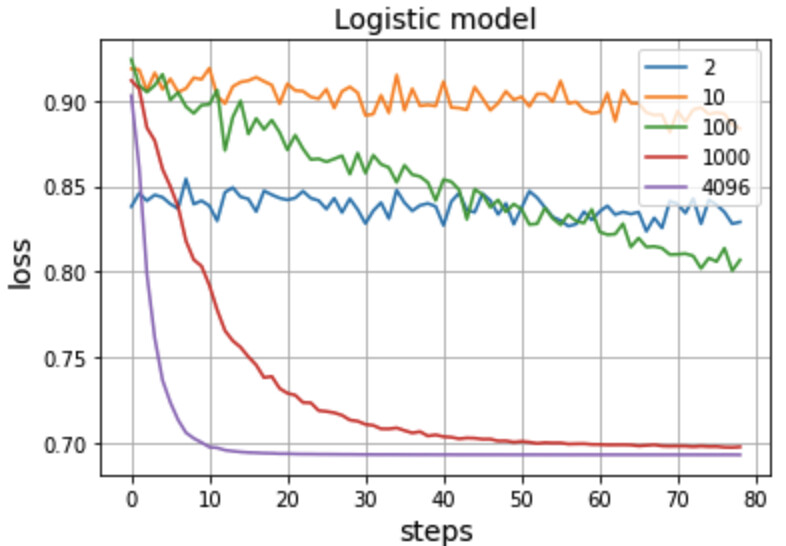
I don’t think there’s anything wrong with the overall method of training, but it seems like something about the architecture is the culprit. I ran an experiment where I created this network with various number of input features. You can see that when the number of input features is too high, the loss stagnates well above zero.
n_data = 40000
losses_dict = {}
for in_feat in [2, 10, 100, 1000, 4096]:
X = sps.random(n_data, in_feat, density=0.25)
y = (X.A[:,0] > 0.5).astype(int)
dset = SparseDataset(X, y)
loader = tud.DataLoader(dset, batch_size=512, collate_fn=sparse_batch_collate)
model = MLP_nodropout(in_dim=in_feat)
losses = []
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for i, (x, y) in enumerate(loader):
if x.is_sparse:
x = x.to_dense()
y_hat = model(x).squeeze()[:,1]
loss = nn.BCELoss(reduction='mean')(torch.sigmoid(y_hat), y)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses_dict[in_feat] = losses
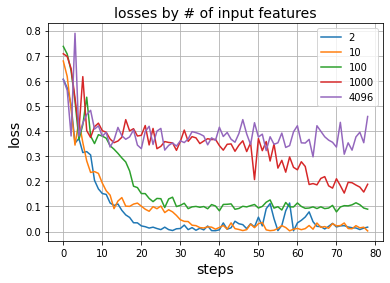
I thought that maybe the Dropout and MaxPool layers were losing input information and leading to some “floor” loss, however I removed them and the outcome is the same.
Thanks for sharing this interesting insight, it seems like for logistic regression we “kind of” have the opposite image
I remember that when trying the same stuff with logistic regression from sckikit and solver ‘sag’ things were working.
Maybe this requires more investigation on what is different between scikit implementation and pytorch?
Also you might be right about the architecture imposing sth that makes the whole learning stagnate on large input features, otherwise this doesn’t make sense for deep learning since that’s its promise on working automatically on large feature spaces?
Another possibility would be that it will converge, but it will simply take a lot more steps to do so. Perhaps convergence would be sped up by more regularization, like maybe adding weight decay.
Would be curious if you discover anything, as this seems like a pretty generic model that ought to work.
Same question I’m asking myself as well, in the original post of showing the loss being stagnated I was using the weight decay = 5e-3 but the only difference I can think of is that in the logistic regression from scikit learn I was using regualrisation C = average(l2_norm(X[:10000], axis=1)), where C is defined as:
C : float, default=1.0
Inverse of regularization strength; must be a positive float. Like in support vector machines, smaller values specify stronger regularization.