Hi,
I have been trying to learn translation (x, y) parameters with Kornia in the following manner:
class DTranslation(nn.Module):
def __init__(self, x_translation, y_translation):
super(DTranslation, self).__init__()
self.translations = torch.stack([x_translation, y_translation], 1)
self.angle = torch.tensor([0])
def forward(self, input):
_, _, h, w = input.shape
if self.angle.shape[0] != input.shape[0]:
angle = self.angle.repeat(input.shape[0])
else:
angle = self.angle
if self.translations.shape[0] != input.shape[0]:
translations = self.translations.repeat([input.shape[0], 1])
else:
translations = self.translations
translations[:, 0] *= h
translations[:, 1] *= w
# define the rotation center
center = torch.ones(2)
center[..., 0] = input.shape[3] / 2 # x
center[..., 1] = input.shape[2] / 2 # y
center = center.repeat(input.shape[0], 1)
# define the scale factor
scale = torch.ones(input.shape[0])
# compute the transformation matrix
M = kornia.get_rotation_matrix2d(center, -angle, scale)
# Translate
M[..., 2] += translations # tx/ty
# apply the transformation to original image
out = kornia.warp_affine(input, M, dsize=(h, w))
return out
tx = torch.tensor([0.3], dtype=torch.float32)
tx_p = Parameter(tx, requires_grad=True)
ty = torch.tensor([-0.2], dtype=torch.float32)
ty_p = Parameter(ty, requires_grad=True)
translation = DTranslation(x_translation=tx_p, y_translation=ty_p)
criterion = nn.MSELoss()
optimizer = optim.Adam([tx_p, ty_p], lr=1)
for x, y in dataloader:
optimizer.zero_grad()
loss = criterion(x, translation(x))
loss.backward()
optimizer.step()
The first backward call passes, but the second one fails:
RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling backward the first time.
When I follow the instructions and instead I use:
loss.backward(retain_graph=True)
I receive the following error:
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.FloatTensor [1]] is at version 1; expected version 0 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
I also tried to avoid the inplace operation:
M[..., 2] += translations # tx/ty
and use instead:
shape = list(M.shape)
shape[-1] -= 1
M = M + torch.cat([torch.zeros(shape), translations.unsqueeze(-1)], 2)
It is worth mentioning that I do manage to backpropagated through rotation angle and shear (x, y) but only translation seems to be the problem, i.e. when I comment out
M[..., 2] += translations # tx/ty
No errors occur, but of course I cannot learn the translation parameters either.
My guess is that defining the constant outside nn.Module breaks the graph. Once you define them inside nn.Module they are gonna be registered as buffers and it sounds bad to me.
Why don’t you just define them as regular nn.Parameters and pass the nn.Module to the optimizer?
Anyway, can you provide a runnable script?
WRT the inplace ops, indeed that M[…,2] is not allowed.
from torch import nn
import torch
import kornia
import imageio
import cv2
import matplotlib.pyplot as plt
import numpy as np
ex = imageio.imread(
'https://nickelquilts.files.wordpress.com/2018/04/1-half-square-triangle-block-with-copyright.jpg') / 255.
ex = cv2.resize(ex, (100, 100)).astype(np.float32)
torch.manual_seed(666)
def show(img):
if isinstance(img, np.ndarray):
pass
else:
img = img[0].permute(1, 2, 0).detach().cpu().numpy()
plt.imshow(img)
plt.show()
show(ex)
class DTranslation(nn.Module):
def __init__(self, x_translation, y_translation):
super(DTranslation, self).__init__()
self.translations = nn.Parameter(torch.stack([x_translation, y_translation], 1))
self.angle = torch.tensor([0])
def forward(self, input, train=True):
_, _, h, w = input.shape
if self.angle.shape[0] != input.shape[0]:
angle = self.angle.repeat(input.shape[0])
else:
angle = self.angle
if self.translations.shape[0] != input.shape[0]:
translations = self.translations.repeat([input.shape[0], 1])
else:
translations = self.translations
if train:
translations = torch.sigmoid(translations) * torch.Tensor([h, w])
else:
translations = translations * torch.Tensor([h, w])
# define the rotation center
center = torch.ones(2)
center[..., 0] = input.shape[3] / 2 # x
center[..., 1] = input.shape[2] / 2 # y
center = center.repeat(input.shape[0], 1)
# define the scale factor
scale = torch.ones(input.shape[0])
# compute the transformation matrix
M = kornia.get_rotation_matrix2d(center, -angle, scale)
# Translate
shape = list(M.shape)
shape[-1] -= 1
M = M + torch.cat([torch.zeros(shape), translations.unsqueeze(-1)], 2)
# apply the transformation to original image
out = kornia.warp_affine(input, M, dsize=(h, w), padding_mode='zeros')
return out
tx = torch.tensor([-1], dtype=torch.float32)
ty = torch.tensor([-1], dtype=torch.float32)
translation = DTranslation(x_translation=tx, y_translation=ty)
class Corr(nn.Module):
def forward(self, x, pred):
x = x.flatten()
p = pred.flatten()
x_n = torch.norm(x)
p_n = torch.norm(p)
return torch.dot(x, p) / (x_n * p_n)
criterion = nn.L1Loss()
# criterion = nn.CosineSimilarity(1)
optimizer = torch.optim.Adam(translation.parameters(), lr=0.0001)
img = torch.from_numpy(ex).permute(2, 0, 1)[None, ...]
img.requires_grad_(True)
inst = DTranslation(torch.tensor([0.2], dtype=torch.float32),
torch.tensor([0.2], dtype=torch.float32))
with torch.no_grad():
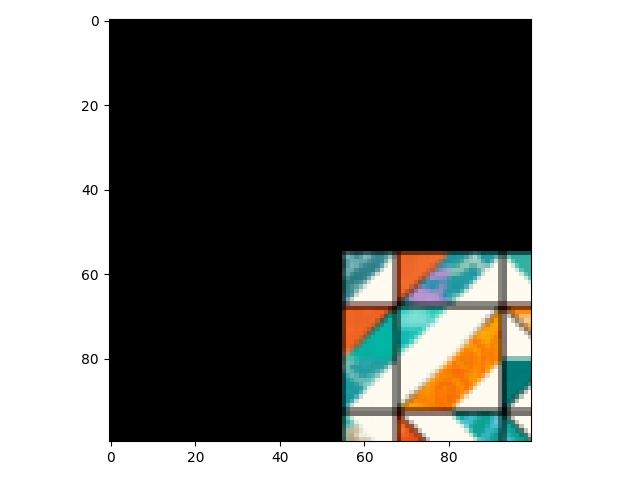
gt = inst(img)
show(gt)
for i in range(1000):
optimizer.zero_grad()
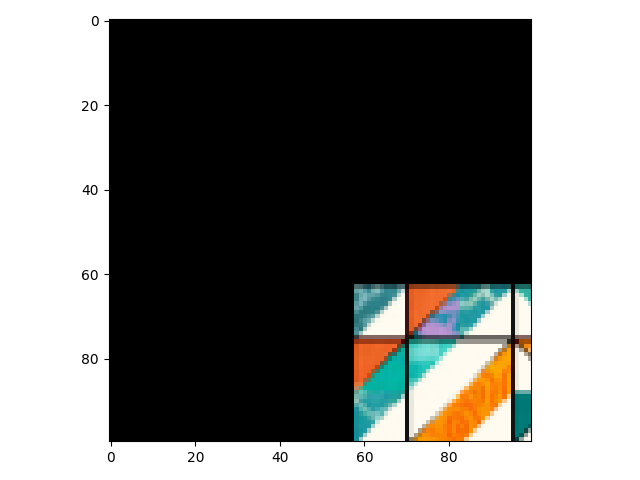
result = translation(img, train=True)
if i % 10 == 0:
show(result)
loss = criterion(gt.view(1, -1), result.view(1, -1))
loss.backward()
print(f'Grad: '
f'{translation.translations.grad}, '
f'Loss: {loss.item()}, '
f'Value: {torch.sigmoid(translation.translations.data)}')
optimizer.step()
But i have to say i don’t figure out why it doesn’t optimize it.
Gradients are not None, thus it properly prop.
The rot matrix is ok
I’ve tried to maximize corr instead of minimize euclidian but yet the same
Thank you for your code. I ran it. Indeed it doesn’t raise that error, yet it doesn’t train.
Actually, Instead of taking all the changes you suggested, I took my code and changed only the line:
and indeed the error went away. Yet the gradients w.r.t the original translation tensors remain zero.
I wonder if the constructor nn.Parameter() somehow duplicates the tensor such that the original one is detached from the graph hence no error occur yet neither gradients are back-propagated properly.
I mean, it should be working also without this change, as done in the rotation example in my code.
Well,
I don’t remember the details of Parameter but my guess is it detach.
It’s not pythonic->“pytorchnic” to define a parameter outside me module. If that is the case, then you don’t really need to wrap everything in a nn.Module. You can just use a standard function.
When you assign a torch tensor to a nn.Module, it internally calls register buffer. If torch is promoting the stack of to parameters into a tensor, the resulting one is being assigned as a buffer.
Anyway the input is gonna be a leaf node. If you run a gradient anomaly detector it will rise an error since gradients doesn’t flow to the input due to inplace ops.
Howver you are only using inplace ops to build the rotation matrix. The ops related to the translation vector are not affected and that’s why gradients flow down there.
Besides, the rotation matrix is ok. Ones in the diag + the translation vector .
My point is that:
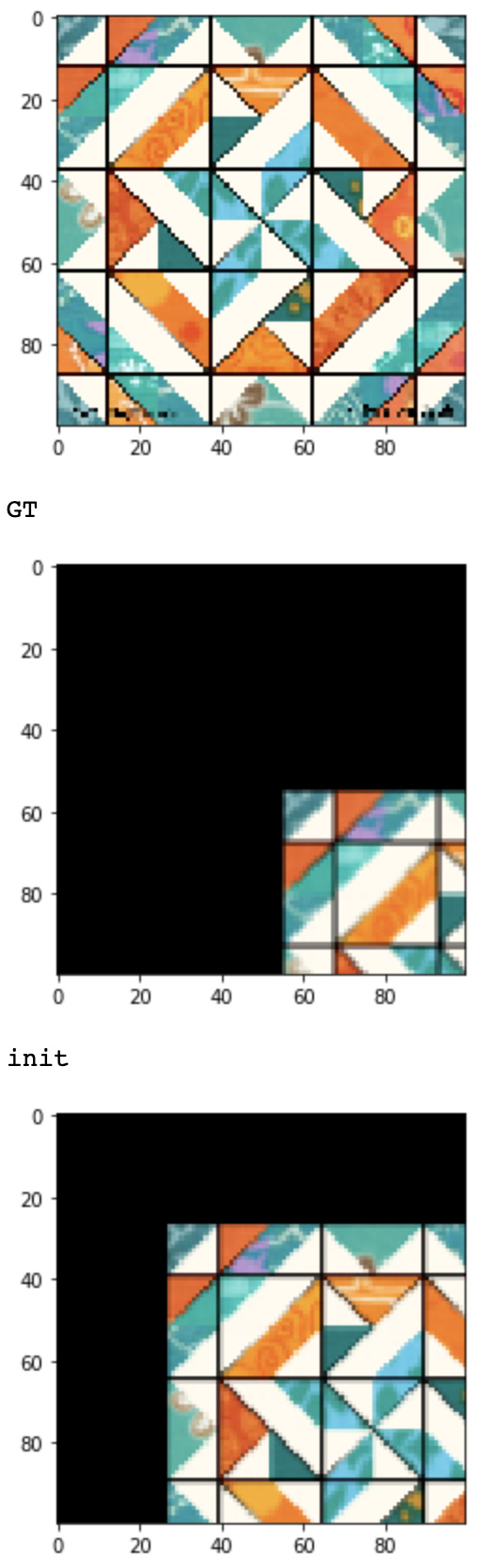
GT:
1st pref
Dpending of the learning rate it jumps around that point
or diverge
from torch import nn
import torch
import kornia
import imageio
import cv2
import matplotlib.pyplot as plt
import numpy as np
ex = imageio.imread(
'https://nickelquilts.files.wordpress.com/2018/04/1-half-square-triangle-block-with-copyright.jpg') / 255.
ex = cv2.resize(ex, (100, 100)).astype(np.float32)
torch.manual_seed(666)
def show(img):
if isinstance(img, np.ndarray):
pass
else:
img = img[0].permute(1, 2, 0).detach().cpu().numpy()
plt.imshow(img)
plt.show()
show(ex)
class DTranslation(nn.Module):
def __init__(self, x_translation, y_translation):
super(DTranslation, self).__init__()
self.translations = nn.Parameter(torch.stack([x_translation, y_translation], 1))
self.angle = torch.tensor([0])
def forward(self, input, train=True):
_, _, h, w = input.shape
if self.angle.shape[0] != input.shape[0]:
angle = self.angle.repeat(input.shape[0])
else:
angle = self.angle
if self.translations.shape[0] != input.shape[0]:
translations = self.translations.repeat([input.shape[0], 1])
else:
translations = self.translations
if train:
translations = torch.sigmoid(translations) * torch.Tensor([h, w])
else:
translations = translations * torch.Tensor([h, w])
# define the rotation center
center = torch.ones(2)
center[..., 0] = input.shape[3] / 2 # x
center[..., 1] = input.shape[2] / 2 # y
center = center.repeat(input.shape[0], 1)
# define the scale factor
scale = torch.ones(input.shape[0])
# compute the transformation matrix
M = kornia.get_rotation_matrix2d(center, -angle, scale)
# Translate
shape = list(M.shape)
shape[-1] -= 1
M = M + torch.cat([torch.zeros(shape), translations.unsqueeze(-1)], 2)
# apply the transformation to original image
out = kornia.warp_affine(input, M, dsize=(h, w), padding_mode='zeros')
return out
tx = torch.tensor([-1], dtype=torch.float32)
ty = torch.tensor([-1], dtype=torch.float32)
translation = DTranslation(x_translation=tx, y_translation=ty)
class Corr(nn.Module):
def forward(self, x, pred):
x = x.flatten()
p = pred.flatten()
x_n = torch.norm(x)
p_n = torch.norm(p)
return torch.dot(x, p) / (x_n * p_n)
criterion = nn.MSELoss()
# criterion = nn.CosineSimilarity(1)
optimizer = torch.optim.SGD(translation.parameters(), lr=0.75)
img = torch.from_numpy(ex).permute(2, 0, 1)[None, ...]
img.requires_grad_(True)
inst = DTranslation(torch.tensor([0.2], dtype=torch.float32),
torch.tensor([0.2], dtype=torch.float32))
with torch.no_grad():
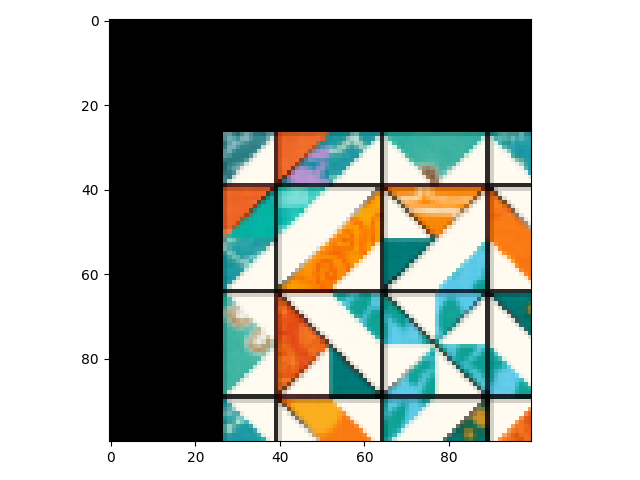
gt = inst(img)
show(gt)
loss_h = []
for i in range(100):
optimizer.zero_grad()
result = translation(img, train=True)
if i % 10 == 0:
show(result)
loss = criterion(gt.view(1, -1), result.view(1, -1))
loss_h.append(loss.item())
loss.backward()
print(f'Grad: '
f'{translation.translations.grad}, '
f'Loss: {loss.item()}, '
f'Value: {torch.sigmoid(translation.translations.data)}')
optimizer.step()
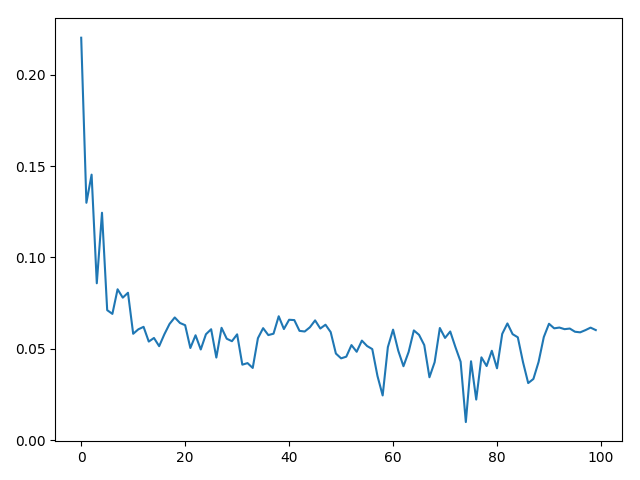
plt.plot(loss_h)
plt.show()
I just went forward SGD to avoid statistical optimizers.
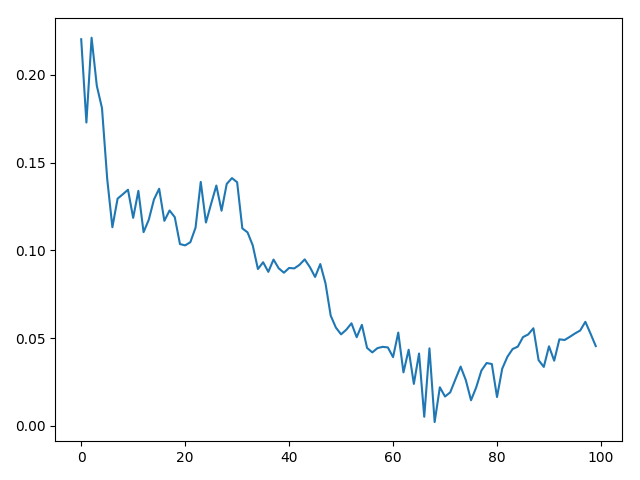
It get stuck.
GT
Pred N
You can try to reduce LR through time, using an scheduler or manually.
It’s somehow ill posed
For lr=0.5
It reaches a good result but diverge in the end.
Maybe an iterative scheme which grabs the best result can help u
Still I fail to understand what the problem is. After all I determined the parameter in a nn.Module (LearnableAugs) and then passed it to be processed in an internal nn.Module that doesn’t have those registered as parameters. Nevertheless, I expect the gradients to flow properly as happening for all the other transforms I learn (e.g. rotation, shear, etc.). It’s a mystery to me.
I think you should predict directly the magnitude value.
Predicting a number between 0-1 makes gradients to be multiplied by 100.
It smoothes the curve.
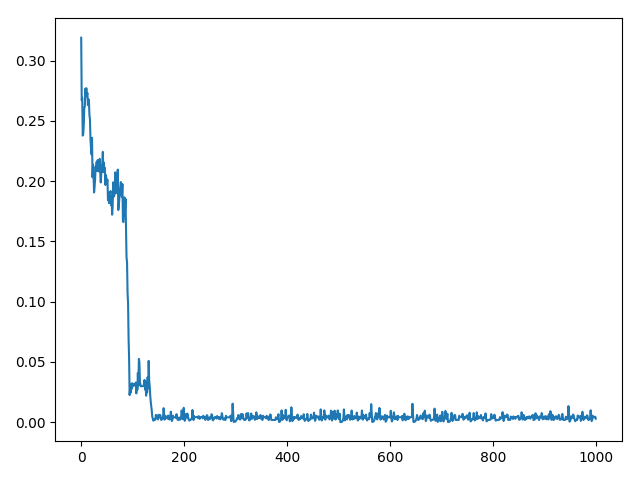
The best result i got is the following one:
Which goes from the original position to (20,20)
But it’s really dependent on the LR.
LR 50 makes it to diverge and LR 10 makes it to stuck in a minima.
from torch import nn
import torch
import kornia
import imageio
import cv2
import matplotlib.pyplot as plt
import numpy as np
ex = imageio.imread(
'https://nickelquilts.files.wordpress.com/2018/04/1-half-square-triangle-block-with-copyright.jpg') / 255.
ex = cv2.resize(ex, (100, 100)).astype(np.float32)
torch.manual_seed(666)
def show(img):
if isinstance(img, np.ndarray):
pass
else:
img = img[0].permute(1, 2, 0).detach().cpu().numpy()
plt.imshow(img)
plt.show()
show(ex)
class DTranslation(nn.Module):
def __init__(self, x_translation, y_translation):
super(DTranslation, self).__init__()
self.translations = nn.Parameter(torch.stack([x_translation, y_translation], 1))
self.angle = torch.tensor([0])
def forward(self, input, train=True):
_, _, h, w = input.shape
if self.angle.shape[0] != input.shape[0]:
angle = self.angle.repeat(input.shape[0])
else:
angle = self.angle
if self.translations.shape[0] != input.shape[0]:
translations = self.translations.repeat([input.shape[0], 1])
else:
translations = self.translations
if train:
# translations = translations * torch.Tensor([h, w])
translations = translations
else:
# translations = translations * torch.Tensor([h, w])
translations = translations
# define the rotation center
center = torch.ones(2)
center[..., 0] = input.shape[3] / 2 # x
center[..., 1] = input.shape[2] / 2 # y
center = center.repeat(input.shape[0], 1)
# define the scale factor
scale = torch.ones(input.shape[0])
# compute the transformation matrix
M = kornia.get_rotation_matrix2d(center, -angle, scale)
# Translate
shape = list(M.shape)
shape[-1] -= 1
M = M + torch.cat([torch.zeros(shape), translations.unsqueeze(-1)], 2)
# apply the transformation to original image
out = kornia.warp_affine(input, M, dsize=(h, w), padding_mode='zeros')
return out
tx = torch.tensor([1.], dtype=torch.float32)
ty = torch.tensor([1.], dtype=torch.float32)
translation = DTranslation(x_translation=tx, y_translation=ty)
class Corr(nn.Module):
def forward(self, x, pred):
x = x.flatten()
p = pred.flatten()
x_n = torch.norm(x)
p_n = torch.norm(p)
return torch.dot(x, p) / (x_n * p_n)
criterion = nn.MSELoss()
# criterion = nn.CosineSimilarity(1)
optimizer = torch.optim.SGD(translation.parameters(), lr=25)
img = torch.from_numpy(ex).permute(2, 0, 1)[None, ...]
img.requires_grad_(True)
inst = DTranslation(torch.tensor([20.], dtype=torch.float32),
torch.tensor([20.], dtype=torch.float32))
with torch.no_grad():
gt = inst(img)
show(gt)
loss_h = []
N=1000
for i in range(N):
optimizer.zero_grad()
result = translation(img, train=True)
if i % (N//100) == 0:
show(result)
loss = criterion(gt.view(1, -1), result.view(1, -1))
loss_h.append(loss.item())
loss.backward()
print(f'Grad: '
f'{translation.translations.grad}, '
f'Loss: {loss.item()}, '
f'Value: {translation.translations.data}')
optimizer.step()
plt.plot(loss_h)
plt.show()
The only problem was placing translations = torch.stack([x_translation, y_translation], 1) at the init () rather than in the forward().
FYI all the inplace operations do not interfere with the differentiation as those are all differentiable, i,e, both: translations[:, 0] *= h translations[:, 1] *= w
And: M[..., 2] += translations
Eventually the working code is:
class DTranslation(nn.Module):
def __init__(self, x_translation, y_translation):
super(DTranslation, self).__init__()
self.x_translation = x_translation
self.y_translation = y_translation
self.angle = torch.tensor([0])
def forward(self, input):
_, _, h, w = input.shape
if self.angle.shape[0] != input.shape[0]:
angle = self.angle.repeat(input.shape[0])
else:
angle = self.angle
translations = torch.stack([self.x_translation, self.y_translation], 1)
if translations.shape[0] != input.shape[0]:
translations = translations.repeat([input.shape[0], 1])
else:
translations = translations
translations[:, 0] *= h
translations[:, 1] *= w
# define the rotation center
center = torch.ones(2)
center[..., 0] = input.shape[3] / 2 # x
center[..., 1] = input.shape[2] / 2 # y
center = center.repeat(input.shape[0], 1)
# define the scale factor
scale = torch.ones(input.shape[0])
# compute the transformation matrix
M = kornia.get_rotation_matrix2d(center, -angle, scale)
# Translate
M[..., 2] += translations # tx/ty
# apply the transformation to original image
out = kornia.warp_affine(input, M, dsize=(h, w))
return out