With a bit more of analysis.
from torch import nn
import torch
import kornia
import imageio
import cv2
import matplotlib.pyplot as plt
import numpy as np
ex = imageio.imread(
'https://nickelquilts.files.wordpress.com/2018/04/1-half-square-triangle-block-with-copyright.jpg') / 255.
ex = cv2.resize(ex, (100, 100)).astype(np.float32)
torch.manual_seed(666)
def show(img):
if isinstance(img, np.ndarray):
pass
else:
img = img[0].permute(1, 2, 0).detach().cpu().numpy()
plt.imshow(img)
plt.show()
show(ex)
class DTranslation(nn.Module):
def __init__(self, x_translation, y_translation):
super(DTranslation, self).__init__()
self.translations = nn.Parameter(torch.stack([x_translation, y_translation], 1))
self.angle = torch.tensor([0])
def forward(self, input, train=True):
_, _, h, w = input.shape
if self.angle.shape[0] != input.shape[0]:
angle = self.angle.repeat(input.shape[0])
else:
angle = self.angle
if self.translations.shape[0] != input.shape[0]:
translations = self.translations.repeat([input.shape[0], 1])
else:
translations = self.translations
if train:
translations = torch.sigmoid(translations) * torch.Tensor([h, w])
else:
translations = translations * torch.Tensor([h, w])
# define the rotation center
center = torch.ones(2)
center[..., 0] = input.shape[3] / 2 # x
center[..., 1] = input.shape[2] / 2 # y
center = center.repeat(input.shape[0], 1)
# define the scale factor
scale = torch.ones(input.shape[0])
# compute the transformation matrix
M = kornia.get_rotation_matrix2d(center, -angle, scale)
# Translate
shape = list(M.shape)
shape[-1] -= 1
M = M + torch.cat([torch.zeros(shape), translations.unsqueeze(-1)], 2)
# apply the transformation to original image
out = kornia.warp_affine(input, M, dsize=(h, w), padding_mode='zeros')
return out
tx = torch.tensor([-1], dtype=torch.float32)
ty = torch.tensor([-1], dtype=torch.float32)
translation = DTranslation(x_translation=tx, y_translation=ty)
class Corr(nn.Module):
def forward(self, x, pred):
x = x.flatten()
p = pred.flatten()
x_n = torch.norm(x)
p_n = torch.norm(p)
return torch.dot(x, p) / (x_n * p_n)
criterion = nn.MSELoss()
# criterion = nn.CosineSimilarity(1)
optimizer = torch.optim.SGD(translation.parameters(), lr=0.75)
img = torch.from_numpy(ex).permute(2, 0, 1)[None, ...]
img.requires_grad_(True)
inst = DTranslation(torch.tensor([0.2], dtype=torch.float32),
torch.tensor([0.2], dtype=torch.float32))
with torch.no_grad():
gt = inst(img)
show(gt)
loss_h = []
for i in range(100):
optimizer.zero_grad()
result = translation(img, train=True)
if i % 10 == 0:
show(result)
loss = criterion(gt.view(1, -1), result.view(1, -1))
loss_h.append(loss.item())
loss.backward()
print(f'Grad: '
f'{translation.translations.grad}, '
f'Loss: {loss.item()}, '
f'Value: {torch.sigmoid(translation.translations.data)}')
optimizer.step()
plt.plot(loss_h)
plt.show()
I just went forward SGD to avoid statistical optimizers.
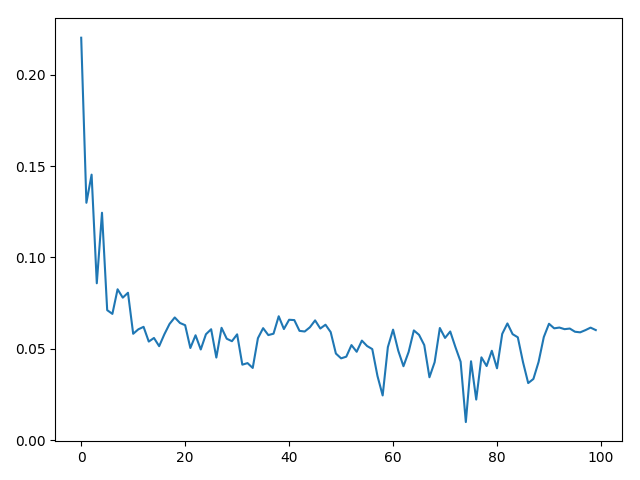
It get stuck.
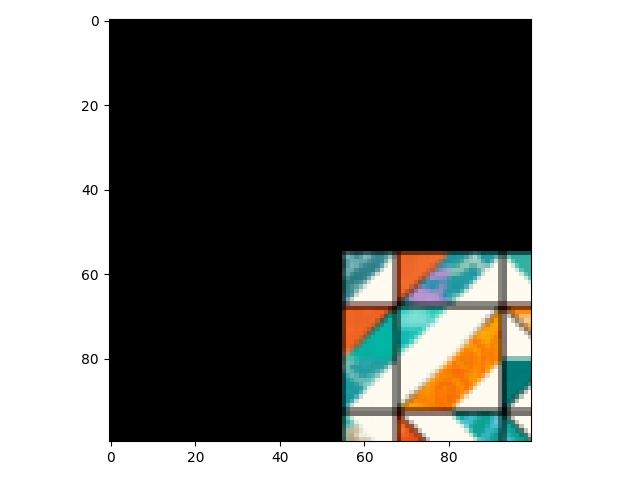
GT
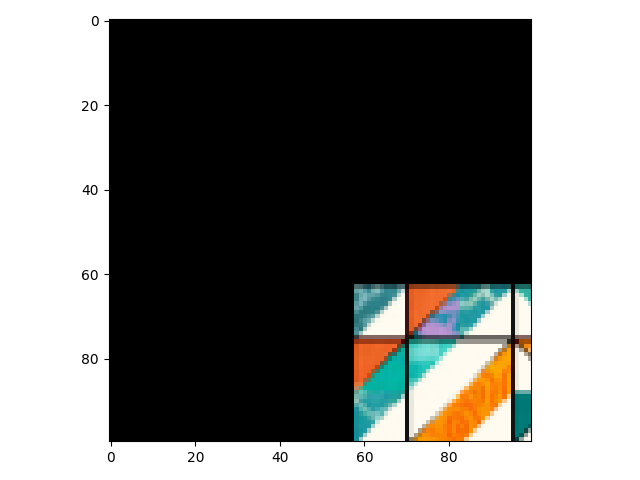
Pred N
You can try to reduce LR through time, using an scheduler or manually.
It’s somehow ill posed
For lr=0.5
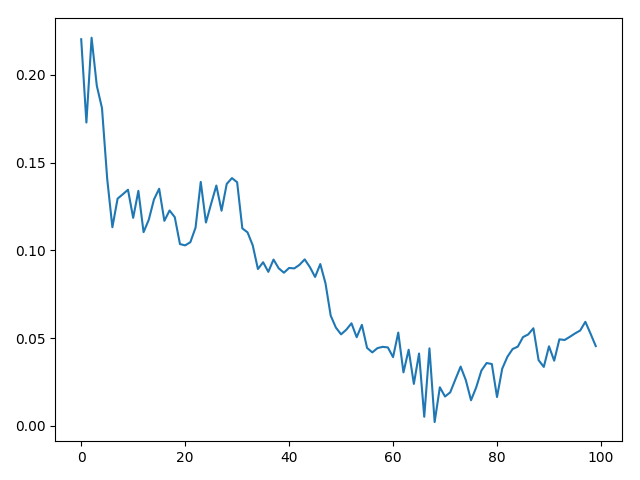
It reaches a good result but diverge in the end.
Maybe an iterative scheme which grabs the best result can help u