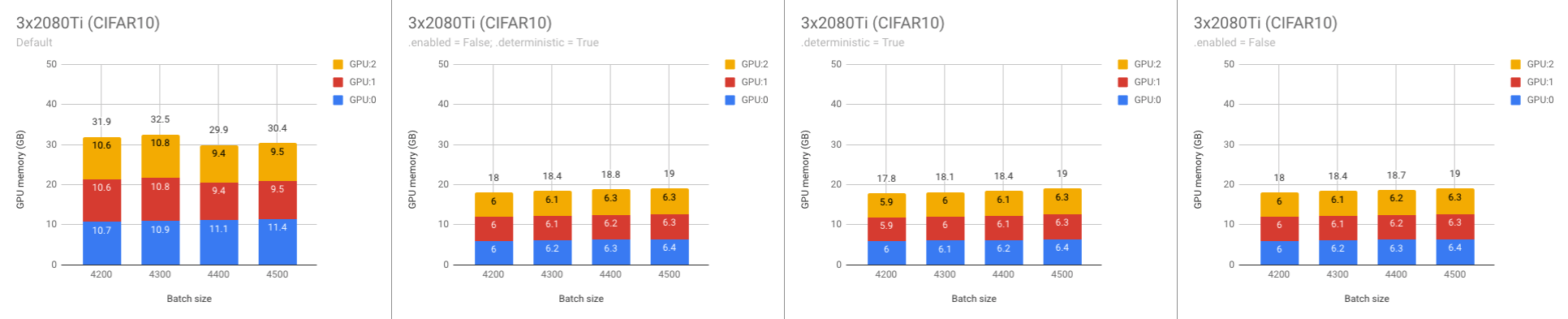
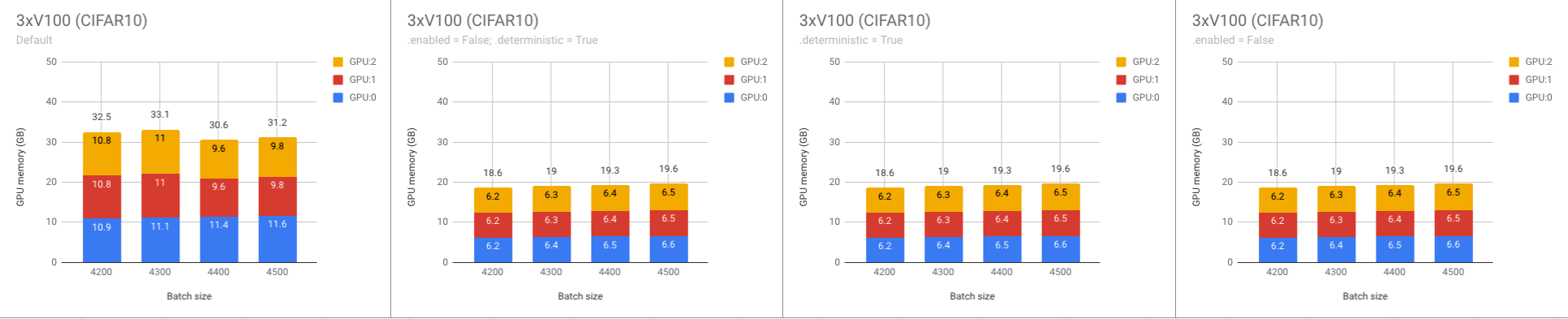
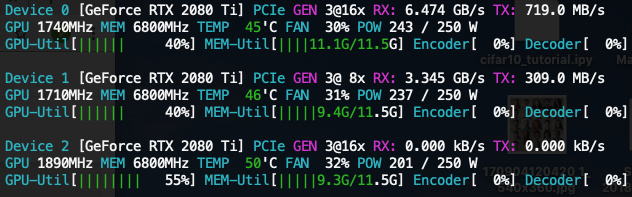
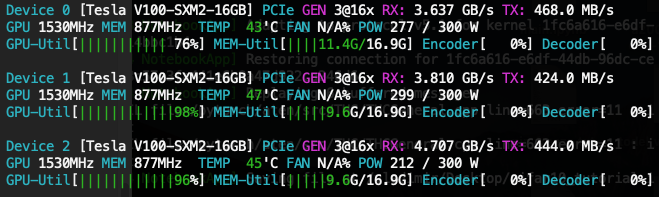
Okay, these are results of the experiments. Please, note that .benchmark is disabled by default anyway. There is no need to specify it.
- Default setup
enable = False and deterministic = True- Only
deterministic = True
- Only
enable = False
3x2080Ti
3xV100
Code
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
## Exp. 1:
# torch.backends.cudnn.enabled = False
# torch.backends.cudnn.deterministic = True
## Exp. 2:
# torch.backends.cudnn.deterministic = True
## Exp. 3:
# torch.backends.cudnn.enabled = False
B = 4400
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=B, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
cfg = {
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
net = VGG('VGG16')
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)
device = "cuda"
torch.cuda.set_device(0)
net.to(device);
net = nn.DataParallel(net, device_ids=[0, 1, 2])
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
inputs, labels = inputs.cuda(device, async=True), labels.cuda(device, async=True)
inputs, targets = torch.autograd.Variable(inputs), torch.autograd.Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print('[{:d}, {:5f}]'.format(epoch+1, loss.item()))
Also, I have had a quite fruitful chat with @ptrblck these are some insightful things from it:
pip3 install torch torchvision installs not only PyTorch but also binaries like a proper CUDA and CUDNN. So, only GPU drivers are prerequisite for PyTorch, at least for most of the modern GPUs;- I have noticed that during my installation I only added path for CUDA and didn’t for CUDNN. However, it is not the case because, apparently, PyTorch uses its own binaries (see the previous note).