Quick question about an implementation choice (didn’t feel appropriate to raise on github)
Psuedo-inverses are proper inverses when a matrix is square + full rank.
It seems like the implementation in torch isn’t doing anything to discover rank and so can’t fall back on classical inverse algorithms for efficiency.
I am playing with this example:
import torch
nrows = 10000
ncols = 10000
torch.inverse(torch.rand(nrows,ncols).cuda())
CPU times: user 3.8 s, sys: 141 ms, total: 3.94 s
Wall time: 927 ms
swapping that last line for torch.pinverse(torch.rand(nrows,ncols).cuda()) yields
CPU times: user 2min 17s, sys: 1.95 s, total: 2min 19s
Wall time: 20.7 s
So, even with added overhead to discover rank with something like Cholesky (for which it seems an implementation exists), large speedups can be gained.
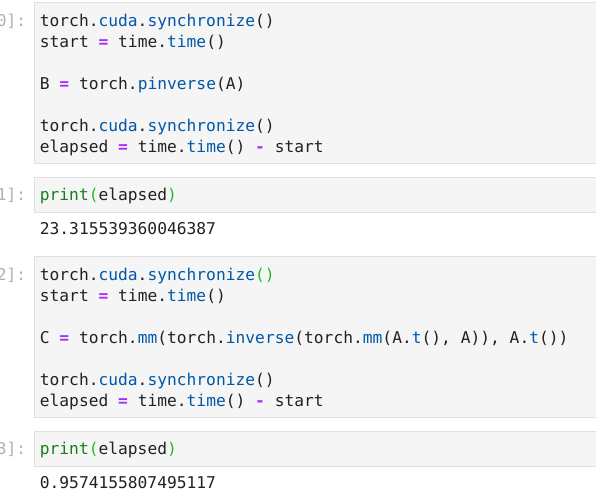
What’s going on under the hood with pseudo-inverse and why is it taking so much longer? mat-mult is sub-second, classical inversion for full-rank operators is sub-second, so even manual-construction wins out:
A = torch.rand(nrows,ncols).cuda()
torch.mm(torch.inverse(torch.mm(A.t(), A)), A.t())
CPU times: user 3.67 s, sys: 167 ms, total: 3.83 s
Wall time: 1.09 s
Moreover, sometimes pinverse runs out of memory, but the latter won’t (a kernel restart allows pinverse to run again), and the solutions do seem to agree on average: