Hi everyone, i build simple linear nn but output of this network is not same as desired result.
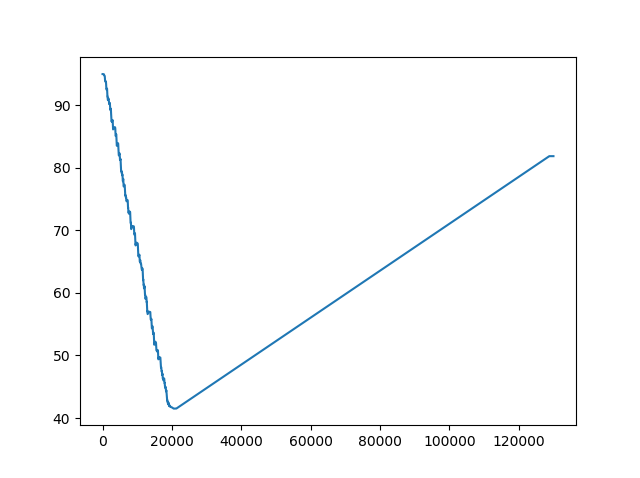
I got this result from my network
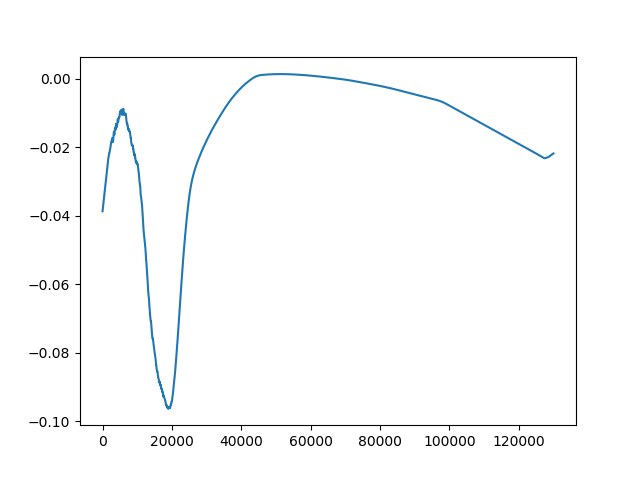
this is my loss graph
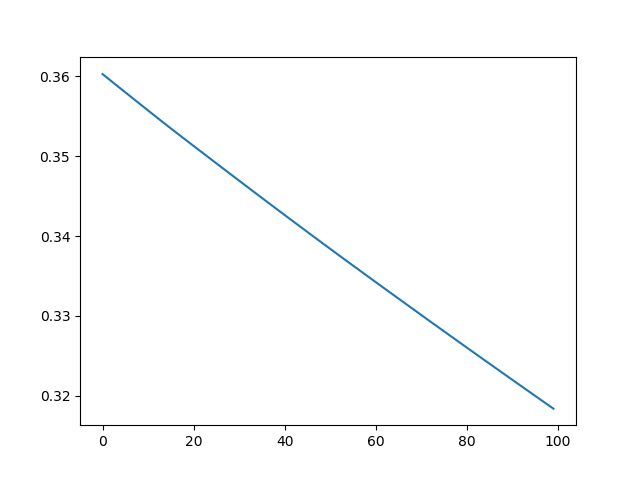
this is the desired result
my codes are:
class Module(nn.Module):
def __init__(self, D_in, H1, H2, D_out):
super().__init__()
self.linear1 = nn.Linear(D_in, H1)
self.linear2 = nn.Linear(H1, H2)
self.linear3 = nn.Linear(H2, D_out)
def forward(self, x):
x = F.relu(self.linear1(x))
x = F.relu(self.linear2(x))
x = self.linear3(x)
return x
train_dataset = TensorDataset(train_x, train_y)
train_generator = DataLoader(train_dataset, batch_size=32,shuffle=False)
valid_dataset = TensorDataset(val_x, val_y)
valid_generator = DataLoader(valid_dataset, batch_size=32)
model=Module(3,27,11,1)
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
for e in range(epochs):
running_loss = 0.0
running_corrects = 0.0
val_running_loss = 0.0
val_running_corrects = 0.0
for inputs,out in train_generator:
print(out.size())
inputs=inputs.to(device)
out=out.to(device)
output=model(inputs)
new_output = torch.squeeze(output)
print("input size: ",inputs.size())
loss = criterion(new_output,out)
print("output size: ",output.size())
print("out size: ",out.size())
preds,_=torch.max(new_output,1)
outputss.append(preds.max().detach().numpy())
losses.append(loss)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#outputss.append(outputs.detach().numpy())
#print(loss.item())
else:
with torch.no_grad():
for val_inputs, val_labels in valid_generator:
#val_inputs = val_inputs.view(val_inputs.shape[0], -1)
val_inputs=val_inputs.to(device)
val_labels=val_labels.to(device)
val_outputs = model(val_inputs)
val_loss = criterion(val_outputs, val_labels)
val_preds,_ = torch.max(val_outputs, 1)
val_running_loss_history.append(val_loss)
val_running_corrects_history.append(val_preds.max().detach().numpy())
If you can help me, I will be very thankful