since I am a newbie in python programming and I want to load the data according to the table of the article but I don’t know how to can do categorical training and testing the NSL_KDD dataset into(‘normal’, ‘dos’, ‘r2l’, ‘probe’, ‘u2r’).
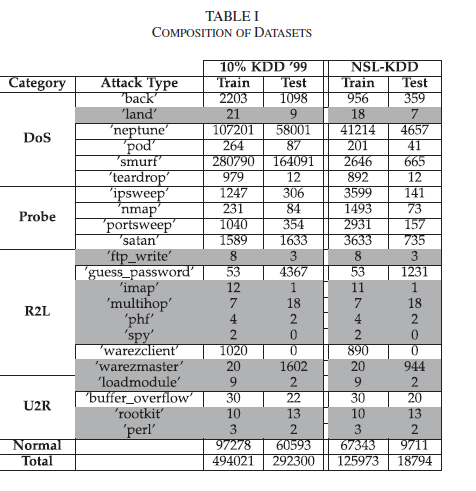
I’ve reviewed a lot of code in GateHub to pre-process the NSL_KDD data set to categorize into five groups(‘normal’, ‘dos’, ‘r2l’, ‘probe’, ‘u2r’), but I still haven’t been able to find the code to do it right.
Can anyone help me? I really need help.
This doesn’t seem to be a PyTorch-specific question, and I would recommend to ask on StackOverflow or maybe in the competition discussion board (if they have one) 
Based on your last post it seems that the scaling is failing due to unexpected values, so you could look into the data and check all values for NaNs, Infs etc.
1 Like