I was stuck trying to load a checkpoint trained using DataParallel and a bunch of things seem to have worked so far for me. It took several iterations to fix, and I had to find the following after many attempts of searching. I feel there’s still some things I’m doing wrong, and am hoping this thread would help.
DataParallel Training from start
I found that the usage(gpu0) = gpu1 + gpu2 + gpu3 + gpu0, which was due to computing loss outside. The following confused me, since it said loss can be outside.
The methods in the below thread meanwhile worked, once I put model + loss inside DataParallel, it balanced GPU memory to some extent.
DataParallel Training from checkpoint
Everytime I tried to load it directly, I was getting out of memory error without even reaching the peak batch size I could achieve from the above setting. Eventually, loading weights to CPU first and then load_state_dict on the model from that worked to balance the memory imbalance across GPUs. I believe the following thread partially helped me out:
Current Status
There is still an imbalance. I’m using 3 1080 Tis (1-3) with 11GB max memory. Attempts to increase further gives me OOM, while clearly [2] and [3] has free space.
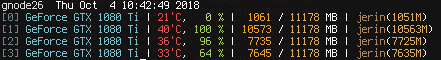
The following is the main training routine, at this point:
def checkpoint(model, opt, checkpoint_path):
_payload = {
"model": model.module.state_dict(),
"opt": opt.state_dict()
}
with open(checkpoint_path, "wb+") as fp:
torch.save(_payload, fp)
def load(model, opt, checkpoint_path):
_payload = torch.load(checkpoint_path, map_location=torch.device("cpu"))
model.module.load_state_dict(_payload["model"])
opt.load_state_dict(_payload["opt"])
args = Args()
model = MaskedMLE.build_model(args, task)
reduce = True
max_epochs = 80
criterion = nn.NLLLoss(ignore_index=dataset.vocab.pad())
model = LossGenerator(model, criterion)
checkpoint_path = "/scratch/jerin/best_checkpoint.pt"
model = model.to(device)
model = DataParallel(model)
opt = optim.Adam(model.parameters())
if os.path.exists(checkpoint_path):
load(model, opt, checkpoint_path)
for epoch in tqdm(range(max_epochs), total=max_epochs, desc='epoch'):
pbar = tqdm_progress_bar(loader, epoch=epoch)
meters["loss"].reset()
count = 0
for src, src_lens, tgt, tgt_lens in pbar:
count += 1
opt.zero_grad()
src, tgt = src.to(device), tgt.to(device)
loss = model(src, src_lens, tgt)
loss.sum().backward()
meters['loss'].update(loss.mean().item())
pbar.log(meters)
opt.step()
avg_loss = meters["loss"].avg
meters['epoch'].update(avg_loss)
checkpoint(model, opt, checkpoint_path)
What are further improvements I could do? Could someone explain the internals of these things (loading, checkpoint) and best practices?