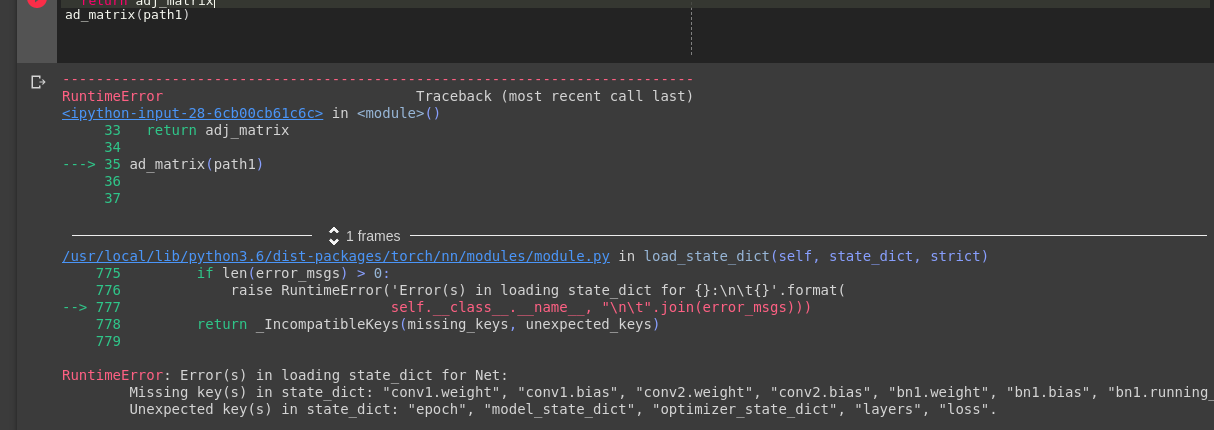
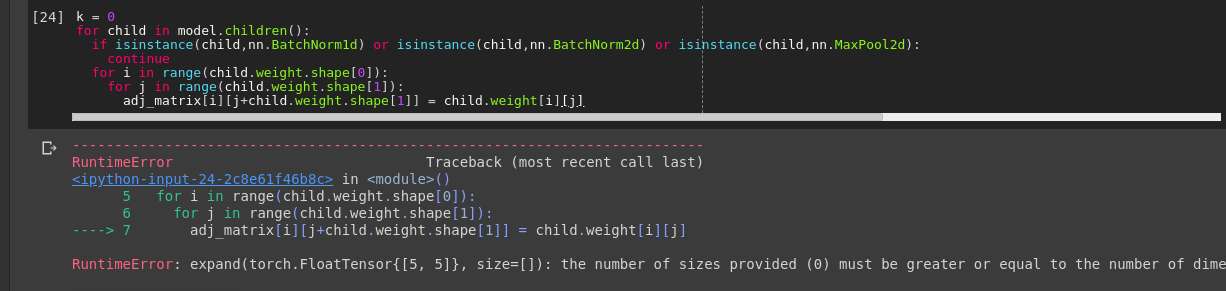
Thanks for the reply. I got rid of that error but am facing another one.
File “adj_matrix.py”, line 34, in
dim = child.weight.shape[1]
AttributeError: ‘Sequential’ object has no attribute ‘weight’
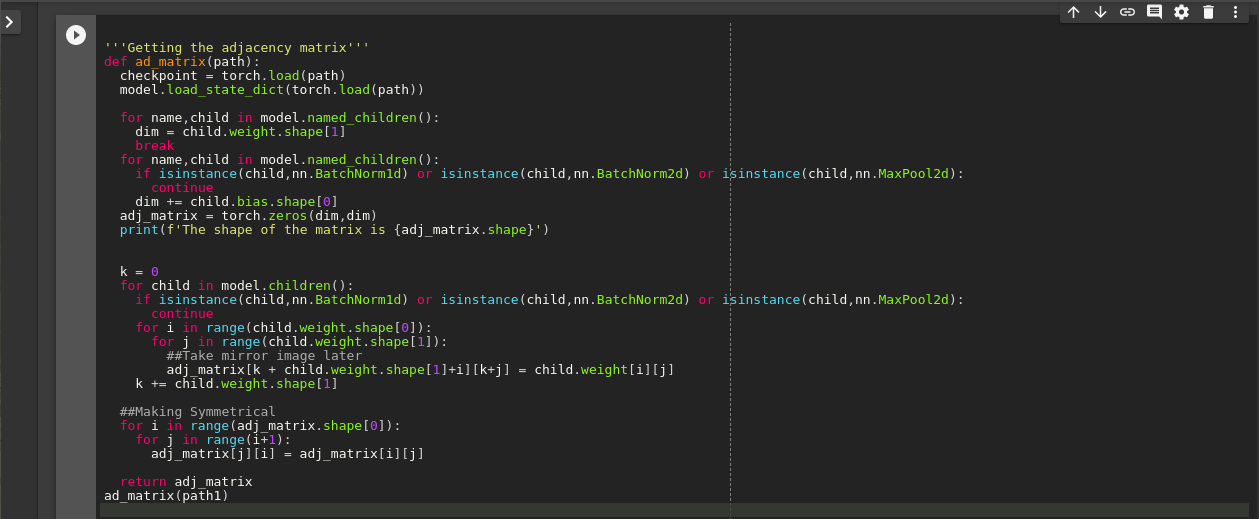
adj_matrix.py is the file to get an adjacency matrix from each layer in vgg. The adjacency matrix basically treats each channel in a layer as a node in an MLP and prints the edge weights connecting channels in the form of a matrix. For an MLPon NNIST, if I have 784+(128+64+10), the adj_matrix would be 986x986.
The pruned model with 188 and 313 channels mentioned above has been loaded into the adj_matrix.py. (from main_finetune.py in the repo below)
Code for adj_matrix.py:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torch.utils.data import Dataset, DataLoader, ConcatDataset, random_split
import numpy as np
from torch.utils.data import SubsetRandomSampler
import shutil
import argparse
import os
import models
from models import *
parser = argparse.ArgumentParser(description=‘Adjacency_Matrix’)
parser.add_argument(’–path’, default=’’, type=str, metavar=‘PATH’,
help=‘path to the model (default: none)’)
parser.add_argument(’–arch’,default=’’,type=str)
parser.add_argument(’–dataset’, type=str, default=‘cifar10’,
help=‘training dataset (default: cifar100)’)
parser.add_argument(’–depth’, default=19, type=int,
help=‘depth of the neural network’)
args = parser.parse_args()
if args.arch == ‘MLP’:
model = MLP()
else:
model = vgg(dataset=args.dataset, depth=args.depth)
##loading the model
if args.path:
checkpoint = torch.load(args.path)
model.load_state_dict(torch.load(args.path),strict=False)
print(f’Loaded Checkpoint:{args.path}’)
for name,child in model.named_children():
dim = child.weight.shape[1]
break
for name,child in model.named_children():
if isinstance(child,nn.BatchNorm1d) or isinstance(child,nn.BatchNorm2d) or isinstance(child,nn.MaxPool2d):
continue
dim += child.bias.shape[0]
adj_matrix = np.zeros((dim,dim))
print(f’The shape of the matrix is {adj_matrix.shape}’)
k = 0
for child in model.children():
if isinstance(child,nn.BatchNorm1d) or isinstance(child,nn.BatchNorm2d) or isii
nstance(child,nn.MaxPool2d):
continue
for i in range(child.weight.shape[0]):
for j in range(child.weight.shape[1]):
##Take mirror image later
adj_matrix[k + child.weight.shape[1]+i][k+j] = child.weight[i][j]
k += child.weight.shape[1]
##Making Symmetrical
for i in range(adj_matrix.shape[0]):
for j in range(adj_matrix.shape[1]):
adj_matrix[j][i] = adj_matrix[i][j]
The pruning method is basically applying L1 norm on the scaling factor gamma in batchNorm. After that, the small scaling factors are eliminated leadng to elimination of nodes in the hidden layers of the model. In case of VGG, some channels in intermediate layers would vanish.
Here is the repo: https://github.com/Eric-mingjie/rethinking-network-pruning/tree/master/cifar/network-slimming