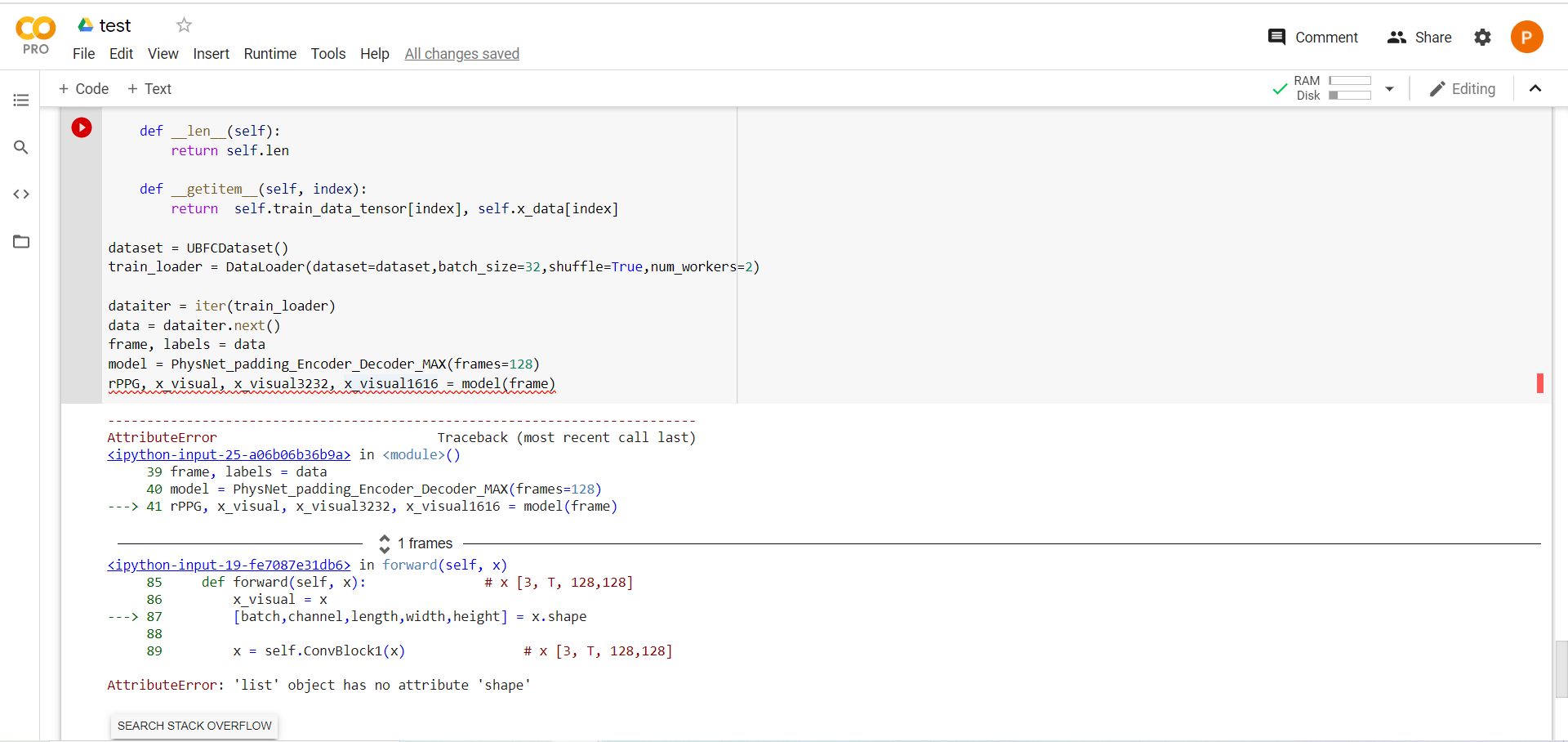
Yeah, but I need to get the length dimension which means total length of the inputs, How can I get the tensor shape right?
Here is the model in which I am trying to feed my inputs:
Only for research purpose, and commercial use is not allowed.
MIT License
Copyright (c) 2019
'''
import math
import torch.nn as nn
from torch.nn.modules.utils import _triple
import torch
import pdb
class PhysNet_padding_Encoder_Decoder_MAX(nn.Module):
def __init__(self, frames=128):
super(PhysNet_padding_Encoder_Decoder_MAX, self).__init__()
self.ConvBlock1 = nn.Sequential(
nn.Conv3d(3, 16, [1,5,5],stride=1, padding=[0,2,2]),
nn.BatchNorm3d(16),
nn.ReLU(inplace=True),
)
self.ConvBlock2 = nn.Sequential(
nn.Conv3d(16, 32, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(32),
nn.ReLU(inplace=True),
)
self.ConvBlock3 = nn.Sequential(
nn.Conv3d(32, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.ConvBlock4 = nn.Sequential(
nn.Conv3d(64, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.ConvBlock5 = nn.Sequential(
nn.Conv3d(64, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.ConvBlock6 = nn.Sequential(
nn.Conv3d(64, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.ConvBlock7 = nn.Sequential(
nn.Conv3d(64, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.ConvBlock8 = nn.Sequential(
nn.Conv3d(64, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.ConvBlock9 = nn.Sequential(
nn.Conv3d(64, 64, [3, 3, 3], stride=1, padding=1),
nn.BatchNorm3d(64),
nn.ReLU(inplace=True),
)
self.upsample = nn.Sequential(
nn.ConvTranspose3d(in_channels=64, out_channels=64, kernel_size=[4,1,1], stride=[2,1,1], padding=[1,0,0]), #[1, 128, 32]
nn.BatchNorm3d(64),
nn.ELU(),
)
self.upsample2 = nn.Sequential(
nn.ConvTranspose3d(in_channels=64, out_channels=64, kernel_size=[4,1,1], stride=[2,1,1], padding=[1,0,0]), #[1, 128, 32]
nn.BatchNorm3d(64),
nn.ELU(),
)
self.ConvBlock10 = nn.Conv3d(64, 1, [1,1,1],stride=1, padding=0)
self.MaxpoolSpa = nn.MaxPool3d((1, 2, 2), stride=(1, 2, 2))
self.MaxpoolSpaTem = nn.MaxPool3d((2, 2, 2), stride=2)
#self.poolspa = nn.AdaptiveMaxPool3d((frames,1,1)) # pool only spatial space
self.poolspa = nn.AdaptiveAvgPool3d((frames,1,1))
def forward(self, x): # x [3, T, 128,128]
x_visual = x
[batch,channel,length,width,height] = x.shape
x = self.ConvBlock1(x) # x [3, T, 128,128]
x = self.MaxpoolSpa(x) # x [16, T, 64,64]
x = self.ConvBlock2(x) # x [32, T, 64,64]
x_visual6464 = self.ConvBlock3(x) # x [32, T, 64,64]
x = self.MaxpoolSpaTem(x_visual6464) # x [32, T/2, 32,32] Temporal halve
x = self.ConvBlock4(x) # x [64, T/2, 32,32]
x_visual3232 = self.ConvBlock5(x) # x [64, T/2, 32,32]
x = self.MaxpoolSpaTem(x_visual3232) # x [64, T/4, 16,16]
x = self.ConvBlock6(x) # x [64, T/4, 16,16]
x_visual1616 = self.ConvBlock7(x) # x [64, T/4, 16,16]
x = self.MaxpoolSpa(x_visual1616) # x [64, T/4, 8,8]
x = self.ConvBlock8(x) # x [64, T/4, 8, 8]
x = self.ConvBlock9(x) # x [64, T/4, 8, 8]
x = self.upsample(x) # x [64, T/2, 8, 8]
x = self.upsample2(x) # x [64, T, 8, 8]
x = self.poolspa(x) # x [64, T, 1,1] --> groundtruth left and right - 7
x = self.ConvBlock10(x) # x [1, T, 1,1]
rPPG = x.view(-1,length)
return rPPG, x_visual, x_visual3232, x_visual1616