I am encountering issues where depending on how I load a model I obtain different results.
I have built a small test example which I have attached below that illustrates my problem. I have compared three different methods of loading the model:
- loading the model directly from hugging face
- loading the model from a complete model checkpoint file
- loading the model from a checkpoint file of the model state dict only
I tested the models on the same randomly generated input images.
The weights and state dicts of the models using the 3 methods described are identical.
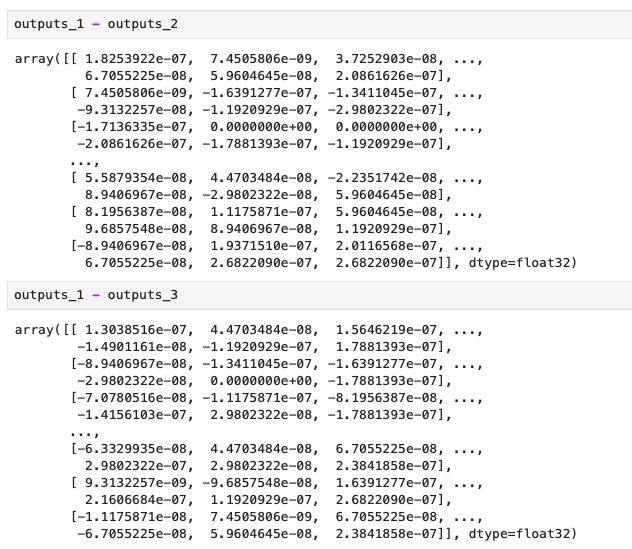
The inference results generated by the 1st and the 3rd method are much more similar but still not the same.
Anyone have any ideas? I am completely at a loss what could be the result of this issue and how I should properly save and load my checkpoints to e.g. resume a training.
from transformers import ViTMAEForPreTraining
import torch
import gc
import pytorch_lightning as pl
import numpy as np
torch.cuda.empty_cache()
#define model
class TransformerModel(pl.LightningModule):
def __init__(self):
super().__init__()
self.model = ViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
self.model.config.mask_ratio = 0.75
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
imgs, labels = batch
out = self(imgs)
loss = out.loss
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
imgs, labels = batch
out = self(imgs)
loss = out.loss
self.log("val_loss", loss)
return loss
def configure_optimizers(self):
optimizer = torch.optim.AdamW(self.parameters(), lr=0.001)
return optimizer
def unpatchify(self, x):
p = self.model.vit.embeddings.patch_embeddings.patch_size[0]
h = w = int(x.shape[1]**.5)
assert h * w == x.shape[1]
x = x.reshape(shape=(x.shape[0], h, w, p, p, 3))
x = torch.einsum('nhwpqc->nchpwq', x)
imgs = x.reshape(shape=(x.shape[0], 3, h * p, h * p))
return imgs
#load model
model_1 = TransformerModel()
model_1.eval()
#save complete model as checkpoint
torch.save(model_1, "vit_mae_from_hugging_face.pth")
#save statedict only
torch.save(model_1.state_dict(), "vit_mae_from_hugging_face_statedict.pth")
#load model from checkpoint
model_2 = torch.load("vit_mae_from_hugging_face.cpkt")
model_2.eval()
#load state-dict only
model_3 = TransformerModel()
model_3.load_state_dict(torch.load("vit_mae_from_hugging_face_statedict.pth"))
model_3.eval()
#initialize hook to get intermediate outputs
layer_outputs = {}
def get_intermediate_1(module, input, output):
layer_outputs['encoder_layernorm_1'] = output
def get_intermediate_2(module, input, output):
layer_outputs['encoder_layernorm_2'] = output
def get_intermediate_3(module, input, output):
layer_outputs['encoder_layernorm_3'] = output
model_1.model.vit.layernorm.register_forward_hook(get_intermediate_1)
model_2.model.vit.layernorm.register_forward_hook(get_intermediate_2)
model_3.model.vit.layernorm.register_forward_hook(get_intermediate_3)
#create a seeded random input tensor
torch.manual_seed(42)
tensor = torch.randn(8, 3, 224, 224)
#pass images to the two models
model_1(tensor)
model_2(tensor)
model_3(tensor)
outputs_1 = torch.mean(layer_outputs['encoder_layernorm_1'], axis = 1).detach().numpy()
outputs_2 = torch.mean(layer_outputs['encoder_layernorm_2'], axis = 1).detach().numpy()
outputs_3 = torch.mean(layer_outputs['encoder_layernorm_3'], axis = 1).detach().numpy()
#compare outputs
print("Output 1 vs Output2")
print((outputs_1 == outputs_2).all())
print("Output 2 vs Output3")
print((outputs_2 == outputs_3).all())
print("Output 1 vs Output3")
print((outputs_1 == outputs_3).all())
#compare model weights
print(((model_1.state_dict()['model.vit.embeddings.patch_embeddings.projection.weight']) == (model_2.state_dict()['model.vit.embeddings.patch_embeddings.projection.weight'])).all())
print(((model_1.state_dict()['model.vit.embeddings.patch_embeddings.projection.weight']) == (model_3.state_dict()['model.vit.embeddings.patch_embeddings.projection.weight'])).all())
print(((model_2.state_dict()['model.vit.embeddings.patch_embeddings.projection.weight']) == (model_3.state_dict()['model.vit.embeddings.patch_embeddings.projection.weight'])).all())
#compare complete state_dicts
for key in model_1.state_dict():
value = (model_1.state_dict()[key] == model_2.state_dict()[key]).all()
if not value:
print(value)
for key in model_1.state_dict():
pvalue = (model_1.state_dict()[key] == model_3.state_dict()[key]).all()
if not value:
print(value)
This returns:
Output 1 vs Output2
False
Output 2 vs Output3
False
Output 1 vs Output3
False
tensor(True)
tensor(True)
tensor(True)
Numerically the outputs generated by approach 1 and approach 3 are much more similar than those generated by approach 2.