Dear all,
I am trying to train my own Resnet model using .npy format files.
I am wondering that are there any functions like torchvision.datasets.ImageFolder that can load .npy files in a folder and label these numpy array with their folder name?
Dear all,
I am trying to train my own Resnet model using .npy format files.
I am wondering that are there any functions like torchvision.datasets.ImageFolder that can load .npy files in a folder and label these numpy array with their folder name?
Hi,
No such dataset exist at the moment.
I guess you can load the files, convert these to torch tensor and create a TensorDataset from them.
Alternatively to @albanD’s solution, you could also use DatasetFolder, which basically is the underlying class of ImageFolder.
Using this class you can provide your own files extensions and loader to load the samples.
def npy_loader(path):
sample = torch.from_numpy(np.load(path))
return sample
dataset = datasets.DatasetFolder(
root='PATH',
loader=npy_loader,
extensions=['.npy']
)
If you want to use transformations, you would need to convert the sample tensors to PIL.Images in your loader.
Thank you ptrblck! That did work!
Hello ptrblck…I am facing the same problem but I am getting some errors…
RuntimeError: Found 0 files in subfolders of: cifar-100//cifar-100-python//pylearn2_gcn_whitened//train//
Supported extensions are: .npy
so, if I change the code:
path='cifar-100/cifar-100-python/pylearn2_gcn_whitened/train/train.npy'
sample_train = torch.from_numpy(np.load(path))
print(len(sample_train)) #50000
path='cifar-100/cifar-100-python/pylearn2_gcn_whitened/test/test.npy'
sample_test = torch.from_numpy(np.load(path))
print(len(sample_test)) #10000
I can get them as tensors on each variables, but I dont know how to transform them to type dataset.
note: this datasets were transformed from the original cifar100 but using the library pylearn2
The use case in the original question was that instead of images in subfolders, .npy files were located in these subfolders.
Since ImageFolder only looks for image files, I suggested to use DatasetFolder with a custom loader.
However, your use case is different, since you have a single .npy file with apparently all images stored inside of it.
In that case, you should stick to @albanD’s solution and use TensorDataset(torch.from_numpy(np.load(path))).
Thanks ptrblck
I solved that with saving them in a pt file and then creating a Custom Dataset
__author__ = 'mangate'
from six.moves import cPickle as pickle
import numpy as np
import os
import fnmatch
import sys
#import matplotlib.pyplot as plt
from pylearn2.datasets.cifar100 import CIFAR100
import torch
"""
This file opens the CIFAR100 data after whitening and ZCA made by 'process_cifar_100_data' script
which uses pylearn2 library
This file also re-arragne the data so it can enter a nueral net properly
"""
image_size = 32
num_channels = 3
num_classes = 100
pixel_depth = 255.0
def unpickle(file):
#import pickle
#import cPickle
import _pickle as cPickle
fo = open(file, 'rb')
dict = cPickle.load(fo)
fo.close()
return dict
def rearrange_data(data,labels):
#data = np.cast['float32'](data)
#data = data / 255.
#data = data - data.mean(axis=0)
images = np.ndarray(shape=(len(labels),image_size,image_size,num_channels), dtype=np.float32)
labels_out = np.zeros(shape=(len(labels),num_classes),dtype=np.float32)
max = len(labels)
for i in range(max):
images[i] = np.reshape(data[i],(3,32,32)).transpose(1,2,0)
#plt.imshow(images[i])
#plt.show()
labels_out[i][labels[i]]=1.0
return images,labels_out
def process_data(file_name):
data = unpickle(file_name)
# images = data['data']
# labels = data['fine_labels']
images = np.asarray(data.X)
labels = np.asarray(data.y)
images,labels = rearrange_data(images,labels)
return images,labels
def get_data():
ROOT_FOLDER ="D:\\Neural_Nets\\ELU_NETWORK\\cifar100\\cifar-100-python\\pylearn2_gcn_whitened\\"
train_images, train_labels = process_data(ROOT_FOLDER+'train.pkl')
test_images,test_labels = process_data(ROOT_FOLDER+'test.pkl')
# ROOT_FOLDER = '/cs/img/mangate/thesis/Cifar-100/cifar-100-python/'
#
# train_images, train_labels = process_data(ROOT_FOLDER+'train')
# test_images,test_labels = process_data(ROOT_FOLDER+'test')
print ('Train Date shape is',train_images.shape, 'and labels is',train_labels.shape)
print ('Test Date shape is',test_images.shape, 'and labels is',test_labels.shape)
torch.save(train_images,'train_images.pt')
torch.save(train_labels,'train_labels.pt')
torch.save(test_images,'test_images.pt')
torch.save(test_labels,'test_labels.pt')
return train_images, train_labels, test_images,test_labels
get_data()
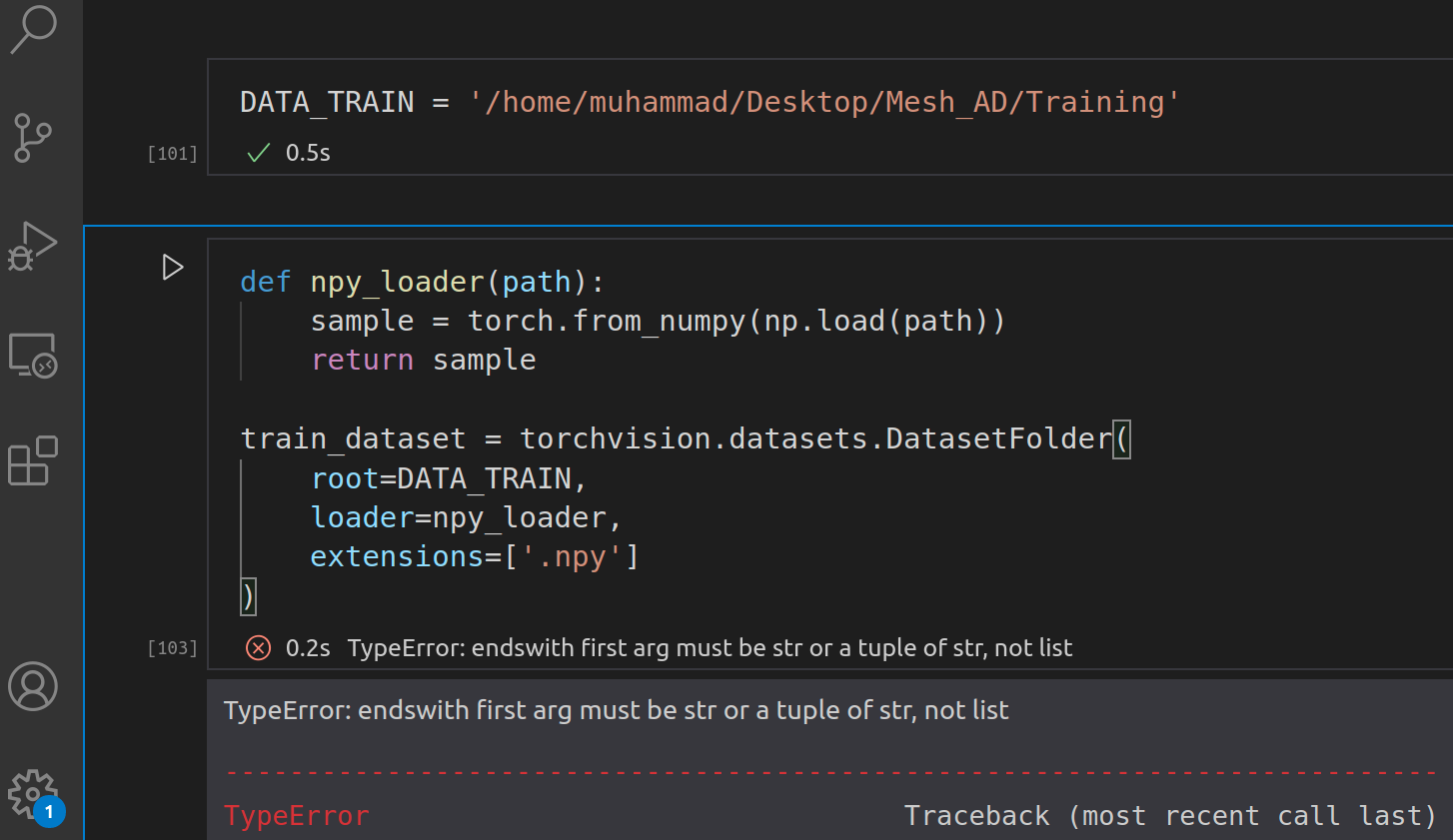
Thank you @ptrblck for providing a solution to this problem. I was facing the same problem, luckily I found this post. But when I run this code I face another Error. Can you please help me to solve it.
TypeError: endswith first arg must be str or a tuple of str, not list
Based on the error message it seems you are passing a list to endswith as the first argument, which is not supported, so you would need to pass either a str or a tuple of str.
text = 'lala'
text.endswith('a') # works
text.endswith(('a', 'la')) # works
text.endswith(['a', 'la'])
> TypeError: endswith first arg must be str or a tuple of str, not list
Thank you @ptrblck for your quick reply, but I am still confused with the same Error. Below is the pic of my code. Training folder contains three subfolders with labels name and each subfolder contains various .npy files. Where do I should change my code or update any library or folder? How can I load this data?
Use extensions='.npy' or extensions=('.npy'), as the error is raised by DatasetFolder.
Thanks @ptrblck. Yes, now it works.
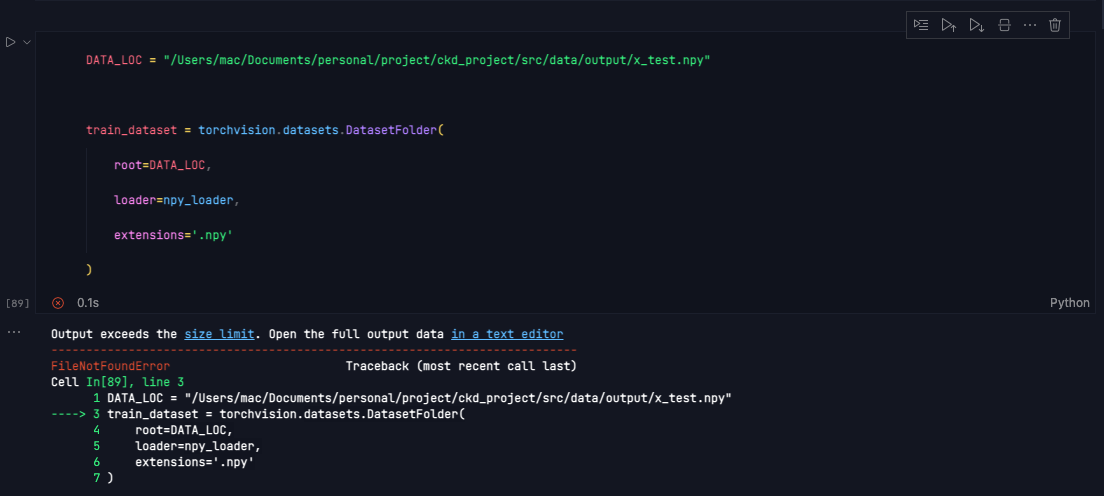
root should point to the root directory containing subfolders with the actual data for each corresponding class. FileNoFoundErrors are raised if e.g. np.load cannot load the specified file.
Thank you very much for the nodge @ptrblck - I checked the documentation and apparently, I have to use the naming convention of class_x and class_y for it to work. ![]()
No It did not work for me. I made following changes that worked:
class NPYDatasetFile(Dataset):
“”“@Deba.”“”
def __init__(self, root_dir, transform=None):
"""
Args:
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.csv_file="face_landmarks.csv" ###must have
self.landmarks_frame = pd.read_csv(root_dir + self.csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = os.path.join(self.root_dir,
self.landmarks_frame.iloc[idx, 0])
image = np.load(img_name)
sample=np.zeros((1,4*nside,3*nside)) ###for my data shape ##
sample[0] = image#{'image': image}
if self.transform:
sample = self.transform(sample)
return sample
transformed_dataset = NPYDatasetFile(root_dir=path)
dataloader = DataLoader(transformed_dataset, batch_size=4,
shuffle=True, num_workers=4)
It’s unclear what exactly did not work for you using the DatasetFolder approach using a custom loader explained in my post, as you are not even using this class. Also your code is neither executable nor does it show any errors.