Hi, I’m considering to build a network like this:
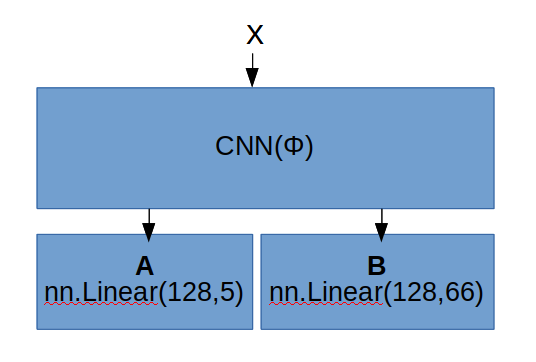
- Each linear layer A,B receive 128 dim output from CNN(Φ).
- CNN’s parameters are trained in another task, and saved as
model.pth. - Now I want to train A,B layers and CNN in new task.
In this case, is next pseudo code works properly?
model = CNN() # class CNN() defines Φ's archtecture
model.load_state_dict(torch.load("model.pth"))
modelA = LinearUnitA()
modelB = LinearUnitB()
optim = optimizer_definition() # some operations to define optimizer
for i in N_training:
f_128 = model.forward(input_tensor)
outputA = modelA.forward(f_128)
outputB = modelA.forward(f_128)
lossA = loss_computation_A(outputA)
lossB = loss_computation_B(outputB)
lossA.backward()
lossB.backward()
optim.step()
Thanks.
