I’m creating an incremental TTS model, the model is based on Incremental Machine Speech Chain
Towards Enabling Listening while Speaking in Real-time
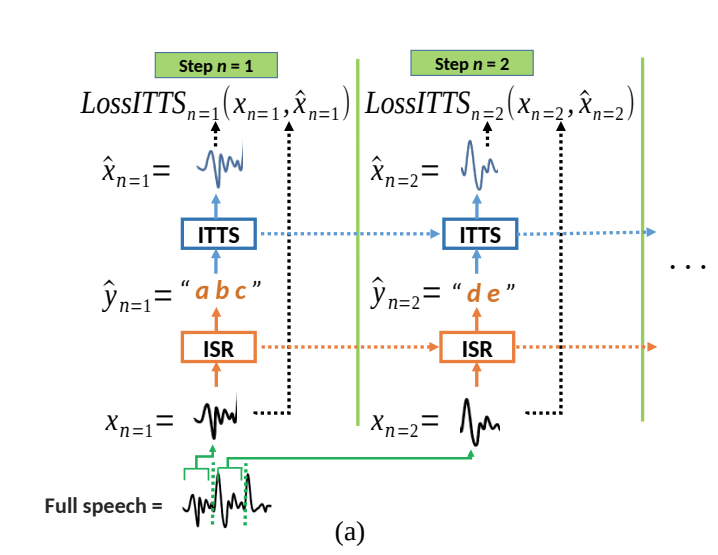
In this paper, they describe passing a small section of audio (windowing) for training as shown in the diagram below:
What is the best way to load my data for training? (The dataset consists of Pulse-Code Modulation (PCM) and labels )
What I’ve tried so far?
For each tensor in a batch, I create a new tenor using the method shown Here. and this new tensor is used for training.
for i, batch in enumerate(train_loader):
x, y = ttsModel.parse_batch(batch) # send data to GPU
for tensor in x:
windowed_datas = window_split(tensor)
for windowed_data in windowed_datas:
tts_output, hd0, he0 = ttsModel(windowed_data, hd0, he0)
I already see an issue, the model is no longer training on batches but single tensors.
I’ve tried this approach in the torch.utils.data.Dataloader using the collate_fn Nvidia: Tacotron 2, but I’m not sure if this is correct for the model.
class TextAudioCollate():
""" Zero-pads model inputs and targets based on number of frames per setep """
def __init__(self, n_frames_per_step):
self.n_frames_per_step = n_frames_per_step
def __call__(self, batch):
"""Collate's training batch from normalized text and mel-spectrogram
PARAMS
------
batch: [text_normalized, mel_normalized]
"""
# Right zero-pad all one-hot text sequences to max input length
input_lengths, ids_sorted_decreasing = torch.sort( torch.LongTensor([len(batch[i][1]) for i in range(len(batch))]), dim=0, descending=True)
max_input_len = input_lengths[0]
# max_input_len = 512
text_padded = torch.LongTensor(len(batch), max_input_len)
text_padded.zero_()
for i in range(len(ids_sorted_decreasing)):
text = batch[ids_sorted_decreasing[i].numpy()][1]
text_padded[i, :text.size(0)] = text
# Right zero-pad mel-spec
num_mels = batch[0][0].size(0)
max_target_len = max([batch[i][0].size(1) for i in range(len(batch))])
if max_target_len % self.n_frames_per_step != 0:
max_target_len += self.n_frames_per_step - max_target_len % self.n_frames_per_step
assert max_target_len % self.n_frames_per_step == 0
# include mel padded and gate padded
mel_padded = torch.FloatTensor(len(batch), num_mels, max_target_len)
mel_padded.zero_()
gate_padded = torch.FloatTensor(len(batch), max_target_len)
gate_padded.zero_()
output_lengths = torch.LongTensor(len(batch))
for i in range(len(ids_sorted_decreasing)):
mel = batch[ids_sorted_decreasing[i].numpy()][0]
mel_padded[i, :, :mel.size(1)] = mel
gate_padded[i, mel.size(1)-1:] = 1
output_lengths[i] = mel.size(1)
# Windowing
text_windowed = []
for text in text_padded:
text_windowed.append(window_split(text))
audio_windowed = []
for audio in mel_padded:
audio_windowed.append(window_split(audio))
return (text_windowed, audio_windowed)