The goal is to perform instance segmentation with input RGB images and corresponding ground truth labels.
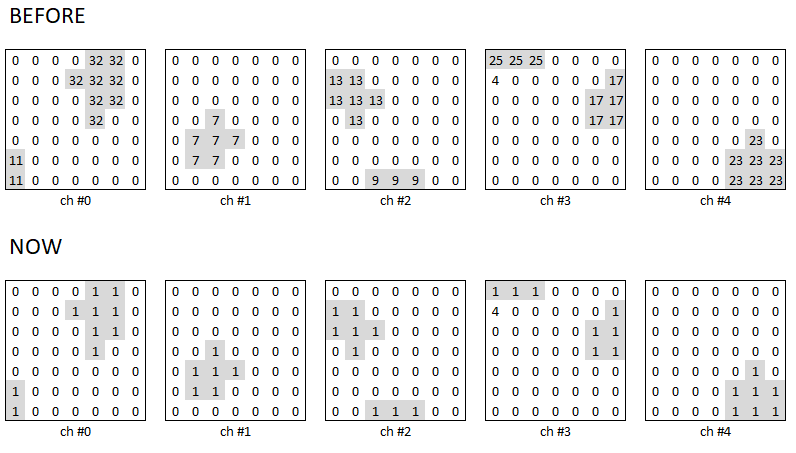
The ground truth label is multi-channel i.e. each class has a separate channel and there are different instances in each channel denoted by unique random numbers. Each label consists of 5 non-background classes (no background class info). The following figure will give a better insight into the labels (please note that the actual dimension is 128x128 not 7x7).
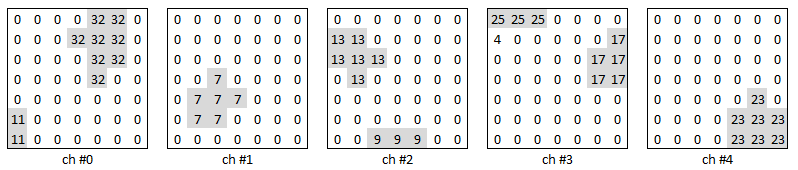
A label may have multiple instances of the same class objects.
Logit predictions were obtained on a batch data [64, 5, 128, 128] i.e. [B, C, W, H] from a typical U-Net (in a forward pass) and then passed through a sigmoid layer to get the normalized predictions in the interval [0,1]. There were so many problems encountered right before performing the backward pass and some of those are:
-
nn.BCELoss(): reported loss for the batches was either too low i.e. {0.0310, 0.0470, 0.1696,…} or negative i.e. {-0.2363, -0.0790, -0.1972,…}. I can’t think of a reason other than normalization of logits BUT sigmoid layer had already normalized the target values in interval [0,1]. (?) -
nn.CrossEntropyLoss(): This loss gave an error (as reported below). My understanding is to construct a single channel i.e. [64, 1, 128, 128] to use this loss function but I haven’t tried this idea.
ret = torch._C._nn.nll_loss2d(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
RuntimeError: 1only batches of spatial targets supported (3D tensors) but got targets of size: : [64, 5, 128, 128]
I do understand that Dice, IOU, Jaccard,… are the popular loss functions for segmentation problems in addition to the cross-entropy based losses.
Would you please tell me where did I make the mistakes above? Is it the formulation of target labels?