Thanks @KFrank for your time.

I want a U-Net to learn the ground truth labels to perform the instance segmenttaion task. In semantic segmentation, all objects of the same type are marked using one class label while in instance segmentation similar objects get their own separate labels.
The problem is I cannot figure out a suitable encoding scheme that can work with the loss functions implemented in the PyTorch.
The input to BCELoss is the model output after passing through sigmoid. Overall, I followed this sequence:
RGB images + 5D labels (input) —> model —> 5D logit output —> sigmoid() —> BCELoss()/CrossEntropyLoss()
The number of input channels to a model can be different from the number of output channels. Please correct me if I’m wrong. I’ve seen so many segmentation models designed this way while using the CrossEntropyLoss(). My best guess is some problem with the way target labels are encoded.
Yes, my model takes a batch of [3, 128, 128] images and [5, 128, 128] of target labels as input.
I would like to read some relevant research work using such a formulation. It’s quite interesting that you used nColor and nChannel differently as opposed to the conventional wisdom that says nColor = nChannel. For instance, nColor = nChannel = 3 in an RGB image of size 3x128x128.
Can you please elaborate on this?
A single label is of size [5, 128, 128] where nChannel = 5 is indicating the nClass = 5 which means foreground pixels in each input image may belong to any of the five classes.
Referring to the figure in the initial post, 0 means a background pixel, any non-zero value means a foreground pixel. Random numbers were assigned just to distinguish multiple foreground instances belonging to the same class (Note: each class is a separate channel). By the way, assigning 1 to every foreground pixels in target labels (as in the figure below) let BCELoss() to produce reasonable values. However, I’m not sure how the multiple occurrences of foreground objects from the same class can be identified in the model output (since the model cannot infer this from the labels).
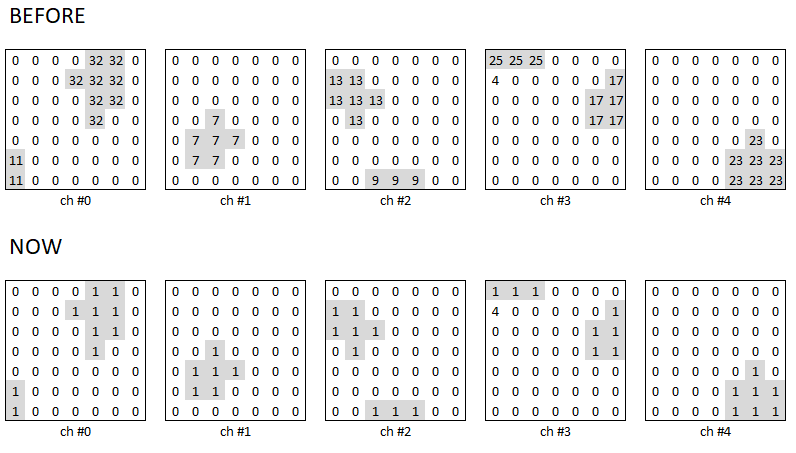
Not at all since the foreground objects have heterogeneous shapes and can be found anywhere in an image. It’s nothing more than a way to tell the model that there are different instances of the class-X.