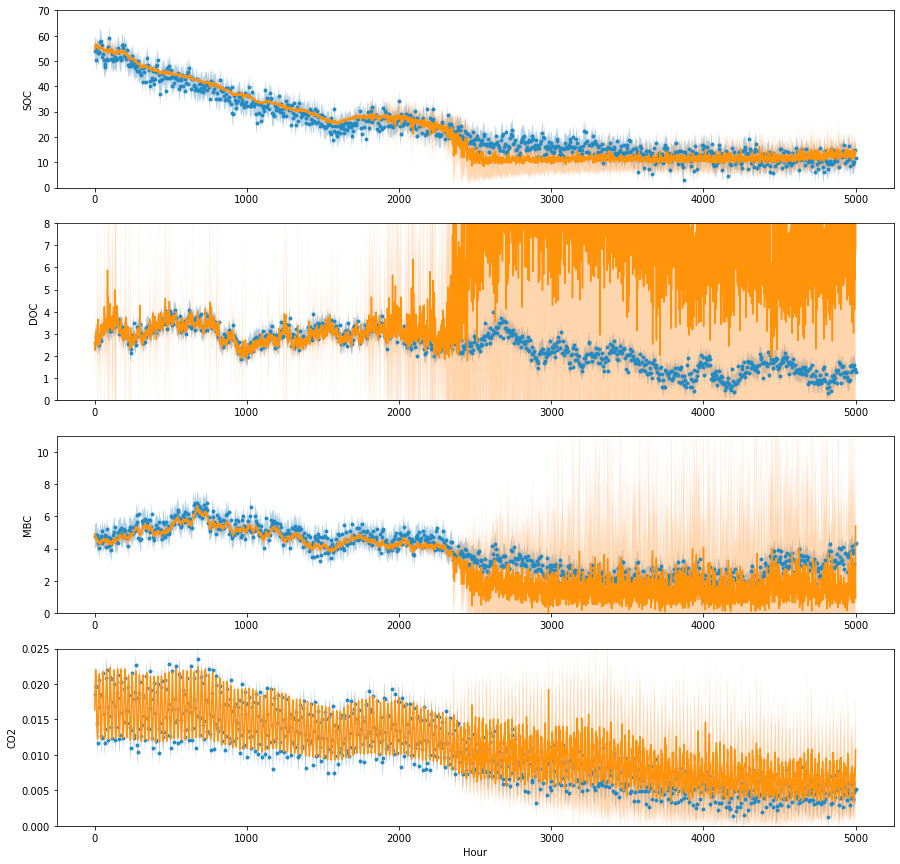
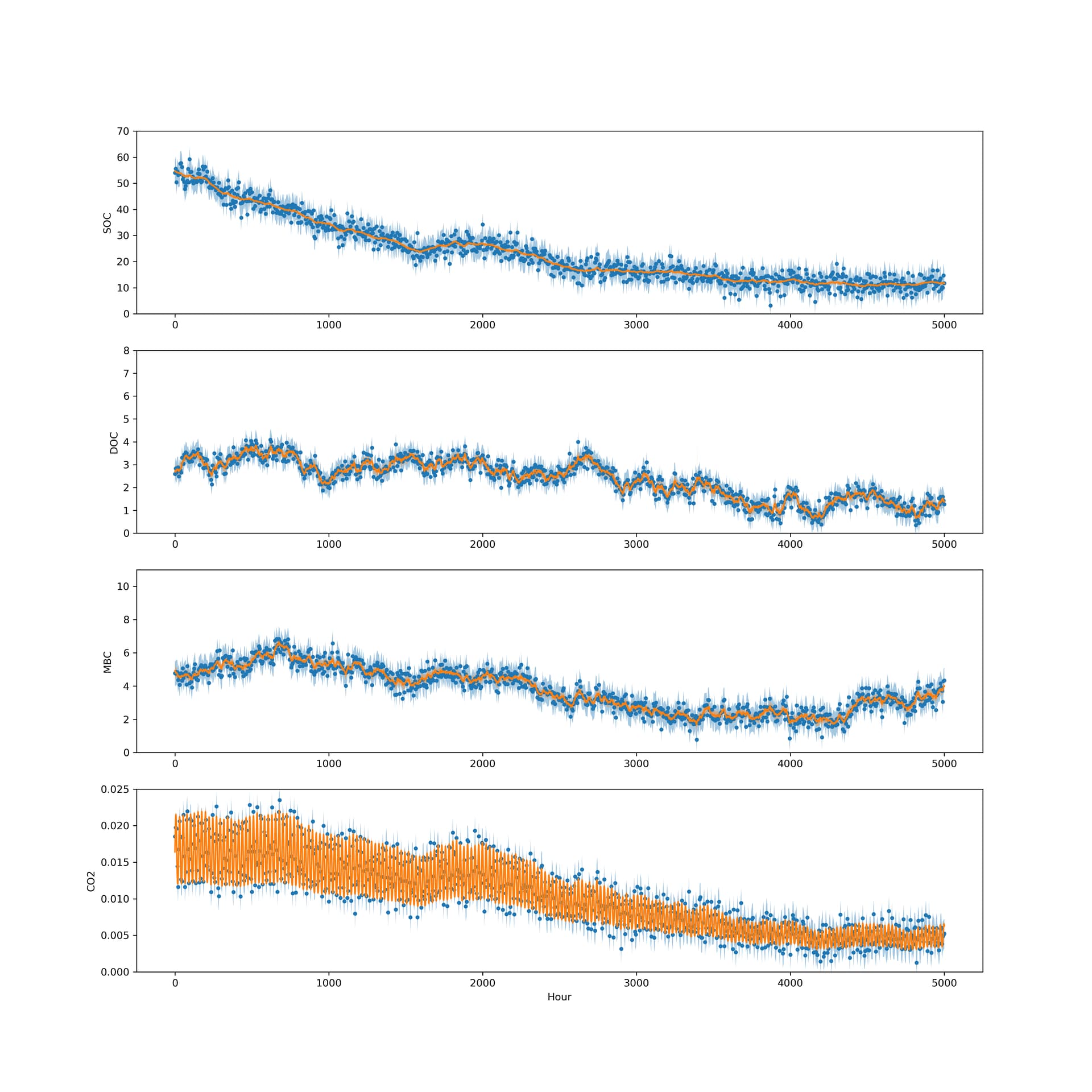
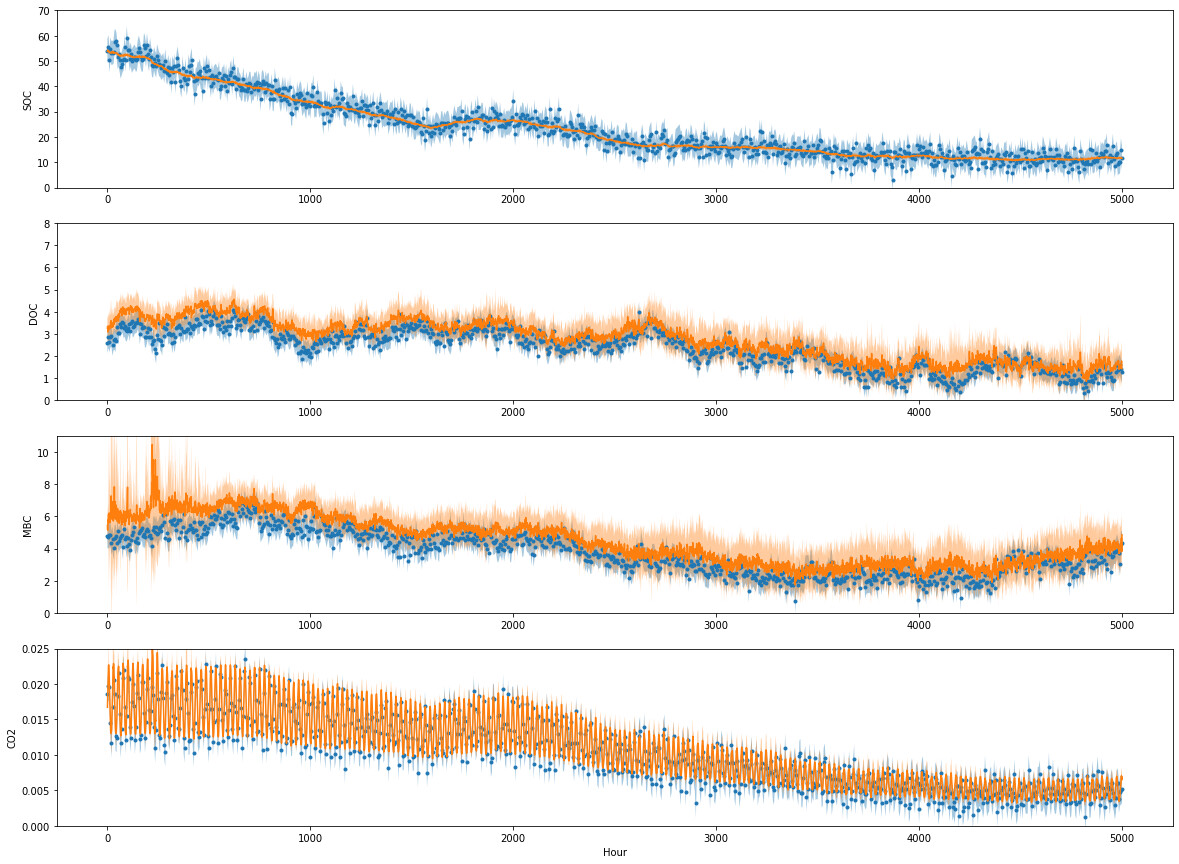
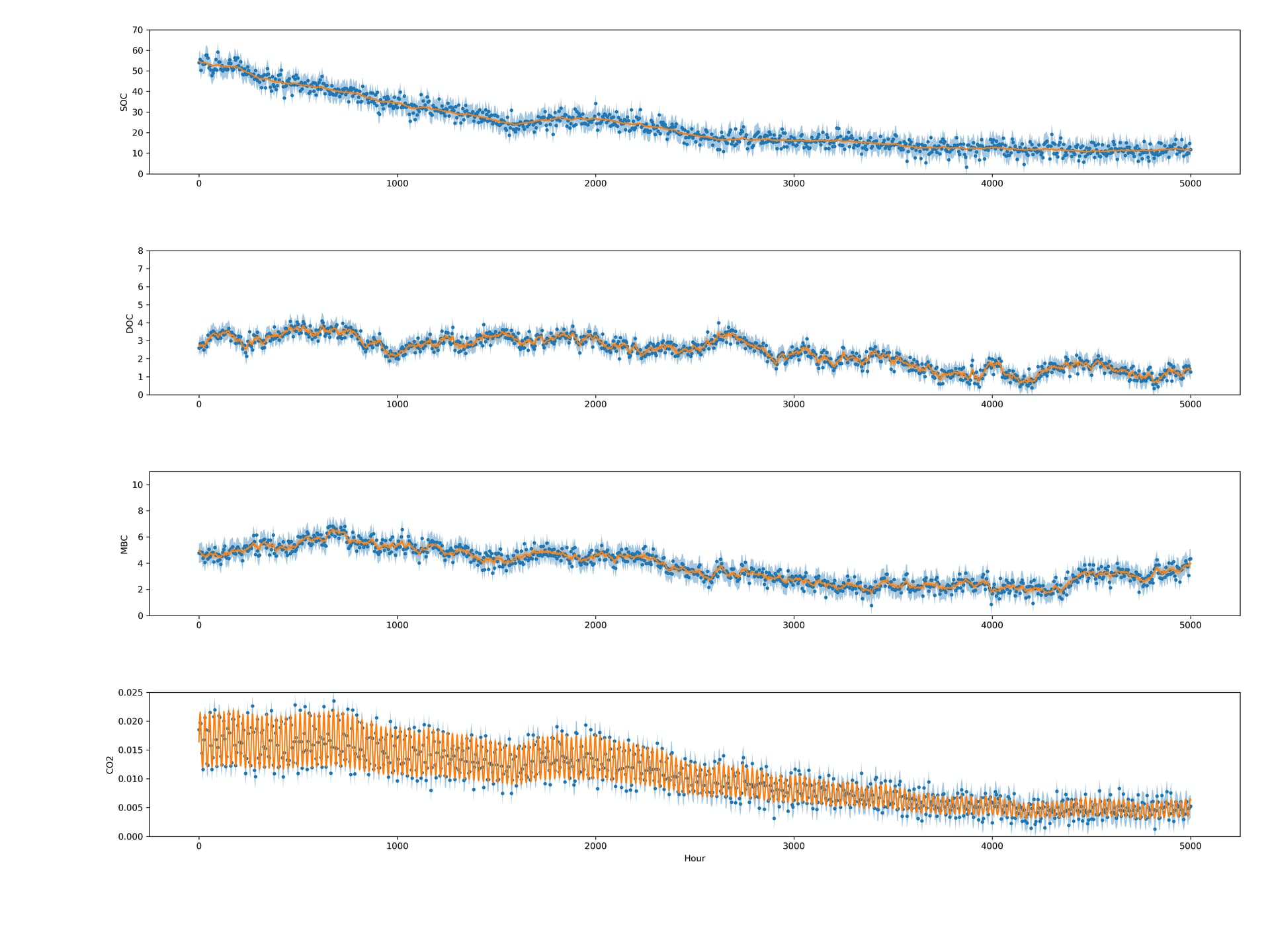
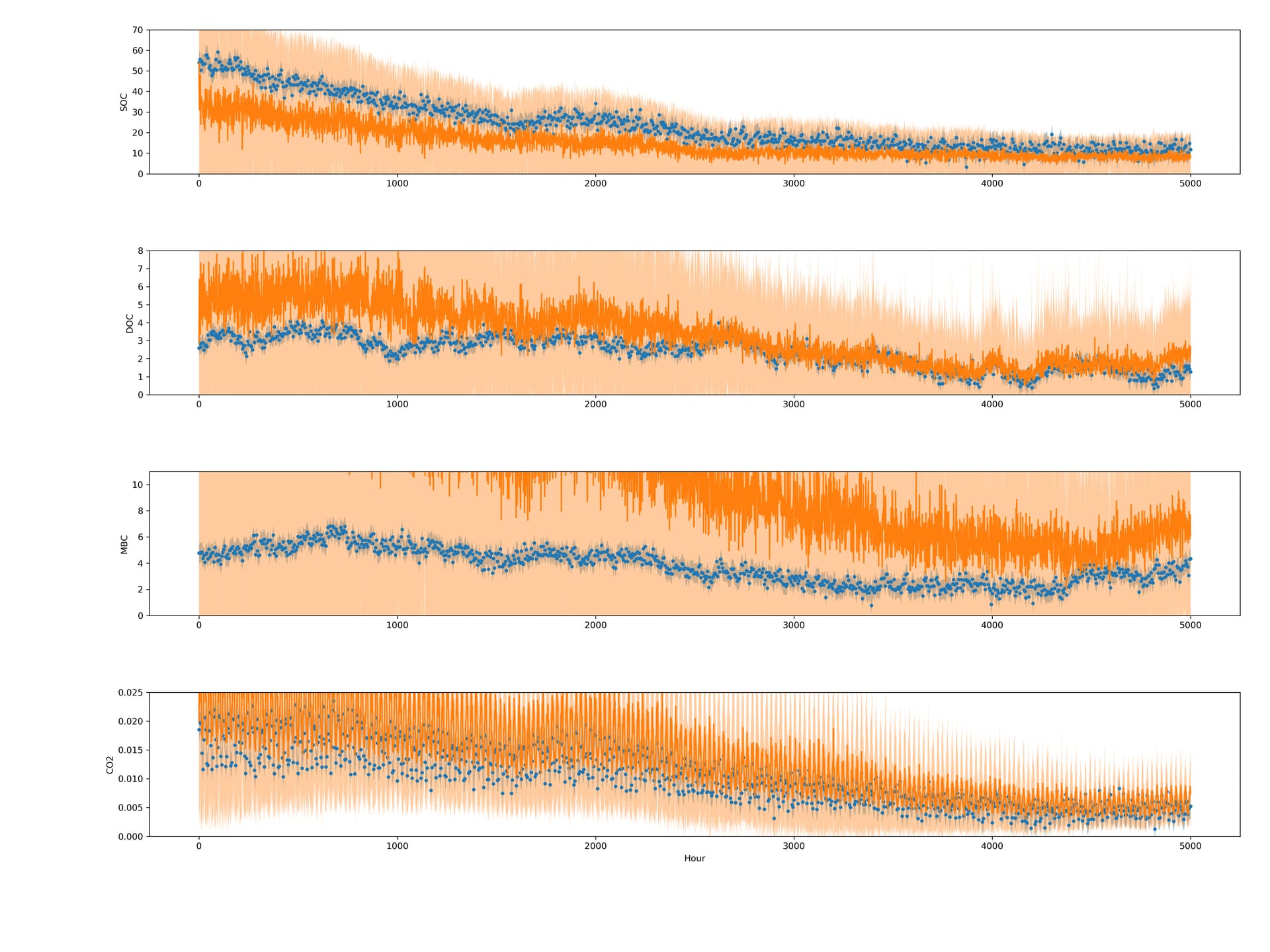
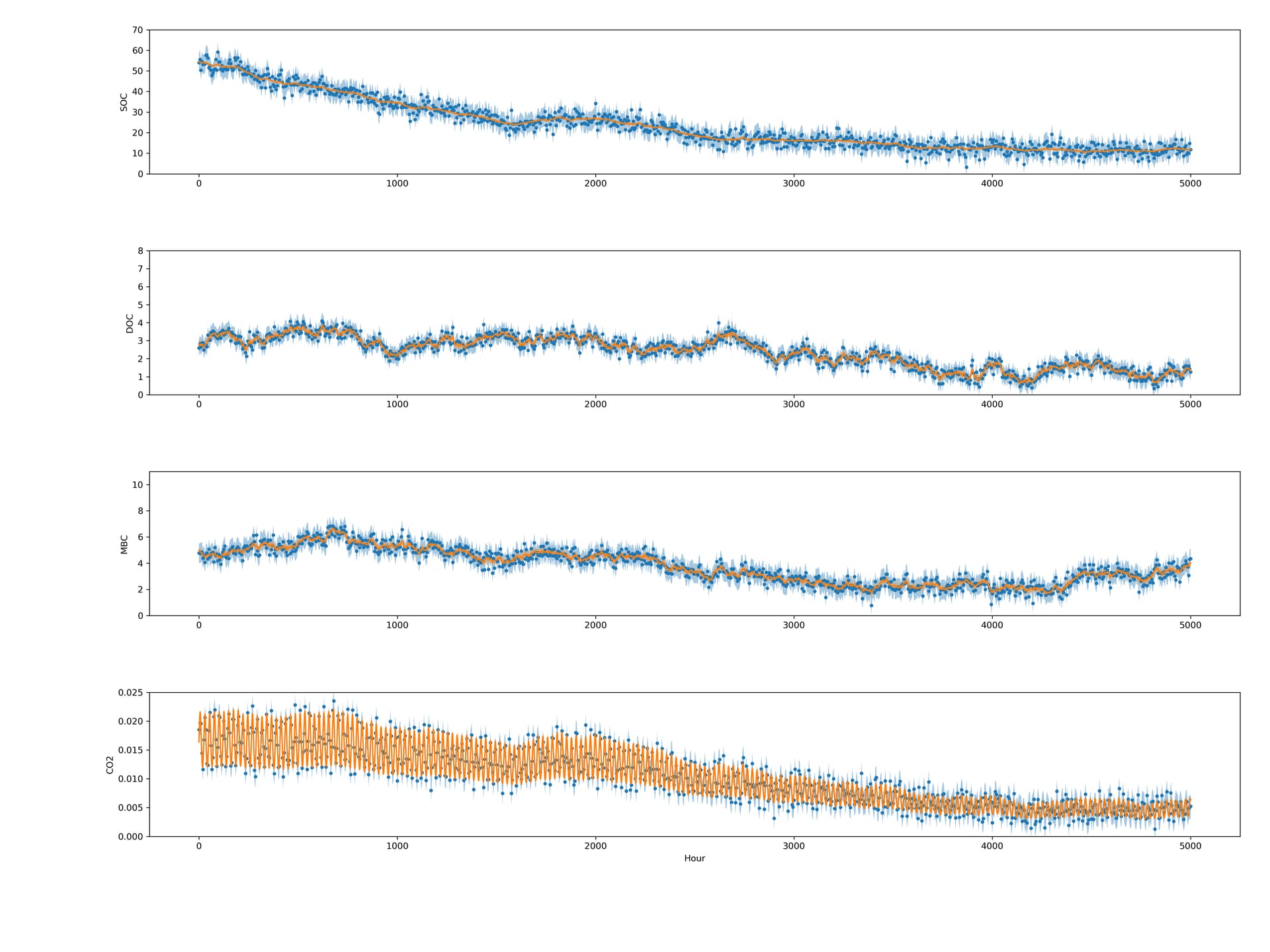
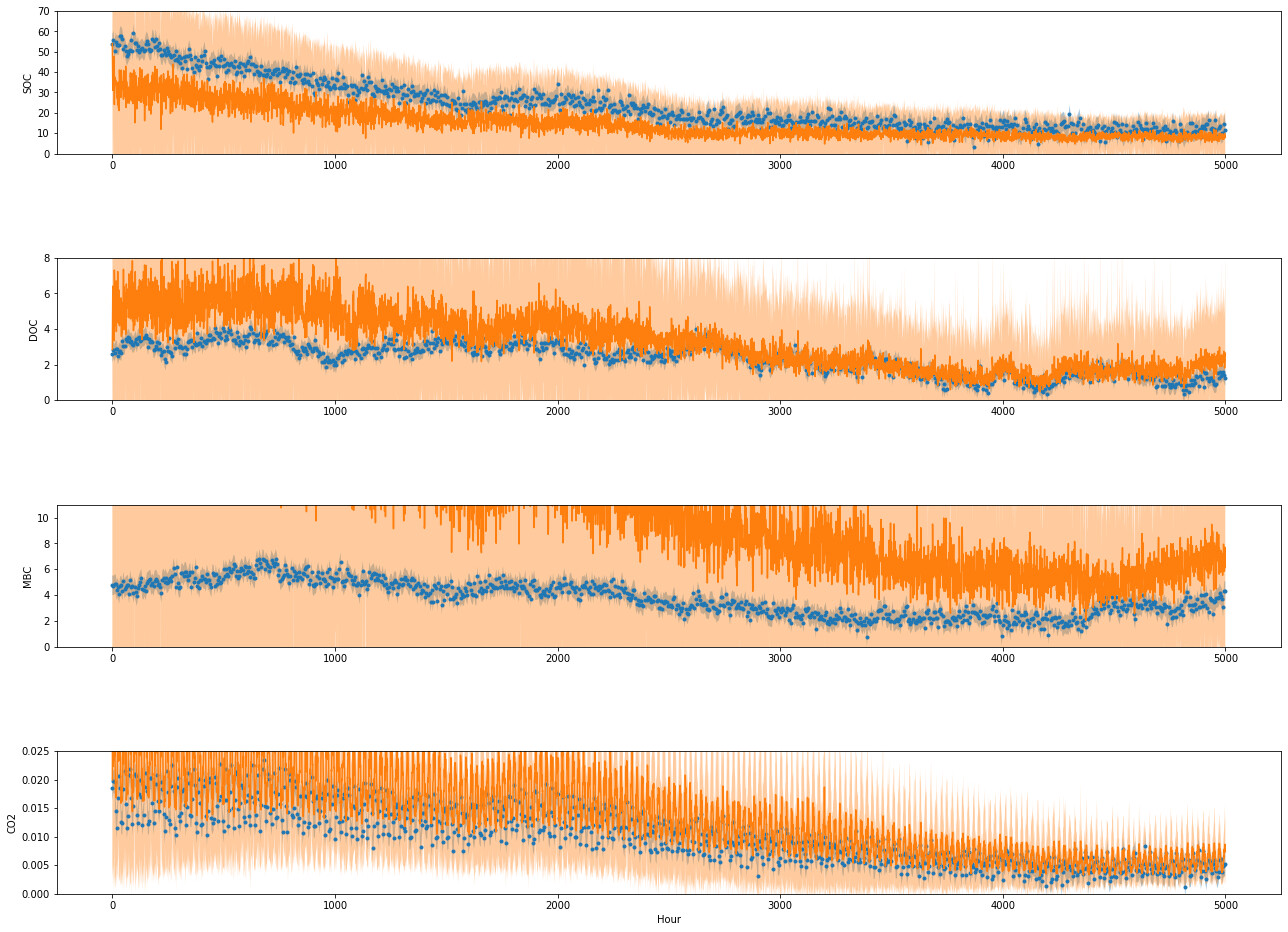
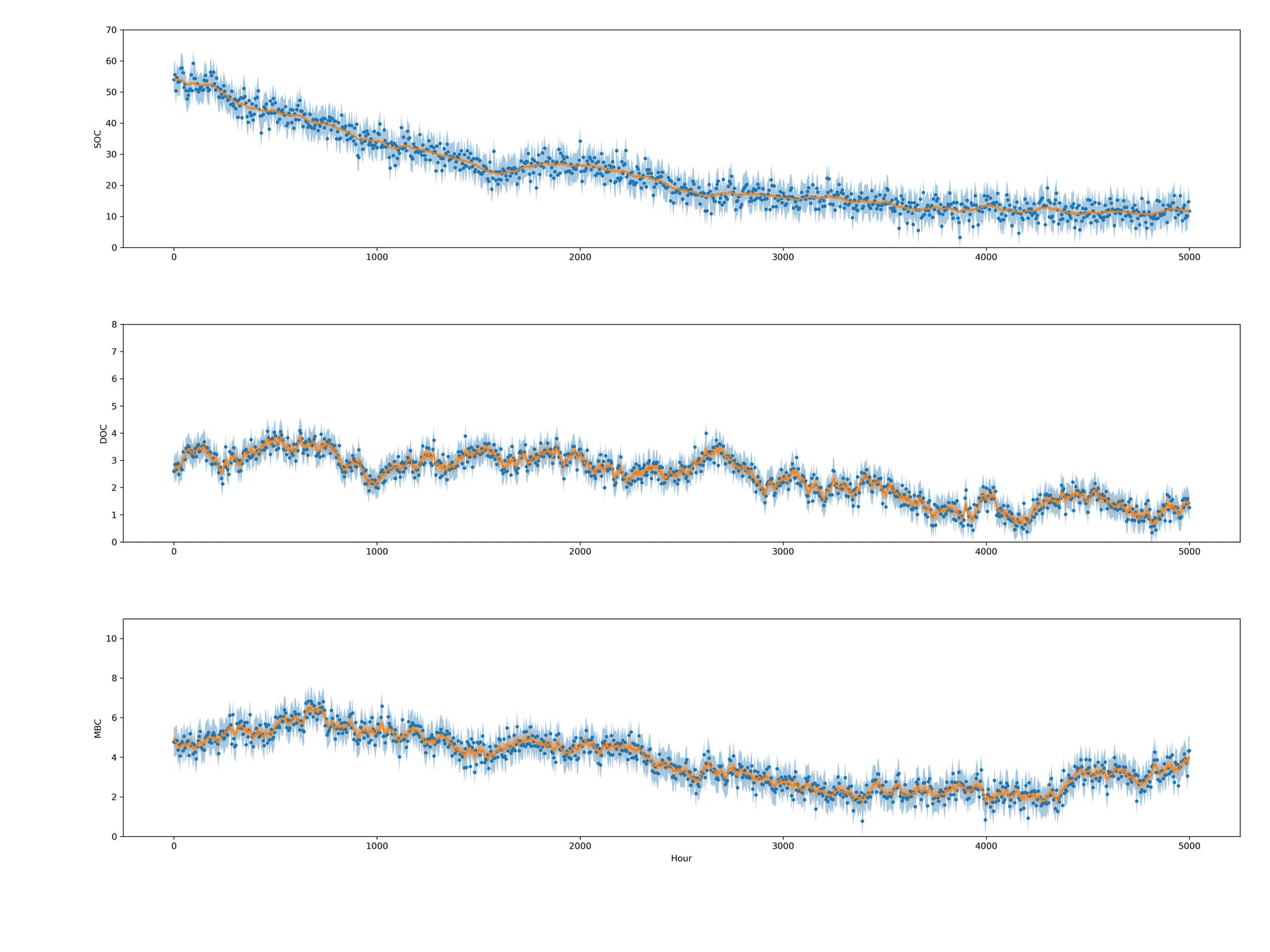
I did get this issue training the GPU model on other data, so random data should also work for replicating this issue, though the number of necessary pieces could make replicating this a pain.
My model classes:
#Torch-related imports
import torch
from torch.autograd import Function
from torch import nn
import torch.distributions as D
import torch.nn.functional as F
import torch.optim as optim
class LowerBound(Function):
@staticmethod
def forward(ctx, inputs, bound):
b = torch.ones(inputs.size()).to(inputs.device) * bound
b = b.type(inputs.dtype)
ctx.save_for_backward(inputs, b)
return torch.max(inputs, b).to(inputs.device)
@staticmethod
def backward(ctx, grad_output):
inputs, b = ctx.saved_tensors
pass_through_1 = inputs >= b
pass_through_2 = grad_output < 0
pass_through = pass_through_1 | pass_through_2
return pass_through.type(grad_output.dtype) * grad_output, None
class MaskedConv1d(nn.Conv1d):
def __init__(self, mask_type, *args, **kwargs):
super(MaskedConv1d, self).__init__(*args, **kwargs)
assert mask_type in {'A', 'B'}
self.register_buffer('mask', self.weight.data.clone())
_, _, kW = self.weight.size() # (out_cha, in_cha, kernel_size)
self.mask.fill_(1)
self.mask[:, :, kW // 2 + 1 * (mask_type == 'B'):] = 0 # [1, 0, 0] or [1, 1, 0]
def forward(self, x):
self.weight.data *= self.mask
return super(MaskedConv1d, self).forward(x)
class ResNetBlock(nn.Module):
def __init__(self, inp_cha, out_cha, stride = 1, first = True, batch_norm = True):
super().__init__()
self.conv1 = MaskedConv1d('A' if first else 'B', inp_cha, out_cha, 3, stride, 1, bias = False)
self.conv2 = MaskedConv1d('B', out_cha, out_cha, 3, 1, 1, bias = False)
self.act1 = nn.PReLU(out_cha, init = 0.2)
self.act2 = nn.PReLU(out_cha, init = 0.2)
if batch_norm:
self.bn1 = nn.BatchNorm1d(out_cha)
self.bn2 = nn.BatchNorm1d(out_cha)
else:
self.bn1 = nn.Identity()
self.bn2 = nn.Identity()
# If dimensions change, transform shortcut with a conv layer
if inp_cha != out_cha or stride > 1:
self.conv_skip = MaskedConv1d('A' if first else 'B', inp_cha, out_cha, 3, stride, 1, bias = False)
else:
self.conv_skip = nn.Identity()
def forward(self, x):
residual = x
x = self.act1(self.bn1(self.conv1(x)))
x = self.act2(self.bn2(self.conv2(x) + self.conv_skip(residual)))
return x
class ResNetBlockUnMasked(nn.Module):
def __init__(self, inp_cha, out_cha, stride = 1, batch_norm = False):
super().__init__()
self.conv1 = nn.Conv1d(inp_cha, out_cha, 3, stride, 1)
self.conv2 = nn.Conv1d(out_cha, out_cha, 3, 1, 1)
#in_channels, out_channels, kernel_size, stride=1, padding=0
self.act1 = nn.PReLU(out_cha, init = 0.2)
self.act2 = nn.PReLU(out_cha, init = 0.2)
if batch_norm:
self.bn1 = nn.BatchNorm1d(out_cha)
self.bn2 = nn.BatchNorm1d(out_cha)
else:
self.bn1 = nn.Identity()
self.bn2 = nn.Identity()
# If dimensions change, transform shortcut with a conv layer
if inp_cha != out_cha or stride > 1:
self.conv_skip = nn.Conv1d(inp_cha, out_cha, 3, stride, 1, bias=False)
else:
self.conv_skip = nn.Identity()
def forward(self, x):
residual = x
x = self.act1(self.bn1(self.conv1(x)))
x = self.act2(self.bn2(self.conv2(x) + self.conv_skip(residual)))
return x
class AffineLayer(nn.Module):
def __init__(self, COND_INPUTS, stride, h_cha = 96):
# COND_INPUTS = COND_INPUTS + obs_dim = 1 + obs_dim = 4 by default (w/o CO2)
super().__init__()
self.feature_net = nn.Sequential(ResNetBlockUnMasked(COND_INPUTS, h_cha), ResNetBlockUnMasked(h_cha, COND_INPUTS))
self.first_block = ResNetBlock(1, h_cha, first = True)
self.second_block = nn.Sequential(ResNetBlock(h_cha + COND_INPUTS, h_cha, first = False), MaskedConv1d('B', h_cha, 2, 3, stride, 1, bias = False))
self.unpack = True if COND_INPUTS > 1 else False
def forward(self, x, COND_INPUTS): # x.shape == (batch_size, 1, n * state_dim)
if self.unpack:
COND_INPUTS = torch.cat([*COND_INPUTS], 1) # (batch_size, obs_dim + 1, n * state_dim)
#print(COND_INPUTS[0, :, 0], COND_INPUTS[0, :, 60], COND_INPUTS[0, :, 65])
COND_INPUTS = self.feature_net(COND_INPUTS) # (batch_size, obs_dim + 1, n * state_dim)
first_block = self.first_block(x) # (batch_size, h_cha, n * state_dim)
#print(first_block.shape, COND_INPUTS.shape)
feature_vec = torch.cat([first_block, COND_INPUTS], 1) # (batch_size, h_cha + obs_dim + 1, n * state_dim)
output = self.second_block(feature_vec) # (batch_size, 2, n * state_dim)
mu, sigma = torch.chunk(output, 2, 1) # (batch_size, 1, n * state_dim)
#print('mu and sigma shapes:', mu.shape, sigma.shape)
sigma = LowerBound.apply(sigma, 1e-8)
x = mu + sigma * x # (batch_size, 1, n * state_dim)
return x, -torch.log(sigma) # each of shape (batch_size, 1, n * state_dim)
class PermutationLayer(nn.Module):
def __init__(self, STATE_DIM, REVERSE = False):
super().__init__()
self.state_dim = STATE_DIM
self.index_1 = torch.randperm(STATE_DIM)
self.reverse = REVERSE
def forward(self, x):
B, S, L = x.shape # (batch_size, 1, state_dim * n)
x_reshape = x.reshape(B, S, -1, self.state_dim) # (batch_size, 1, n, state_dim)
if self.reverse:
x_perm = x_reshape.flip(-2)[:, :, :, self.index_1]
else:
x_perm = x_reshape[:, :, :, self.index_1]
x = x_perm.reshape(B, S, L)
return x
class SoftplusLayer(nn.Module):
def __init__(self):
super().__init__()
self.softplus = nn.Softplus()
def forward(self, x):
# in.shape == out.shape == (batch_size, 1, n * state_dim)
y = self.softplus(x)
return y, -torch.log(-torch.expm1(-y))
class BatchNormLayer(nn.Module):
def __init__(self, num_inputs, momentum = 1e-2, eps = 1e-5, affine = True):
super(BatchNormLayer, self).__init__()
self.log_gamma = nn.Parameter(torch.rand(num_inputs)) if affine else torch.zeros(num_inputs)
self.beta = nn.Parameter(torch.rand(num_inputs)) if affine else torch.zeros(num_inputs)
self.momentum = momentum
self.eps = eps
self.register_buffer('running_mean', torch.zeros(num_inputs))
self.register_buffer('running_var', torch.ones(num_inputs))
def forward(self, inputs):
inputs = inputs.squeeze(1) # (batch_size, n * state_dim)
#print(self.training)
if self.training:
# Compute mean and var across batch
self.batch_mean = inputs.mean(0)
self.batch_var = (inputs - self.batch_mean).pow(2).mean(0) + self.eps
self.running_mean.mul_(self.momentum)
self.running_var.mul_(self.momentum)
self.running_mean.add_(self.batch_mean.data * (1 - self.momentum))
self.running_var.add_(self.batch_var.data * (1 - self.momentum))
mean = self.batch_mean
var = self.batch_var
else:
mean = self.running_mean
var = self.running_var
# mean.shape == var.shape == (n * state_dim, )
x_hat = (inputs - mean) / var.sqrt() # (batch_size, n * state_dim)
#print(mean, var)
#print('x_hat', x_hat)
y = torch.exp(self.log_gamma) * x_hat + self.beta # (batch_size, n * state_dim)
ildj = -self.log_gamma + 0.5 * torch.log(var) # (n * state_dim, )
# y.shape == (batch_size, 1, n * state_dim), ildj.shape == (1, 1, n * state_dim)
return y[:, None, :], ildj[None, None, :]
class SDEFlow(nn.Module):
def __init__(self, DEVICE, OBS_MODEL, STATE_DIM, T, DT, N,
I_S_TENSOR = None, I_D_TENSOR = None, COND_INPUTS = 1, NUM_LAYERS = 5, POSITIVE = True,
REVERSE = False, BASE_STATE = False):
super().__init__()
self.device = DEVICE
self.obs_model = OBS_MODEL
self.state_dim = STATE_DIM
self.t = T
self.dt = DT
self.n = N
self.base_state = BASE_STATE
if self.base_state:
base_loc_SOC, base_loc_DOC, base_loc_MBC = torch.split(nn.Parameter(torch.zeros(1, self.state_dim)), 1, -1)
base_scale_SOC, base_scale_DOC, base_scale_MBC = torch.split(nn.Parameter(torch.ones(1, self.state_dim)), 1, -1)
base_loc = torch.cat((base_loc_SOC.expand([1, self.n]), base_loc_DOC.expand([1, self.n]), base_loc_MBC.expand([1, self.n])), 1)
base_scale = torch.cat((base_scale_SOC.expand([1, self.n]), base_scale_DOC.expand([1, self.n]), base_scale_MBC.expand([1, self.n])), 1)
self.base_dist = D.normal.Normal(loc = base_loc, scale = base_scale)
else:
self.base_dist = D.normal.Normal(loc = 0., scale = 1.)
self.cond_inputs = COND_INPUTS
if self.cond_inputs == 3:
self.i_tensor = torch.stack((I_S_TENSOR.reshape(-1), I_D_TENSOR.reshape(-1)))[None, :, :].repeat_interleave(3, -1)
self.num_layers = NUM_LAYERS
self.reverse = REVERSE
self.affine = nn.ModuleList([AffineLayer(COND_INPUTS + self.obs_model.obs_dim, 1) for _ in range(NUM_LAYERS)])
self.permutation = [PermutationLayer(STATE_DIM, REVERSE = self.reverse) for _ in range(NUM_LAYERS)]
self.batch_norm = nn.ModuleList([BatchNormLayer(STATE_DIM * N) for _ in range(NUM_LAYERS - 1)])
self.positive = POSITIVE
if self.positive:
self.SP = SoftplusLayer()
def forward(self, BATCH_SIZE, *args, **kwargs):
if self.base_state:
eps = self.base_dist.rsample([BATCH_SIZE]).to(self.device)
else:
eps = self.base_dist.rsample([BATCH_SIZE, 1, self.state_dim * self.n]).to(self.device)
log_prob = self.base_dist.log_prob(eps).sum(-1) # (batch_size, 1)
# NOTE: This currently assumes a regular time gap between observations!
steps_bw_obs = self.obs_model.idx[1] - self.obs_model.idx[0]
reps = torch.ones(len(self.obs_model.idx), dtype=torch.long).to(self.device) * self.state_dim
reps[1:] *= steps_bw_obs
obs_tile = self.obs_model.mu[None, :, :].repeat_interleave(reps, -1).repeat( \
BATCH_SIZE, 1, 1).to(self.device) # (batch_size, obs_dim, state_dim * n)
times = torch.arange(0, self.t + self.dt, self.dt, device = eps.device)[None, None, :].repeat( \
BATCH_SIZE, self.state_dim, 1).transpose(-2, -1).reshape(BATCH_SIZE, 1, -1).to(self.device)
if self.cond_inputs == 3:
i_tensor = self.i_tensor.repeat(BATCH_SIZE, 1, 1)
features = (obs_tile, times, i_tensor)
else:
features = (obs_tile, times)
#print(obs_tile)
ildjs = []
for i in range(self.num_layers):
eps, cl_ildj = self.affine[i](self.permutation[i](eps), features) # (batch_size, 1, n * state_dim)
#print('Coupling layer {}'.format(i), eps, cl_ildj)
if i < (self.num_layers - 1):
eps, bn_ildj = self.batch_norm[i](eps) # (batch_size, 1, n * state_dim), (1, 1, n * state_dim)
ildjs.append(bn_ildj)
#print('BatchNorm layer {}'.format(i), eps, bn_ildj)
ildjs.append(cl_ildj)
if self.positive:
eps, sp_ildj = self.SP(eps) # (batch_size, 1, n * state_dim)
ildjs.append(sp_ildj)
#print('Softplus layer', eps, sp_ildj)
eps = eps.reshape(BATCH_SIZE, -1, self.state_dim) + 1e-6 # (batch_size, n, state_dim)
for ildj in ildjs:
log_prob += ildj.sum(-1) # (batch_size, 1)
#return eps.reshape(BATCH_SIZE, self.state_dim, -1).permute(0, 2, 1) + 1e-6, log_prob
return eps, log_prob # (batch_size, n, state_dim), (batch_size, 1)
class ObsModel(nn.Module):
def __init__(self, DEVICE, TIMES, DT, MU, SCALE):
super().__init__()
self.times = TIMES # (n_obs, )
self.dt = DT
self.idx = self.get_idx(TIMES, DT)
self.mu = torch.Tensor(MU).to(DEVICE) # (obs_dim, n_obs)
self.scale = torch.Tensor(SCALE).to(DEVICE) # (1, obs_dim)
self.obs_dim = self.mu.shape[0]
def forward(self, x):
obs_ll = D.normal.Normal(self.mu.permute(1, 0), self.scale).log_prob(x[:, self.idx, :])
return torch.sum(obs_ll, [-1, -2]).mean()
def get_idx(self, TIMES, DT):
return list((TIMES / DT).astype(int))
def plt_dat(self):
return self.mu, self.times
Before instantiating the net, we need to have an observation and state dimension in mind. We’ll go with 3. So, an observation model needs to be instantiated with:
import numpy as np #Data I was working with was in Numpy array format.
device = torch.device('cpu')
obs_means = np.random.rand(3, 101)
obs_times = np.arange(0, 101)
obs_error = 0.1 * obs_means
dt = 1.
obs_model = ObsModel(DEVICE = device, TIMES = obs_times, DT = dt, MU = obs_means, SCALE = obs_error).to(device)
Then, we can instantiate the net with
t = 100
n = int(t / dt) + 1
net = SDEFlow(device, obs_model, 3, t, dt, n, NUM_LAYERS = 1, REVERSE = True, BASE_STATE = False).to(device)
Then, you can train with something along the lines of
iterations = 1000
training_batch_size = 20
loss_opt = optim.Adam(net.parameters(), lr = 1e-3)
loss = 1e20
for i in range(iterations):
loss_opt.zero_grad()
x, log_prob = net(training_batch_size)
loss = log_prob.mean() - obs_model(x)
loss.backward()
and then the requisite net saving and loading thereafter to plot on CPU.
By the way, I have noticed that I have not managed to get the CPU loading working with net.eval() turned on, so that’s probably a sign that there’s still something wrong.