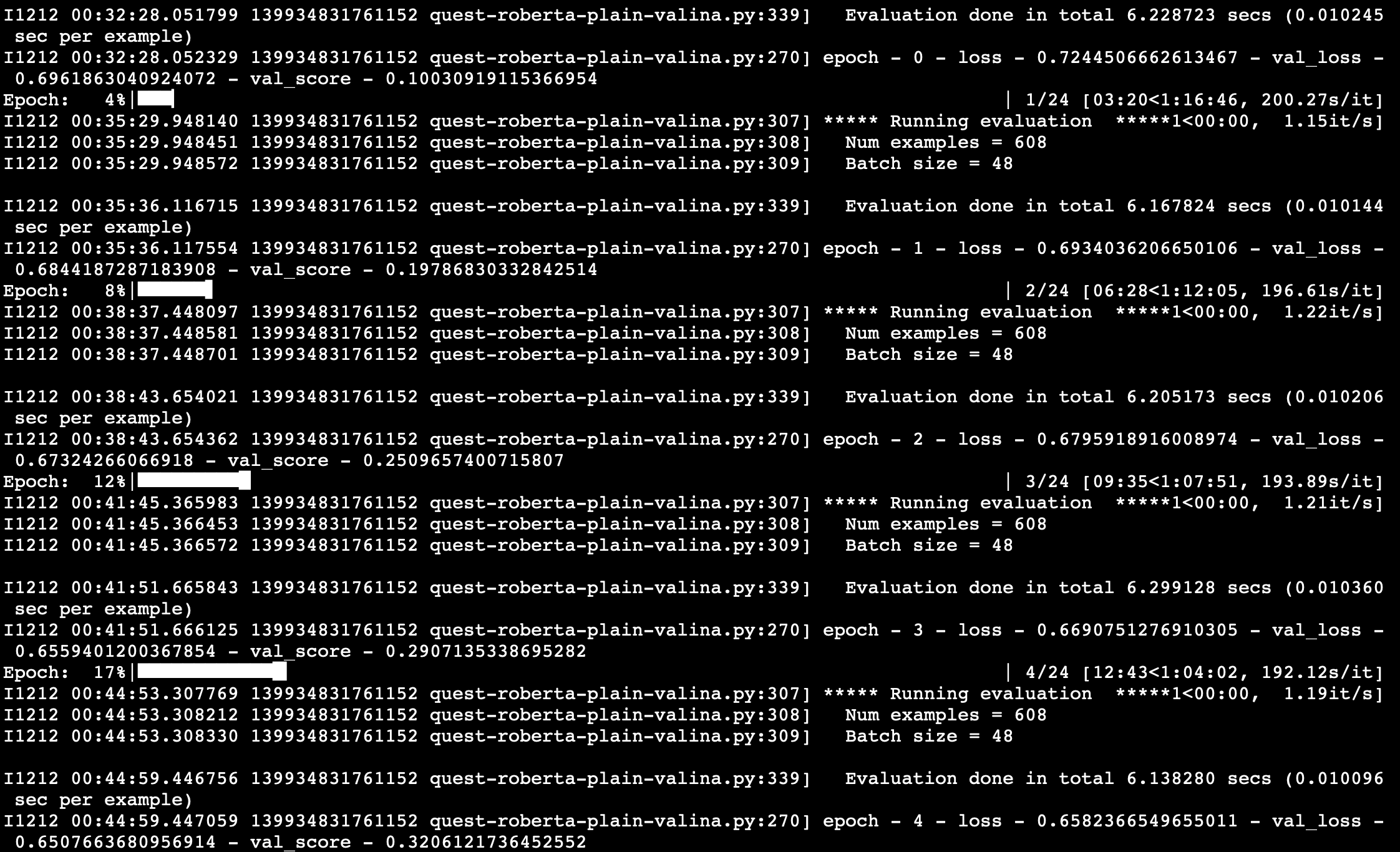
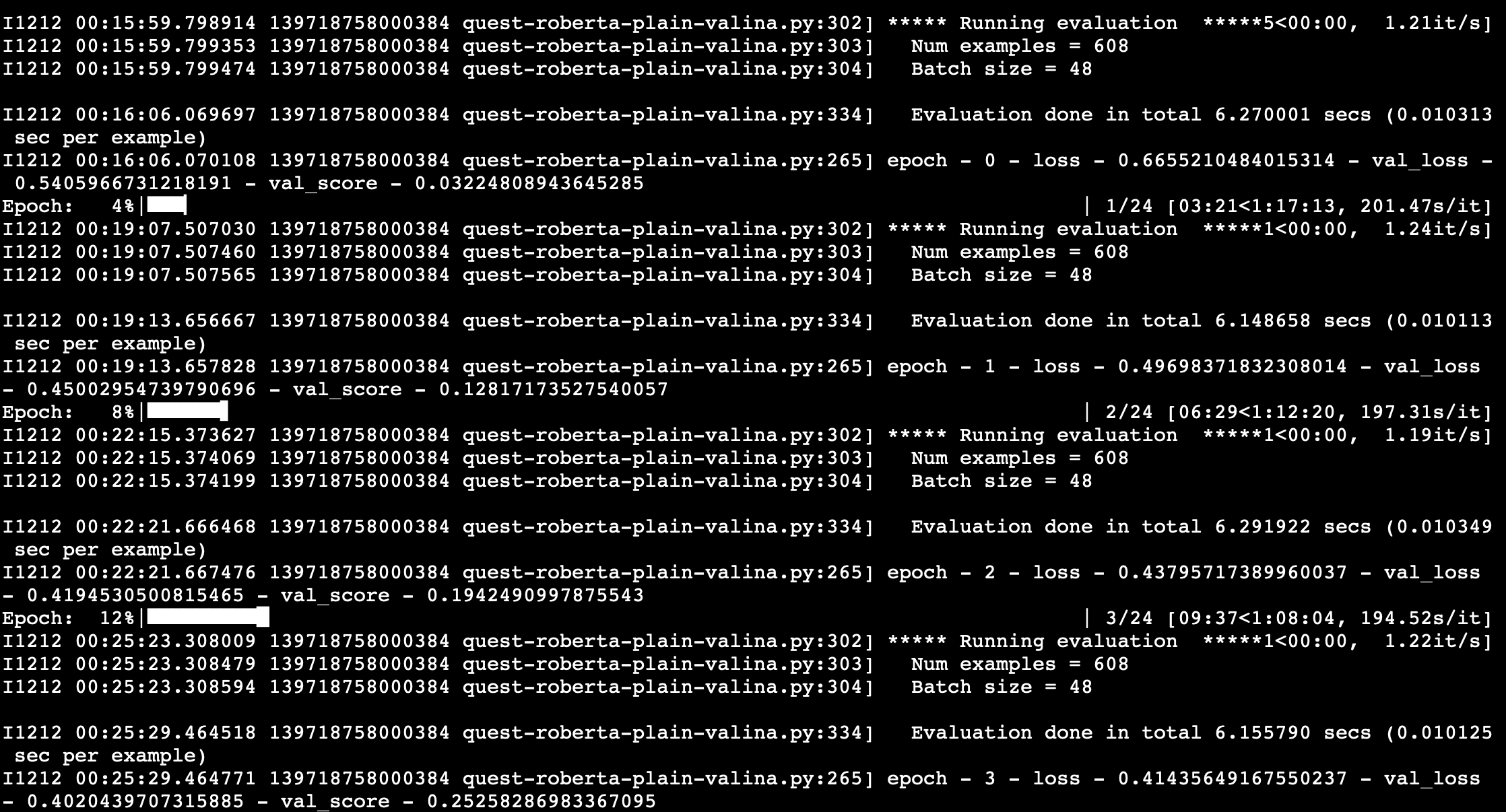
Is just the initial loss higher?
How does the training look like? Are you able to get the same or lower loss with the batchnorm layer or does it stay at a higher level constantly?
While the training loss seems to be higher, the validation score seems to be better in the batchnorm model.
In that case, I would stick to it and maybe play around with some hyperparameters.