Here’s a look at the LSTM model
# Create LSTM Model
class LSTMModel(nn.Module):
def __init__(self, input_dim, hidden_dim, layer_dim, output_dim):
super(LSTMModel, self).__init__()
# Number of hidden dimensions
self.hidden_dim = hidden_dim
# Number of hidden layers
self.layer_dim = layer_dim
# LSTM
self.lstm = nn.LSTM(input_dim, hidden_dim, layer_dim, batch_first=True, dropout=0.1)
# Readout layer
self.f1 = nn.Linear(hidden_dim, output_dim)
self.dropout_layer = nn.Dropout(p=0.2)
self.softmax = nn.Softmax()
def forward(self, x):
# Initialize hidden state with zeros
h0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).type(torch.FloatTensor))
# Initialize cell state
c0 = Variable(torch.zeros(self.layer_dim, x.size(0), self.hidden_dim).type(torch.FloatTensor))
# One time step
out, (hn, cn) = self.lstm(x, (h0,c0))
out = self.dropout_layer(hn[-1])
out = self.f1(out)
out = self.softmax(out)
return out
#LSTM Configuration
batch_size = 3000
num_epochs = 20
learning_rate = 0.001#Check this learning rate
# Create LSTM
input_dim = 1 # input dimension
hidden_dim = 30 # hidden layer dimension
layer_dim = 15 # number of hidden layers
output_dim = 1 # output dimension
num_layers = 10 #num_layers
print("input_dim = ", input_dim,"\nhidden_dim = ", hidden_dim,"\nlayer_dim = ", layer_dim,"\noutput_dim = ", output_dim)
model = LSTMModel(input_dim, hidden_dim, layer_dim, output_dim)
model.cuda()
error = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
graph_index = 0
test_loss = []
train_loss = []
plt_test_index = []
plt_train_index = []
tmp_index = []
tmp_train = []
tmp_test = []
# model.init_hidden()
for epoch in range(num_epochs):
# Train
model.train()
loss_list_train = []
loss_list_test = []
total_train = 0
equals_train = 0
total_test = 0
num0_train = 0
num1_train = 0
num0_test = 0
num1_test = 0
equals_test = 0
TP_train = 0
FP_train = 0
TN_train = 0
FN_train = 0
TP_test = 0
FP_test = 0
TN_test = 0
FN_test = 0
# for i, (inputs, targets) in enumerate(train_loader):
for i, (inputs, targets) in enumerate(train_loader):
train = Variable(inputs.type(torch.FloatTensor).cuda())
targets = Variable(targets.type(torch.FloatTensor).cuda())
optimizer.zero_grad()
outputs = model(train)
loss = error(outputs, targets)
loss_list_train.append(loss.item())
loss.backward()
# loss.backward(retain_graph=True)
optimizer.step()
t = np.where(targets.cpu().detach().numpy() > 0.5, 1, 0)
o = np.where(outputs.cpu().detach().numpy() > 0.5, 1, 0)
total_train += t.shape[0]
equals_train += np.sum(t == o)
num0_train += np.sum(t == 0)
num1_train += np.sum(t == 1)
TP_train += np.sum(np.logical_and(t == 1, o==1))
FP_train += np.sum(np.logical_and(t == 1, o==0))
TN_train += np.sum(np.logical_and(t == 0, o==0))
FN_train += np.sum(np.logical_and(t == 0, o==1))
tb.save_value('Train Loss', 'train_loss', globaliter, loss.item())
globaliter += 1
tb.flush_line('train_loss')
print(i)
# Test
model.eval()
targets_plot = np.array([])
outputs_plot = np.array([])
inputs_plot = np.array([])
for inputs, targets in test_loader:
inputs = Variable(inputs.type(torch.FloatTensor).cuda())
targets = Variable(targets.type(torch.FloatTensor).cuda())
outputs = model(inputs)
loss = error(outputs, targets)
loss_list_test.append(loss.item())
#print(outputs.cpu().detach().numpy())
t = np.where(targets.cpu().detach().numpy() > 0.5, 1, 0)
o = np.where(outputs.cpu().detach().numpy() > 0.5, 1, 0)
total_test += t.shape[0]
equals_test += np.sum(t == o)
num0_test += np.sum(t == 0)
num1_test += np.sum(t == 1)
TP_test += np.sum(np.logical_and(t == 1, o==1))
FP_test += np.sum(np.logical_and(t == 0, o==1))
TN_test += np.sum(np.logical_and(t == 0, o==0))
FN_test += np.sum(np.logical_and(t == 1, o==0))
tb.save_value('Test Loss', 'test_loss', globaliter2, loss.item())
globaliter2 += 1
tb.flush_line('test_loss')
# Save value in array
graph_index += 1
plt_train_index.append(graph_index)
plt_test_index.append(graph_index)
train_loss.append(np.mean(np.array(loss_list_train)))
test_loss.append(np.mean(np.array(loss_list_test)))
print("------------------------------")
print("Epoch : ", epoch)
print("----- Train -----")
print("Total =", total_train, " | Num 0 =", num0_train, " | Num 1 =", num1_train)
print("Equals =", equals_train)
print("Accuracy =", (equals_train / total_train)*100, "%")
# print("TP =", TP_train / total_train, "% | TN =", TN_train / total_train, "% | FP =", FP_train / total_train, "% | FN =", FN_train / total_train, "%")
print("----- Test -----")
print("Total =", total_test, " | Num 0 =", num0_test, " | Num 1 =", num1_test)
print("Equals =", equals_test)
print("Accuracy =", (equals_test / total_test)*100, "%")
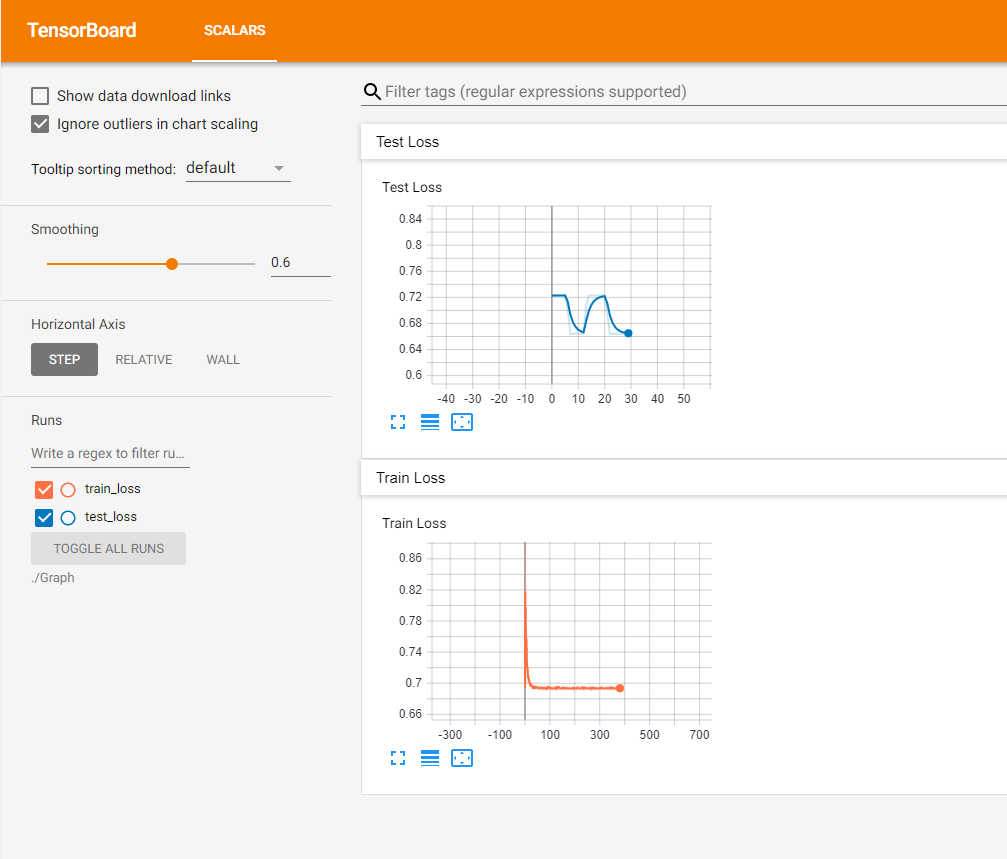
I am using the model to do binary classification on the sequence length of 300. The accuracy and the loss are not changing over several epochs.I tried changing the no. of layers,no of hidden states, activation function, but all to no avail. I don’t know what i am doing wrong, I am probably missing something fundamental. Any help is appreciated