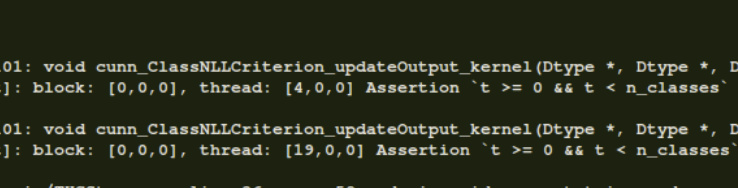
Hello again,
I am not sure why this is happening. The only thing that is maybe unusual about my code is that I am training a RNN by feeding its o/p as i/p to the next time-step (after passing it thru a FC layer). Any advice would be greatly appreciated.
I am attaching a screenshot of the error (pls ignore the image on the right)
Here is my forward pass:
def forward(self,frames,actions,nsteps):
104
105 frame_emb = self.encoder(frames)
106 #project for action conditioning
107 frame_embs = self.encoder_linear(frame_emb)
108
109 action_emb = self.action_linear(actions.view(-1,6))
110 action_emb = action_emb.view(-1,nsteps,2048)
111
112 #initial hidden state
113 h0 = Variable(torch.zeros(1, 16, 512).cuda())
114 c0 = Variable(torch.zeros(1, 16, 512).cuda())
115 hidden = (h0,c0)
116
117 outputs = Variable(torch.zeros((16,nsteps,84,84))).cuda()
118 rewards = Variable(torch.zeros((16,nsteps,3))).cuda()
119
120 for step in range(nsteps):
121 rnn_input = self.decoder_linear((frame_embs*action_emb[:,step,:])) + self.bias
122 rnn_input = rnn_input.unsqueeze(1)
123 ActCondEmb,hidden = self.rnn(rnn_input,hidden)
124
125 ActEmb = ActCondEmb.contiguous().view(-1,ActCondEmb.size(-1))
126 dec_emb = self.decoder_proj(ActEmb)
127 #part of input for next time step
128 frame_embs = self.encoder_linear(dec_emb)
129 #model predictions
130 output = self.decoder(dec_emb)
131 outputs[:,step,:,:] = output
132 reward_predictions = self.reward_linear(dec_emb)
133 rewards[:,step,:] = reward_predictions
134
135 return outputs, rewards