Hi,
this is the Unet structure I adopted, the forward prop works fine though,
def pad_concat(t1, t2):
"""Concat the activations of two layer channel-wise by padding the layer
with fewer points with zeros.
Args:
t1 (tensor): Activations from first layers of shape `(batch, c1, n1, m1)`.
t2 (tensor): Activations from second layers of shape `(batch,c2, n2, m2)`.
Returns:
tensor: Concatenated activations of both layers of shape
`(batch, c1 + c2, max(n1, n2), max(m1, m2))`.
"""
if t1.shape[2] > t2.shape[2]:
padding = t1.shape[2] - t2.shape[2]
if padding % 2 == 0: # Even difference
t2 = F.pad(t2, (0, 0, int(padding / 2), int(padding / 2)), 'reflect').contiguous()
else: # Odd difference
t2 = F.pad(t2, (0, 0, int((padding - 1) / 2), int((padding + 1) / 2)),
'reflect').contiguous()
elif t2.shape[2] > t1.shape[2]:
padding = t2.shape[2] - t1.shape[2]
if padding % 2 == 0: # Even difference
t1 = F.pad(t1, (0, 0, int(padding / 2), int(padding / 2)), 'reflect').contiguous()
else: # Odd difference
t1 = F.pad(t1, (0, 0, int((padding - 1) / 2), int((padding + 1) / 2)),
'reflect').contiguous()
# another dimension
if t1.shape[3] > t2.shape[3]:
padding = t1.shape[3] - t2.shape[3]
if padding % 2 == 0: # Even difference
t2 = F.pad(t2, (int(padding / 2), int(padding / 2), 0, 0), 'reflect').contiguous()
else: # Odd difference
t2 = F.pad(t2, (int((padding - 1) / 2), int((padding + 1) / 2), 0, 0),
'reflect').contiguous()
elif t2.shape[3] > t1.shape[3]:
padding = t2.shape[3] - t1.shape[3]
if padding % 2 == 0: # Even difference
t1 = F.pad(t1, (int(padding / 2), int(padding / 2), 0, 0), 'reflect').contiguous()
else: # Odd difference
t1 = F.pad(t1, (int((padding - 1) / 2), int((padding + 1) / 2), 0, 0),
'reflect').contiguous()
return torch.cat([t1, t2], dim=1)
class UNet(nn.Module):
"""Large convolutional architecture from 1d experiments in the paper.
This is a 12-layer residual network with skip connections implemented by
concatenation.
Args:
in_channels (int, optional): Number of channels on the input to
network. Defaults to 8.
"""
def __init__(self, in_channels=8):
super(UNet, self).__init__()
self.activation = nn.ReLU()
self.in_channels = in_channels
self.out_channels = 16
self.num_halving_layers = 6
self.l1 = nn.Conv2d(in_channels=self.in_channels,
out_channels=self.in_channels,
kernel_size=5, stride=2, padding=2)
self.l2 = nn.Conv2d(in_channels=self.in_channels,
out_channels=2 * self.in_channels,
kernel_size=5, stride=2, padding=2)
self.l3 = nn.Conv2d(in_channels=2 * self.in_channels,
out_channels=2 * self.in_channels,
kernel_size=5, stride=2, padding=2)
self.l4 = nn.Conv2d(in_channels=2 * self.in_channels,
out_channels=4 * self.in_channels,
kernel_size=5, stride=2, padding=2)
self.l5 = nn.Conv2d(in_channels=4 * self.in_channels,
out_channels=8 * self.in_channels,
kernel_size=5, stride=2, padding=2)
for layer in [self.l1, self.l2, self.l3, self.l4, self.l5]:
init_layer_weights(layer)
self.l6 = nn.ConvTranspose2d(in_channels=8 * self.in_channels,
out_channels=4 * self.in_channels,
kernel_size=5, stride=2, padding=2,
output_padding=1)
self.l7 = nn.ConvTranspose2d(in_channels=8 * self.in_channels,
out_channels=2 * self.in_channels,
kernel_size=5, stride=2, padding=2,
output_padding=1)
self.l8 = nn.ConvTranspose2d(in_channels=4 * self.in_channels,
out_channels=2 * self.in_channels,
kernel_size=5, stride=2, padding=2,
output_padding=1)
self.l9 = nn.ConvTranspose2d(in_channels=4 * self.in_channels,
out_channels=self.in_channels,
kernel_size=5, stride=2, padding=2,
output_padding=1)
self.l10 = nn.ConvTranspose2d(in_channels=2 * self.in_channels,
out_channels=self.in_channels,
kernel_size=5, stride=2, padding=2,
output_padding=1)
for layer in [self.l6, self.l7, self.l8, self.l9, self.l10]:
init_layer_weights(layer)
def forward(self, x):
"""Forward pass through the convolutional structure.
Args:
x (tensor): Inputs of shape `(batch, n_in, in_channels)`.
Returns:
tensor: Outputs of shape `(batch, n_out, out_channels)`.
"""
h1 = self.activation(self.l1(x))
self.print_conv_info(x, self.l1)
h2 = self.activation(self.l2(h1))
self.print_conv_info(h1, self.l2)
h3 = self.activation(self.l3(h2))
self.print_conv_info(h2, self.l3)
h4 = self.activation(self.l4(h3))
self.print_conv_info(h3, self.l4)
h5 = self.activation(self.l5(h4))
self.print_conv_info(h4, self.l5)
h6 = self.activation(self.l6(h5))
self.print_conv_info(h5, self.l6)
h6 = pad_concat(h4, h6)
h7 = self.activation(self.l7(h6))
self.print_conv_info(h6, self.l7)
h7 = pad_concat(h3, h7)
h8 = self.activation(self.l8(h7))
self.print_conv_info(h7, self.l8)
h8 = pad_concat(h2, h8)
h9 = self.activation(self.l9(h8))
self.print_conv_info(h8, self.l9)
h9 = pad_concat(h1, h9)
h10 = self.activation(self.l10(h9))
self.print_conv_info(h9, self.l10)
output = pad_concat(x, h10)
return output
def print_conv_info(self, input, layer):
print("Info for %s."%layer)
print("stride:", layer.stride)
print("input size: ", input.size())
print("input offset: ", input.storage_offset())
print("input device: ", input.device)
print("input layout:", input.layout)
and the results are the followings. hope it’s not too complicated
Info for Conv2d(8, 8, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)).
stride: (2, 2)
input size: torch.Size([64, 8, 192, 63])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for Conv2d(8, 16, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)).
stride: (2, 2)
input size: torch.Size([64, 8, 96, 32])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for Conv2d(16, 16, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)).
stride: (2, 2)
input size: torch.Size([64, 16, 48, 16])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for Conv2d(16, 32, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)).
stride: (2, 2)
input size: torch.Size([64, 16, 24, 8])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for Conv2d(32, 64, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2)).
stride: (2, 2)
input size: torch.Size([64, 32, 12, 4])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for ConvTranspose2d(64, 32, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), output_padding=(1, 1)).
stride: (2, 2)
input size: torch.Size([64, 64, 6, 2])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for ConvTranspose2d(64, 16, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), output_padding=(1, 1)).
stride: (2, 2)
input size: torch.Size([64, 64, 12, 4])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for ConvTranspose2d(32, 16, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), output_padding=(1, 1)).
stride: (2, 2)
input size: torch.Size([64, 32, 24, 8])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for ConvTranspose2d(32, 8, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), output_padding=(1, 1)).
stride: (2, 2)
input size: torch.Size([64, 32, 48, 16])
input offset: 0
input device: cuda:7
input layout: torch.strided
Info for ConvTranspose2d(16, 8, kernel_size=(5, 5), stride=(2, 2), padding=(2, 2), output_padding=(1, 1)).
stride: (2, 2)
input size: torch.Size([64, 16, 96, 32])
input offset: 0
input device: cuda:7
input layout: torch.strided
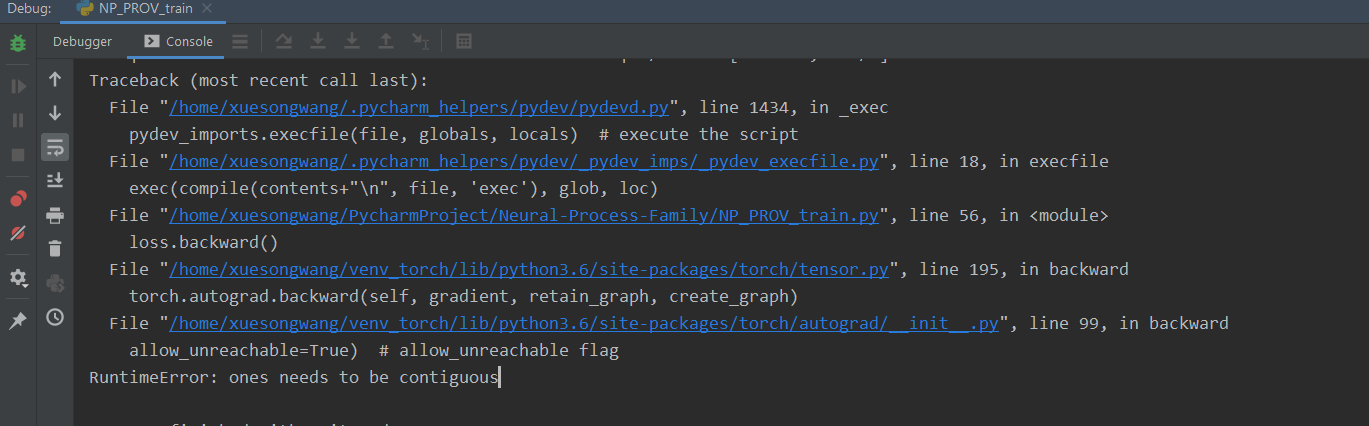
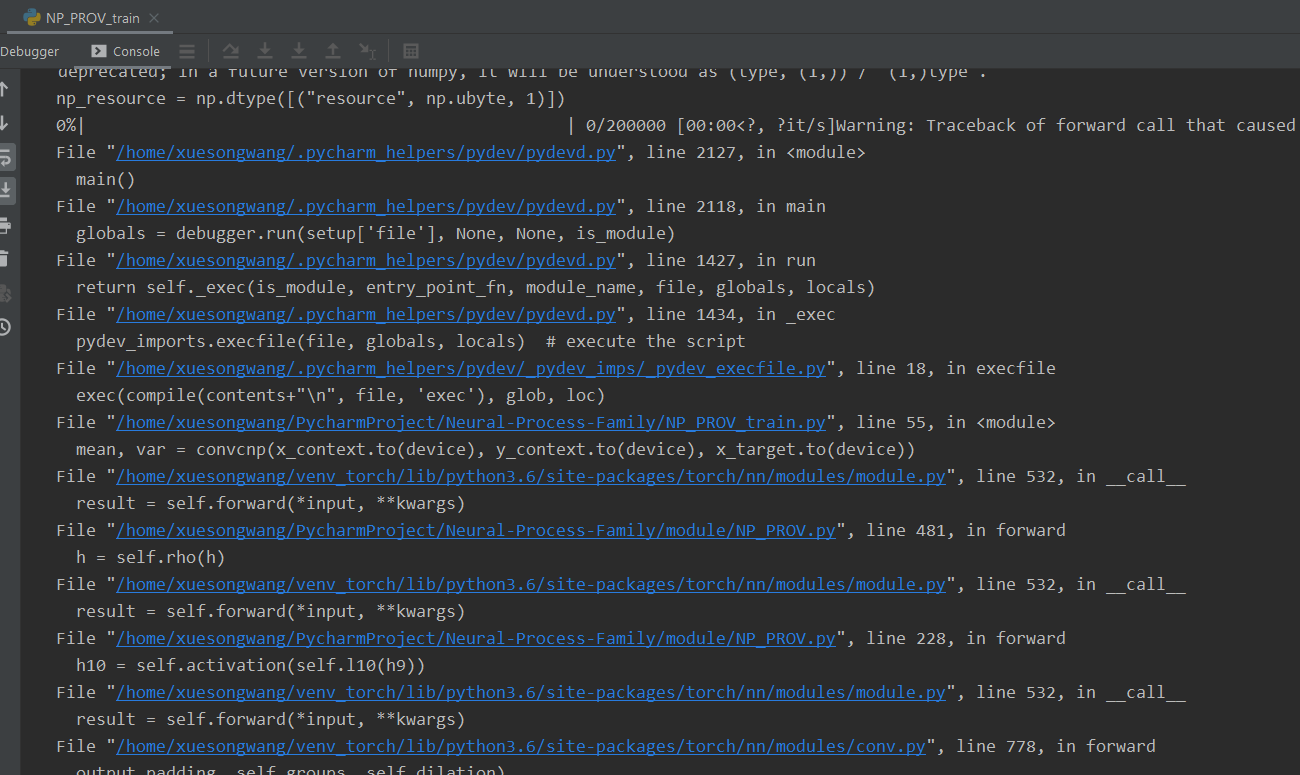
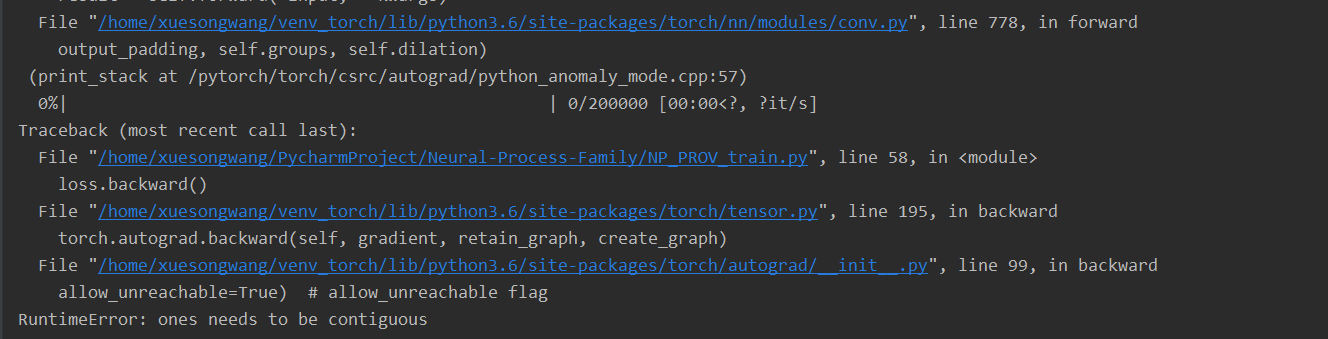
 I have made sure that only concatenation is called without padding in the pad_concat function, and directly output h10 without concatenating with x to avoid size mismatching.
I have made sure that only concatenation is called without padding in the pad_concat function, and directly output h10 without concatenating with x to avoid size mismatching. This is what makes a Tensor “non-contiguous” that’s why it is important.
This is what makes a Tensor “non-contiguous” that’s why it is important.